假如你有一个网站,需要用 redis 存储图片,图片名为 key,图片地址为 value,此时你有4台 Redis 服务器来存这些图片。
用户要访问 flowers.png 的图片,但不知道 flowers.png 的地址在4台中的哪一台,如果是去遍历肯定不科学,这里就需要用到分布式 hash 算法(Distributed Hash)
将图片的名称转成 hash 值,再通过取模得到的值找到 Redis 服务器。
redis 服务器号 = hash(文件名) % 服务器台数
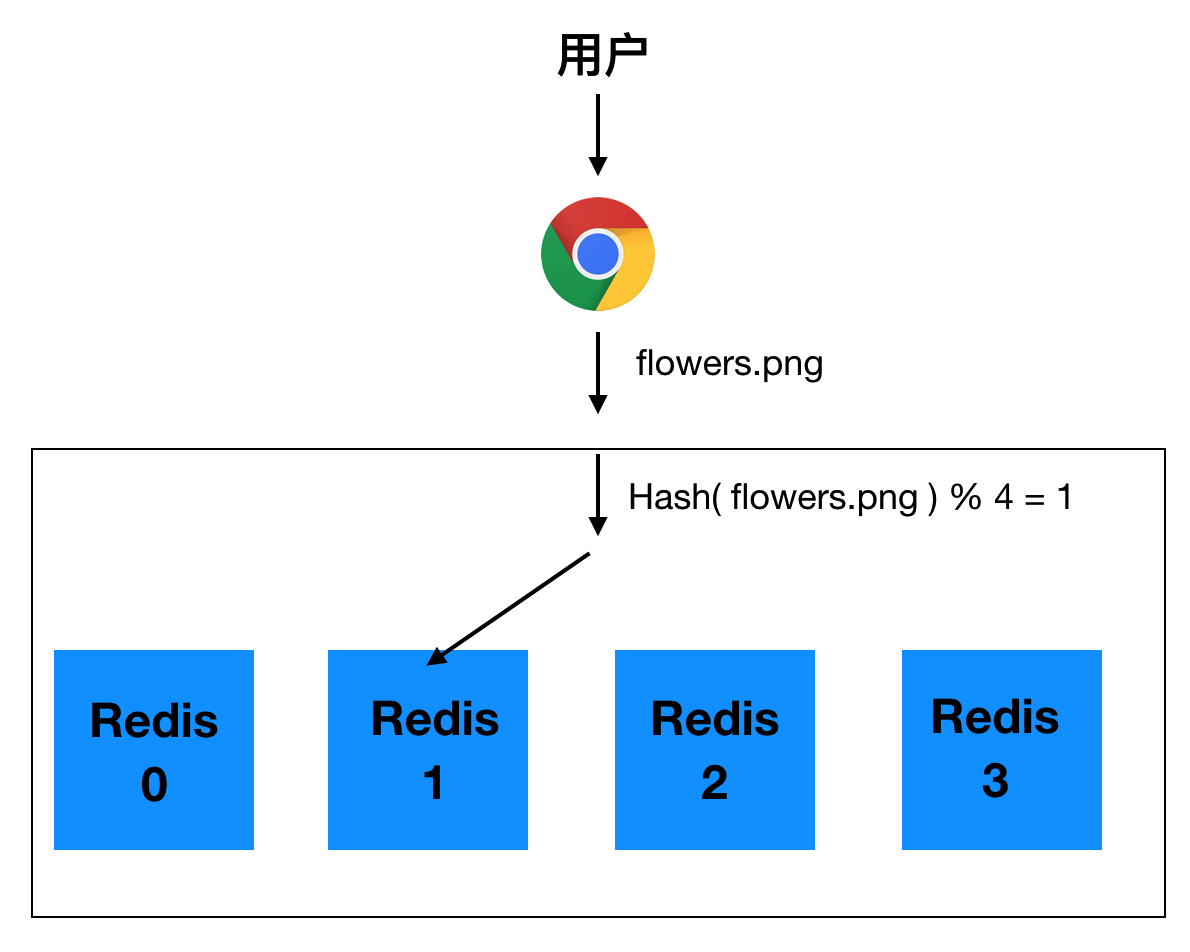
