

作者简介
姜传伟,携程机票高级软件工程师。机票前台服务端搬砖工,负责机票前台服务端基础框架。
一、背景
随着业务和技术的推进,在早期野蛮生长后,公司逐渐开始注重质量发展。
测试方面,为了满足需求的快速迭代上线,之前机票整个前台采用了Scrum敏捷开发流程,测试流程往往是人工进行。而随着业务增长,每次发布需要覆盖的Case越来越多,这时对所有Case都进行回归显然不太现实,人工测试也往往不能完全避免出现问题。
发布Case回归,除了本次发布的需求,其它Case的验证往往是重复的。因此我们开始加大自动化测试的比例,减少人工介入,以此来降低开发成本,提升发布质量。
二、简介
在开发流程中,我们逐渐引入了持续集成流程,整个流程包括单元测试,流量回放,Case验证等等。
其中流量回放流程,要想达到模拟线上真实的请求结果,需要借助Mock系统和数据量比较大的线上日志来完成。将接口,Abtest结果等第三方依赖结果Mock掉,尽量和线上的真实流程保持一致。
其中重要的一步是拉取线上日志用来做Mock使用,这关系到覆盖线上场景的多少,以及持续集成的有效性和可靠性。
这部分日志往往数量庞大,仅机票前台每天产生的日志就在1T-2T之间。出于数据安全的考虑,服务的各个环境做了隔离,这也使得拉取日志的成本较高。
之前的方案定时拉取日志,然后将其存储在redis进行缓存,每次进行拉取,进行日志数据准备往往需要半天的时间,成为持续集成的一个瓶颈。
三、场景回放
场景回放的目的在于覆盖线上业务场景,携程作为国内最大的OTA,需要对接众多的国内和国际航司,大多数航司为了提升自家的票量,往往有着许多不同的需求,这也提升了我们业务的复杂度。
现在的方案是需要开发将用户预定流程经过的场景,通过埋点的方式将业务的场景埋到日志,存储到日志系统中,之后通过这些Case的埋点,来获取特定的日志报文。通过Mock系统,将Soa接口和Ab等第三 方依赖Mock掉,使用线上的日志来重新发请求,通过比对线上返回报文和回放的返回报文的方式来进行线上的场景回放和验证,来达到覆盖线上业务场景的目的。
四、改造方案
新的方案采取Flink直接接收Kafka数据,对实时的数据进行预处理,在用户的每次请求中,都会生成一个唯一的ID,把依赖的SOA接口通过ID进行了埋点和串联。
我们可以根据ID将主服务的日志和SOA的日志进行分组,聚合出一次请求的日志和依赖日志。并根据业务上的埋点,进行真实业务场景的换算,将场景换算成关键字,写入到Es中,利用Es中Lucence的分词和倒排索引进行检索,以提高查询效率。
方案设计之初我们提供了备用方案,如果Es不能满足预期,也可以对场景的日志自己维护一套索引,来达到快速检索的目的。
