

前言
技术群里有人提问:请教一个正则 可以输入正负9位整数2位小数,小数可以不输入。于是,八仙过海,各显神通!
群里大佬的回答
很快,就有一位大佬发来一个他以前写的保留 2 位小数正则
// 这个正则是利用分组的方法,先匹配有没有减号,,然后匹配数字,然后匹配小数点,最后匹配2位小数
/^(\-)*(\d+)\.(\d{2})+.*$/
明显这个大佬的正则达不到提问同学的的需求,于是又有大佬给出了他的正则
// 这个正则首先利用了?号的非贪婪模式匹配减号,然后匹配9位数,然后又用?号匹配是否有小数点
/^-?[0-9]{9}(\.[0-9]{2})?$/
很快有人指出这个只能固定9位数,数字不能是固定的,大佬又修改了一版
// 这个已经稍微能用了,可以匹配正负9位整数2位小数,小数可以不输入
/^-?[0-9]{1,9}(\.[0-9]{1,2})?$/
急速(大概1~2秒钟),又有大佬指出,上面的正则可以匹配首位数为0的情况,一般来说,数字的首位数不能为0
首位数字不能为0,那就加个判断就好了,于是正则改为
// 改为匹配首位数只能是1~9,不能为0
/^-?[1-9]{1}[0-9]{0,8}(\.[0-9]{1,2})?$/
光速(几乎秒发),杠精(😀)提问:如果是是零点几的情况呢,或者就是整数0呢
大佬无奈给出
// 在分组和非贪婪匹配的基础上,又加上了与或非的概念,匹配整数,或者零点几的2位小数,或者是N位整数的2位小数
/^-?(([1-9][0-9]*)|(([0]\.\d{1,2}|[1-9][0-9]*\.\d{1,2})))$/
但是这位大佬估计是没看清题目,没有限制整数的位数,于是又有大佬发出正则,逐渐复杂
// 根据前面大佬的正则修改了一下,匹配前面不能为0的2为小数,或者零点几的2位小数,或者0
/^(-?[1-9]{1}[0-9]{0,8}(\.[0-9]{1,2})?)|(0(\.[0-9]{1,2}))|(0)$/
有大佬感觉上面的正则都有点长,给出一个短的
// 这个大佬喜欢使用集合,匹配加减号的集合,匹配任意数字的集合,匹配小数点的集合
/[+-]?[\d]{1,9}(\.[\d]{1,2})?/
结合上面各位大佬的正则,有人给出
// 集合匹配加减号,匹配非零开头的2位小数,或者零开头的小数
/^[+-]?(([1-9][0-9]{0,8})|0)(\.[0-9]{1,2})?$/
讨论到这里告一段落,我等萌新看的是瑟瑟发抖,完全不敢说话。
tips:记得转string再用test判断,使用数字类型进入判断,最前面的0会自动给去掉
前端如何去写正则
在前端的项目中,会有许多需要正则的地方,那么如何去写一个正则呢?
有很多人说过正则不用去记,是的,大部分不用记。但是我们如何去写正则还是有必要去记一下的,这里我本人总结7条
- 1、任何复杂的正则都可以用()号分组简单化
- 2、| 这个符号是个好东西,或者或者或者,正则就出来了
- 3、^ 开头,$ 结尾
- 4、如果要这个正则匹配全部,多次查找,就在最后面的 / 下面加个g,也就是 /g
- 5、如果不区分大小写加个 i ,也就是 /i
- 6、合理使用搜索引擎,还是直接给一个搜索词吧:正则表达式速查表
- 7、实在是自己写不出来,就搜索有没有写好的,或者去技术群里问大佬,要是没有大佬回复,就发个红包
正则表达式优化
当我们会自己写正则之后,就要考虑一个问题了,如何写好一个高效率的正则,举个例子:
// 比如说我们有一个字符串
const string = "TypeError: Cannot read property 'fundAbbrName' of undefined at Proxy.render (eval at";
// 我们要截取TypeError: 到 (eval 之间的数据,使用正则
const reg = /(?:TypeError\:)(.*?)(?=\(eval)/