通过计算,可以直接去 Readis 1 号服务器找到 flowers.png 图片地址了。
假如此时 Readis 1 服务器崩溃了,此时的通过 Hash 值取模的方式就失效了,Hash(flowers.png)%3 肯定就不等于 1 了,这时只能对存储的所有数据进行重新计算分配,然后通过 Hash(flowers.png)%3 找到对应的服务器。
假如增加一个服务器 Readis 4,同样会对存储的所有数据进行重新计算分配。
由此可以得出结论服务数量变化会导致:1)定位服务器的计算方式失效。2)存储的所有数据需要重新计算分配。
用 Hash 一致性算法来解决这个问题。
Hash 一致性算法(Consistent Hasing)
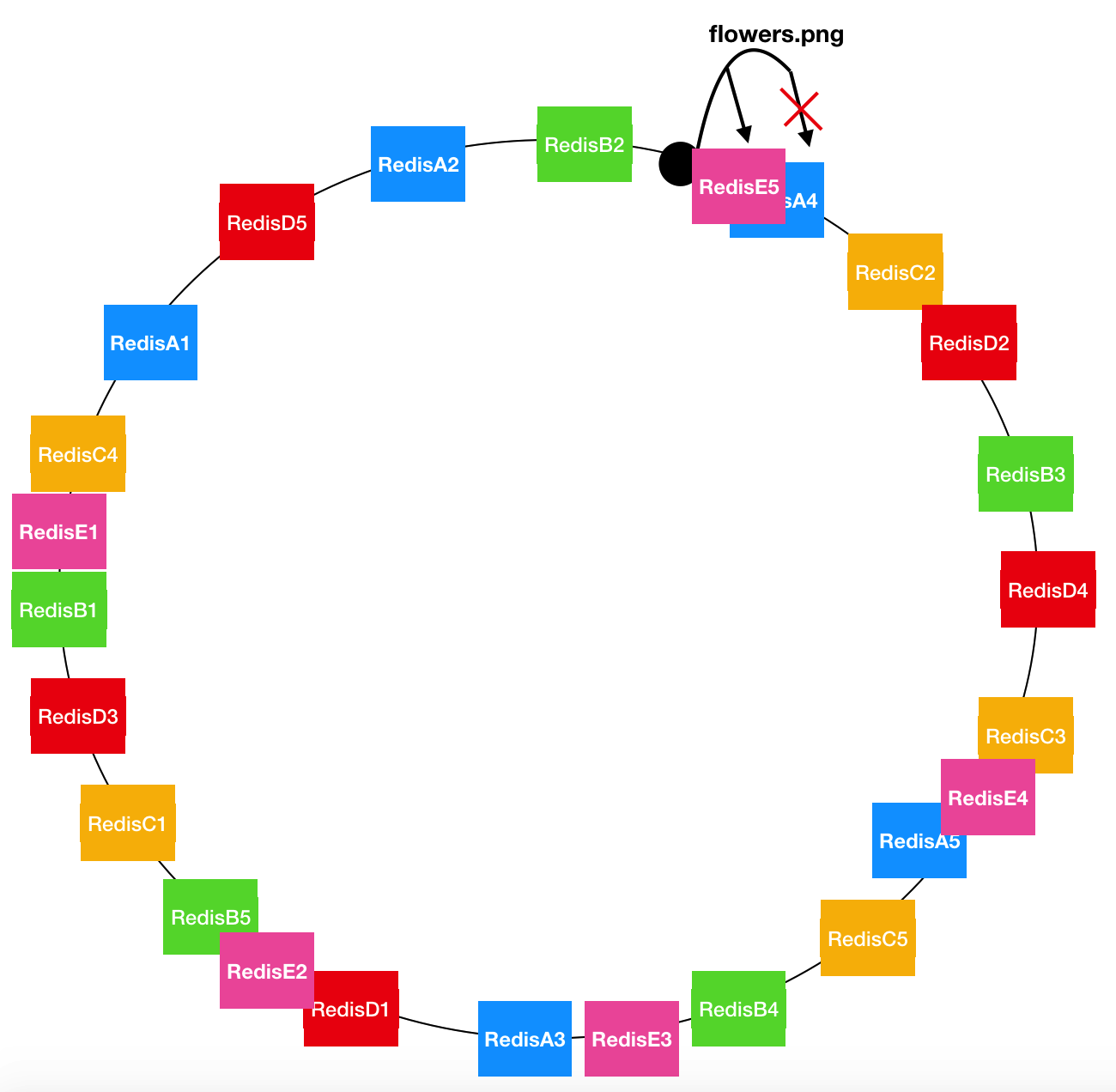
不再将服务器编号,而是将服务器信息生成一个角度(0~2π),将服务器定位到一个圆形上。由于服务器较少,可以将服务器虚拟几个节点出来,让圆上的分布更均匀,RedisA 虚拟出五个节点 RedisA1、RedisA2、RedisA3、RedisA4、RedisA5都代表 RedisA
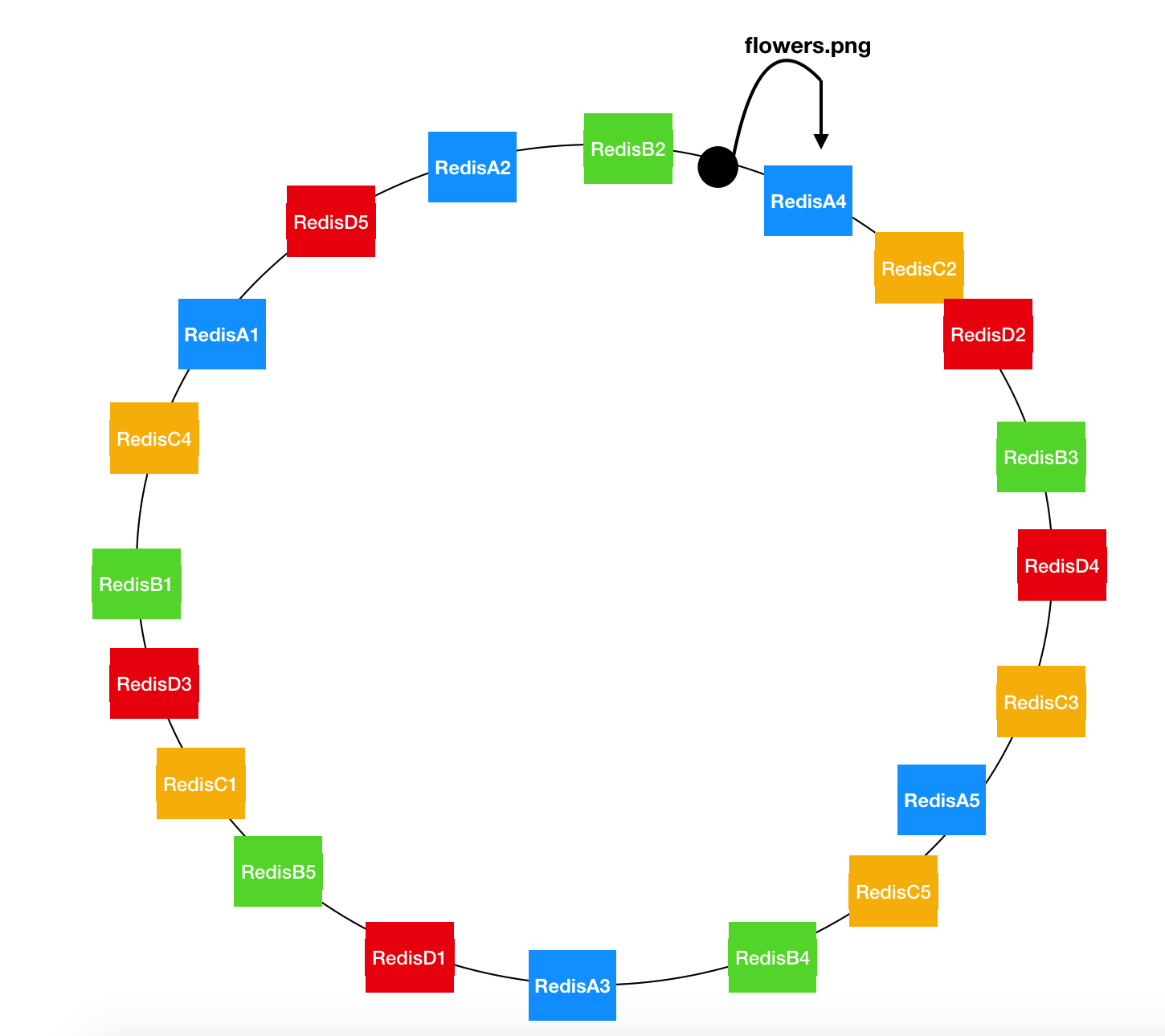
如上图 flowers.png 计算出位于小黑点的位置,那么按顺时针方向就可以找到 RedisA4。