从目前的使用效果来看,Es基本可满足需求。 在业务上的场景埋点字段类似于 A|B|C|D|E这种,每个数字分别代表不同的场景含义,并且有可能是使用位操作来表示或者是一个特定的量词。
对场景埋点的处理,是将字段中每个数字的含义进行拆分,比如数字A每个位代表不同的含义,处理后的结果就为ct_0=[A1];[A2];[A3],0代表埋点中的位置,A1,A2为具体的场景(举例如下),由于标点符号为天然的分隔符,可以利用这一点来进行分词,构建索引。
处理前CaseTag:
"CaseTag": "11|0|0|0|1|3|1",处理后CaseTag:
"c_cus_ct_0": "[1];[2];[8];[11];","c_cus_ct_1": "[0];","c_cus_ct_2": "[0];","c_cus_ct_3": "[0];","c_cus_ct_4": "[1];[1];","c_cus_ct_5": "[1];[2];[3];","c_cus_ct_6": "[1];[1];",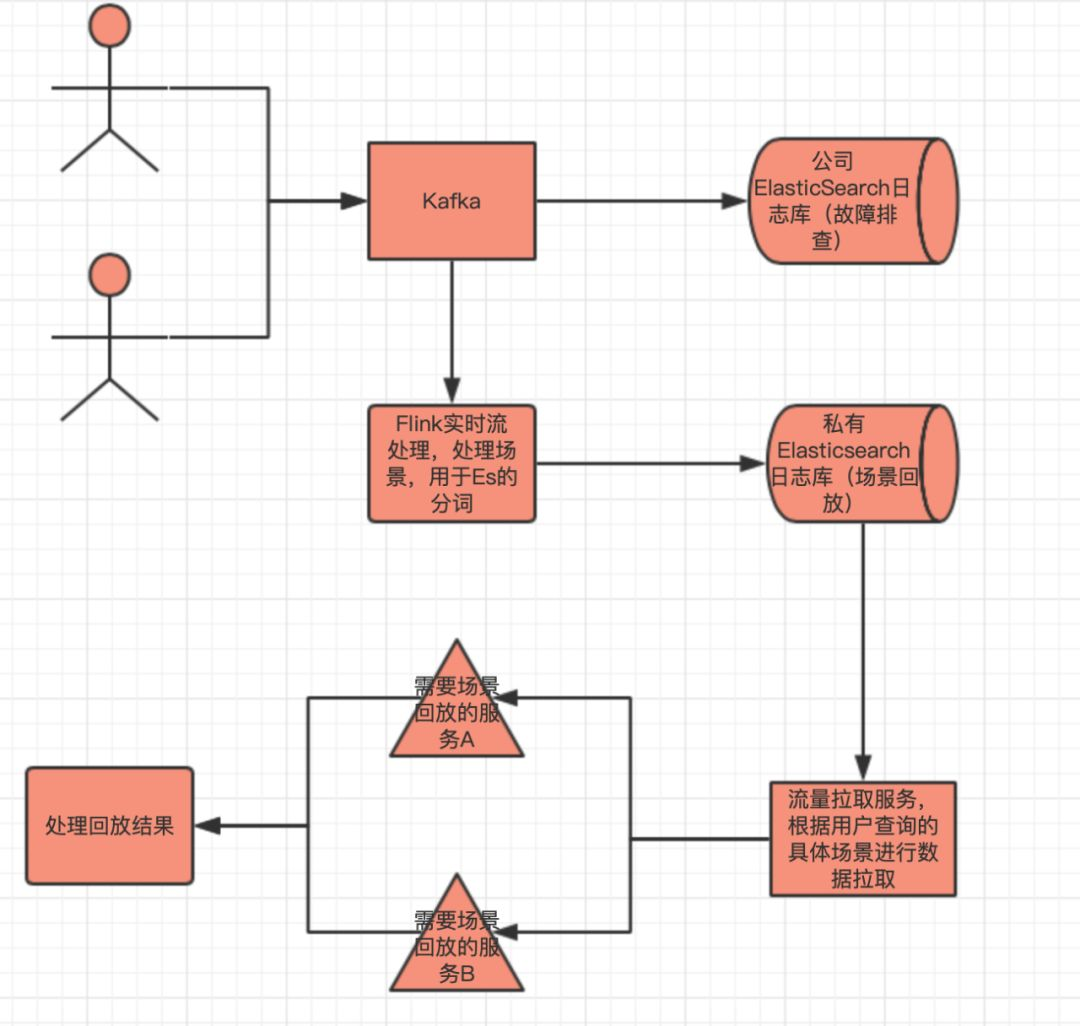
五、采取新方案后的效果
我们的日常发布一般是在晚上生产流量比较低的时候进行。之前进行流量回放,往往需要从早上开始准备,进行日志拉取,整个流程大致要4个小时以上(画外音:我的青春,我的泪)。
使用新方案后,我们的场景就可以使用索引来提高检索速度,这样每个场景的日志拉取可以做到在秒级返回,近乎实时的日志获取,大大提高了流量回放的效率。
六、使用Flink和Es需要注意的地方
在Flink的使用过程中有几个地方需要注意,我们使用的是Flink的StreamApi,尽管Flink有内存溢出机制,但是实际使用过程中,由于每天产生的日志数据量在1T-2T,即使是按照每10分钟,还是会有好几G的数据。另外我们会需要SubTask进行计算,每个SubTask都会备份数据,还是出现好几次内存溢出导致TaskManager死掉的情况。
在配置的时候一定要注意一下TaskManagerJVM内存大小的配置,生产环境我们最后将每个TaskManager的JVM堆的大小配置在了7G左右。另外为了集群的可靠性,部署建议采取Yarn模式。
在新版本的Es中默认支持Mapping自动创建,有利也有弊。
虽然我们不需要再手写Mapping文件来规范每个字段的类型,但必须要处理好每个字段的类型,比如如果存在多级对象并且在Root对象存在含有.的字段,Es会认为这是一个对象字段而不是一个String或者int之类的基础字段。可能会导致Mapping类型冲突,导致写入失败。
因为Es是基于JVM的,Jdk采用的是32位指针,内存的分配不要超过32G。超过32G会发生指针扩容,造成效率降低,当然JDK11已经采用64位指针,不需要关心这个问题。
【推荐阅读】

