

执行上下文在 JavaScript 是非常重要的基础知识,想要理解 JavaScript 的执行过程,执行上下文 是你必须要掌握的知识。否则只能是知其然不知其所以然。
理解执行上下文有什么好处呢?
它可以帮助你更好的理解代码的执行过程,作用域,闭包等关键知识点。特别是闭包它是 JavaScript 中的一个难点,当你理解了执行上下文在回头看闭包时,应该会有豁然开朗的感觉。
这篇文章我们将深入了解 执行上下文,读完文章之后你应该可以清楚的了解到 JavaScript 解释器到底做了什么,为什么可以在一些函数和变量之前使用它,以及它们的值是如何确定的。
什么是执行上下文
在 JavaScript 中运行代码时,代码的执行环境非常重要,通常是下列三种情况:
- Global code:代码第一次执行时的默认环境。
- Function code:函数体中的代码
- Eval code:eval 函数内执行的文本(实际开发中很少使用,所以见到的情况不多)
在网上你可以读到很多关于作用域的文章,为了便于理解本文的内容,我们将 执行上下文 当作代码的 执行环境/作用域。现在就让我们看一个例子:它包括 全局和函数/本地执行上下文。
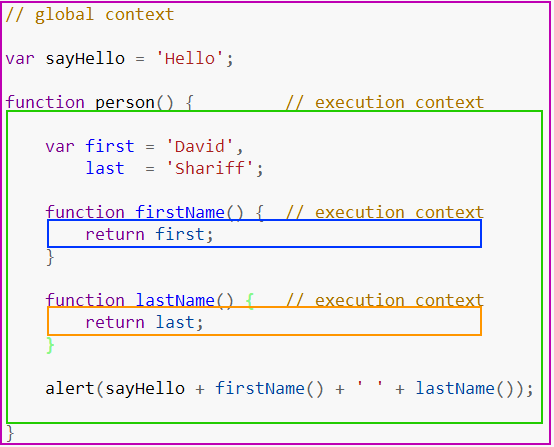
上面的例子我们看到,紫色的框代表全局上下文,绿色、蓝色、橙色代表三个不同的函数上下文。全局上下文执行有一个,它可以被其他上下文访问到。
你可以有任意数量的函数上下文,每个函数在调用时都会创建一个新的上下文,它是一个私有范围,函数内部声明的所有东西都不能在函数作用域外访问到。
上面的例子中,函数内部可以访问当前上下文之外声明的变量,但是外部却不能访问函数内部的变量/函数。这到底是为什么?其中的代码是如何执行的?
执行上下文栈
浏览器中的 JavaScript 解释器是单线程实现的。这意味着在浏览器中一次只能做一件事情。而其他的行为或事件都会在执行栈中排队等待。如图:
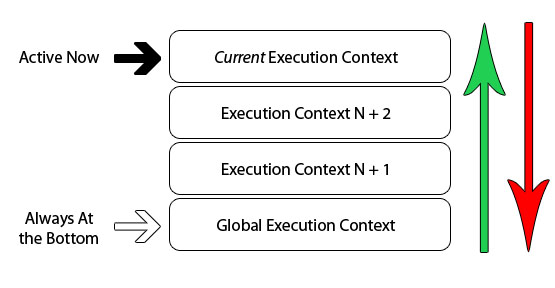
我们知道,当浏览器第一次加载脚本时,默认情况下,它会进入全局上下文。如果在全局代码中调用了一个函数,则代码的执行会进入函数中,此时会创建一个新的执行上下文,它会被推到执行上下文栈中。
如果在这个过程中函数内部调用了另一个函数,会发生同样的事情,代码的执行会进入函数中,然后创建一个新的执行上下文,它会被推到上下文栈 的顶部。浏览器始终执行栈顶部的执行上下文。
一旦函数完成执行,当前的执行上下文将从栈的顶部弹出,然后继续执行下面的,下面程序演示了一个递归函数的执行上下文情况。
(function foo(i) {
if (i === 3) {
return;
}
else {
foo(++i);
}
}(0));
自己调用自己三次,每次将 i 递增 1,每次函数 foo 被调用的时候,就会创建一个新的执行上下文。一旦当前上下文执行完毕之后,它就会从栈中弹出并转移到下面的上下文中,直到全局上下。
执行上下文栈的 5 个关键点:
- 单线程
- 同步执行
- 只有一个全局上下文
- 任意数量的函数上下文
- 每个函数调用都会创建一个新的执行上下文,包括自己调用自己
详解执行上下文
到此,我们知道每次调用一个函数时,都会创建一个新的执行上下文。但是在 JavaScript 解释器中,每次调用执行上下文会有两个阶段:
- 创建阶段
- 创建作用域链
- 创建变量,函数,
arguments列表。 - 确定
this的指向
- 执行阶段
- 赋值,寻找函数引用,解释/执行代码
执行上下文可以抽象为一个对象它具备三个属性:
executionContextObj = {
'scopeChain': { /* variableObject + all parent execution context's variableObject */ },
'variableObject': { /* function arguments / parameters, inner variable and function declarations */},
'this': {}
}
活动/变量对象[AO/VO]
executionContextObj 对象在函数调用时创建,但它是在函数真正执行之前就创建的,这就是我们所说的第一个阶段 创建阶段,此时解释器通过扫描函数的传入参数,arguments,本地函数声明,局部变量声明来创建executionContextObj 对象。将结果变成 variableObject 放入 executionContextObj 中。