使用RegexBuddy检测需要283步
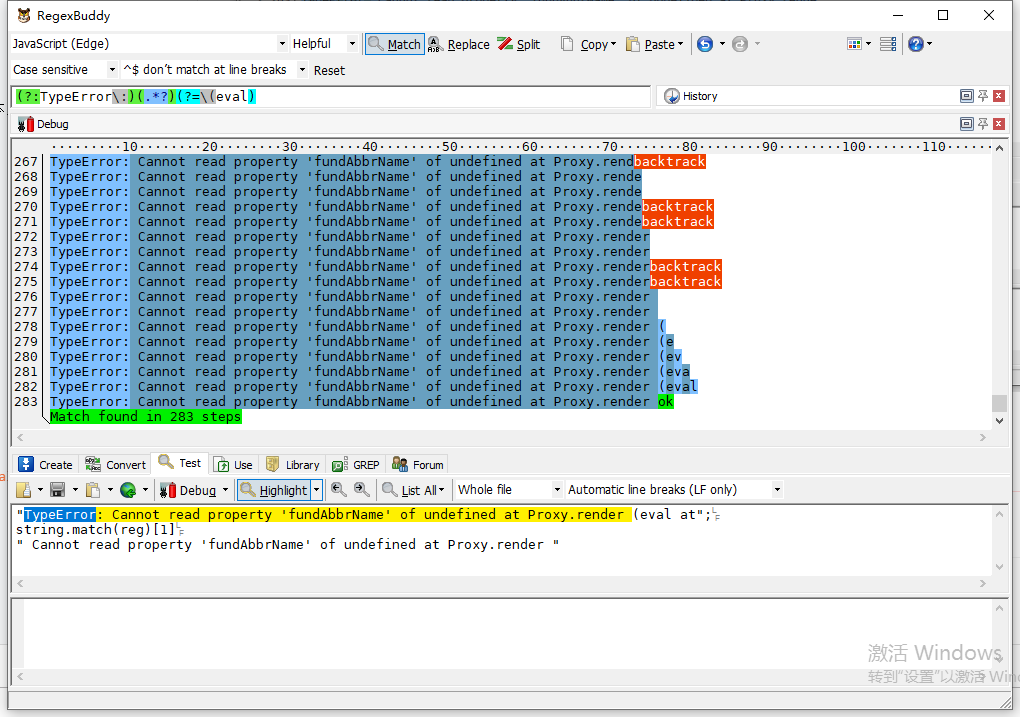
修改一下:
const reg = /TypeError\:(.*?)\(e/

使用RegexBuddy检测需要212步

再优化一下,改动一个单词,把 * 改成 +
const reg = /TypeError\:(.+?)\(e/

步数减少了,现在需要209步

加一个限定条件 \s
const reg = /TypeError\:\s(.+?)\(e/

又少了2步,现在只需要207步
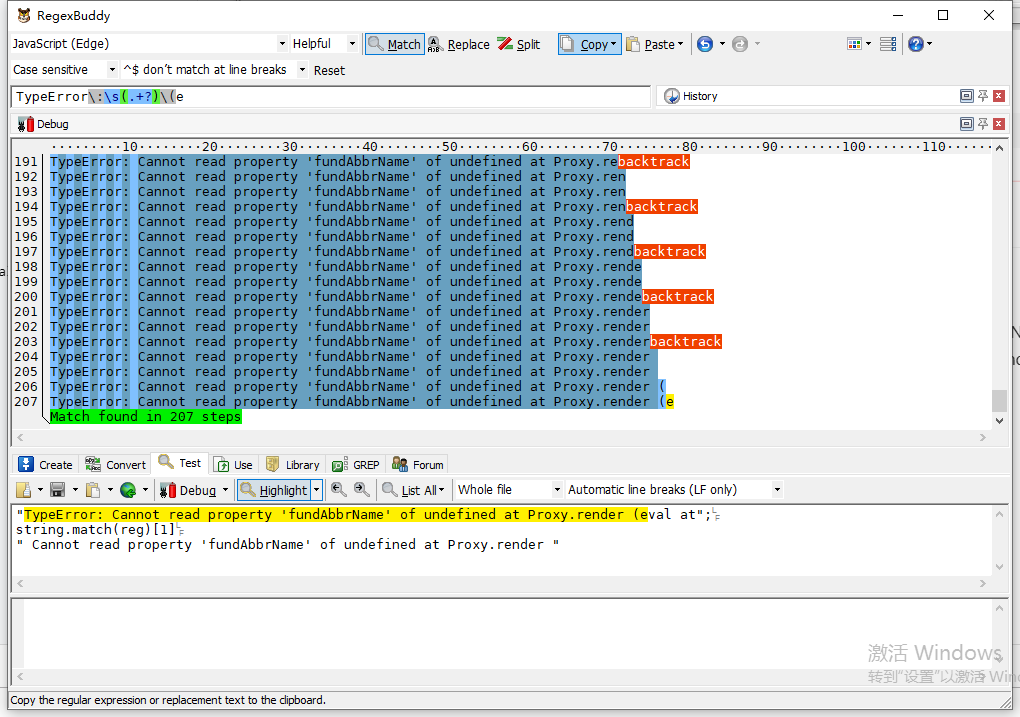
改一下前面的限定条件
const reg = /\w+\:\s(.+?)\(e/