假如 RedisA 舵机了,此时 flowers.png 的指向将顺移到下个节点 RedisC2, 所以 flowers.png 的位置计算方式不会失效,而且只需要重新计算分配与 RedisA 顺时针关联的第一个节点,其他节点保持不变。
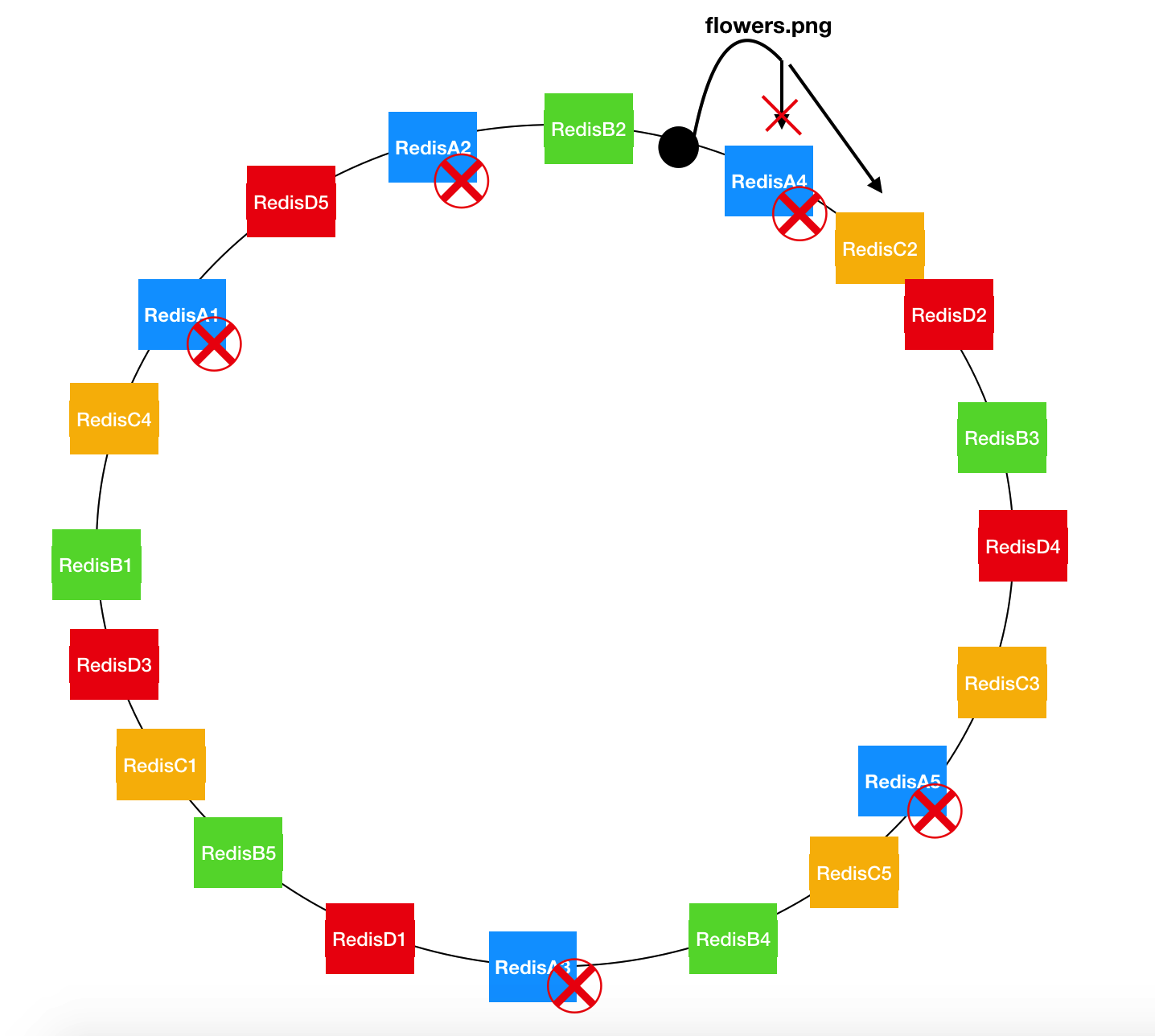
假如新增一个 RedisE 呢?与RedisA 舵机相似,flowers.png 的位置不变,指向顺时针离它最近的节点,也就是说新增节点只会与它顺时针关联的第一个节点重新计算分配,其他节点保持不变。