解释器执行代码时的大致描述:
- 调用函数
- 在执行代码时,创建执行上下文
- 进入创建阶段
- 初始化作用域链
- 创建变量对象(variableObject)
- 创建参数对象(arguments object),检查参数的上下文,初始化名称和值,并创建引用副本
- 扫描上下文中的函数声明
- 每发现一个函数,就会在
variableObject中创建一个名称,保存函数的引用 - 如果名称已经存在,则覆盖引用
- 扫描上下文中的变量声明
- 每发现一个变量,就在
variableObject中创建一个名称,并初始化值为undefined - 如果变量名已经存在,什么都不做,继续扫描
- 确定上下文中的
this指向
- 执行代码阶段
- 在上下文中执行/解释代码,在代码逐行执行时进行变量复赋值
让我们看一个例子:
function foo(i) {
var a = 'hello';
var b = function privateB() {};
function c() {}
}
foo(22);
foo(22) 函数执行的时候,创建阶段如下:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: undefined,
b: undefined
},
this: { ... }
}
如上所述,除了形参 i 和 arguments外,在创建阶段我们只把变量进行声明而不进行赋值。
在创建阶段完成后,程序会进入函数中执行代码,如下所示:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: 'hello',
b: pointer to function privateB()
},
this: { ... }
}
声明提前
网上很多关于声明提前的内容,它是用来解释变量和函数在声明时会被提前到作用域的顶部。但是并没有人详细解释为什么会发生这种情况,有了刚才关于解释器如何创建活动对象(AO)的认知,我们将很容易看出原因。例如:
(function() {
console.log(typeof foo); // function pointer
console.log(typeof bar); // undefined
var foo = 'hello',
bar = function() {
return 'world';
};
function foo() {
return 'hello';
}
}())
我们现在可以回答如下问题:
为什么我们可以在声明之前访问foo?
在执行阶段之前,我们已经完成了创建阶段,此时变量/函数已经被创建,所以当函数执行的时候 foo 可以被访问到。
foo 被声明了两次,为什么 foo 显示的是 function 而不是 undefined 或者 string?
虽然 foo 被声明了两次,但是我们在创建阶段中说到,函数是在变量之前创建在变量对象中,当变量对象中名称已经存在时,变量声明什么也不做。
因此 foo 会被先创建为函数 function foo() 的引用,当执行到 var foo时发现变量对象中已将存在了,所以此时什么也不做,而是继续扫描。
为什么 bar 是 undefined?
bar 实际上是一个变量只不过它的值是函数,而变量在创建阶段的值为 undefined。
总结
我们再来梳理下重要的知识点:
- 首先在程序执行时会创建一个全局的执行上下文,有且只有一个。
- 函数在每次调用时就会创建一个函数上下文,可以有很多。
- 函数上下文可以访问全局上下文的内容,反之则不行。
- 创建的上下文会被推入到上下文栈中,然后从顶部开始依次执行。
- 执行上下文会分为两个阶段:创建阶段和执行阶段。
- 创建阶段会先进行函数声明和变量声明提前。
- 创建阶段会先进行函数声明,然后进行变量声明,同时会被放入
变量对象中,如果变量对象中已经存在:函数则进行引用的覆盖,变量则什么都不做。 - 执行阶段才会进行赋值和运行。
希望你已经理解了 JavaScript 解释器是如何执行你的代码的。理解执行上下文和 执行上下文栈能够让你清楚的知道你的代码为什么和预期的值不一样。
你认为了解,解释器的内部原理是多余还是必须的知识?它是否能够帮助你更好的编写 JavaScript 代码?欢迎留言讨论。
原文:davidshariff.com/blog/what-i…
翻译:六小登登
更多优质文章:六小登登的博客
我是:六小登登,一名爱写作的技术人。 关注公众号:六小登登,后台回复「1024」即可免费获取惊喜福利!后台回复「加群」群里每天都会全网搜罗好文章给你。