进入200步以内了,199步
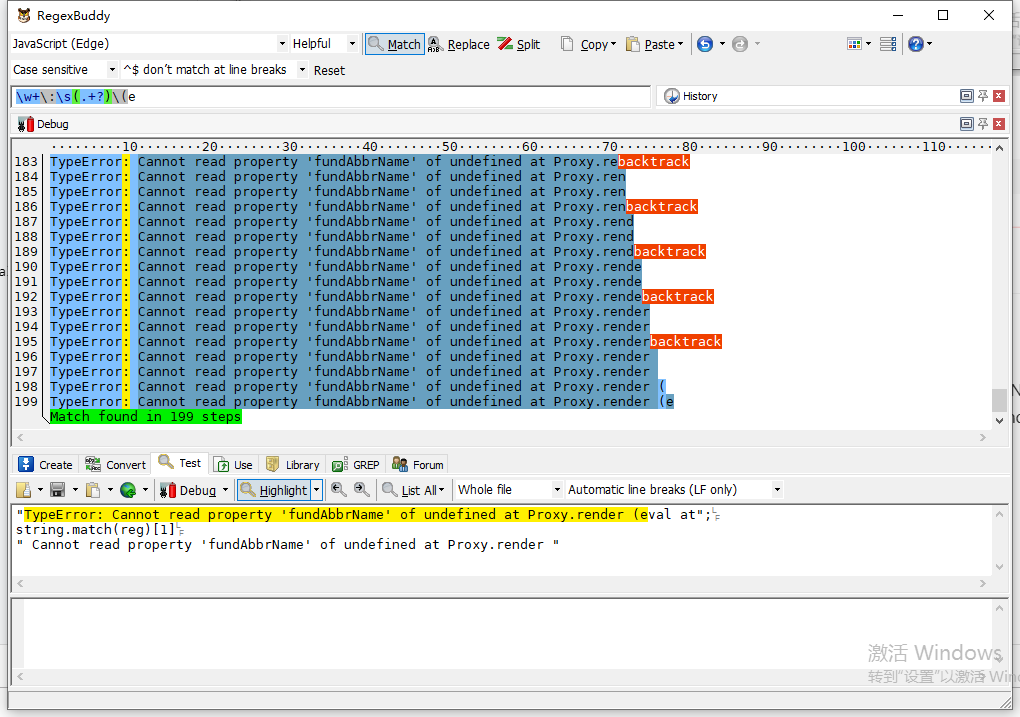
终极优化
const reg = /\w+\:(.+)\(/

只需35步

通过上面的例子我们可以得出一些正则优化方面的心得:
- 当要捕获组的时候,使用非捕获型括号(?:),但是某些时候使用不必要的(?:)反而会造成性能的浪费
- 使用一些匹配规则能够提高正则的效率,比如说用 \w+ 替代 TypeError
- 如果确认至少匹配1次,那么请用 + 号替代 * 号
- 如果确认匹配的数量,请用 {n,m} 替代 + 号
- 在大多数的情况下,限定条件多,会提高正则的效率
- 尽量使用非贪婪模式 ? ,但是,在某些情况下,不使用非贪婪模式反而效率会更快
最后
本人水平有限,又错误之处希望各位大佬指出!
关于正则,我还写过一篇文章记一次面试题,正则表达式(?=a)是什么意思?,大佬们有空可以去看看。
