

我们在项目开发中经常会遇到这样的场景:企业组织架构,回复评论链,商品类目等树型结构。本文结合网上一些资料,以及自己在项目中的实践来说一说几种处理树型结构的方式。
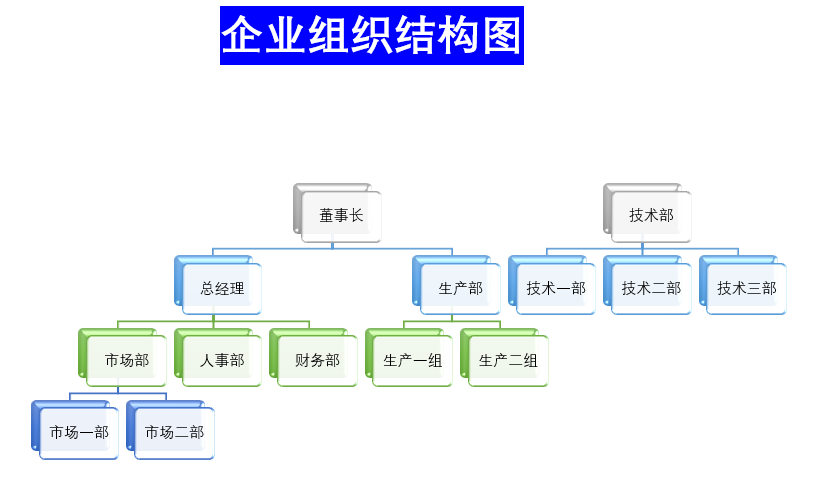
可能有不少小伙伴遇到该问题,第一个想法就是我在每条数据上都保存它的parent_id就可以满足需求了啊,这样一层一层都能找到, 写一个递归算法就可以拿到他的所有下级或者上级。这是一种可以实现的方式,我们先不评价这种方式的优劣。
下面先说下几种常见的处理方式:
- Adjacency list (邻接表)
- Closure table (闭包表)
- Path enumeration (路径枚举)
- Nested Sets(嵌套集)
本文主要讲解Path enumeration (路径枚举),其它几种只做简单的展示,有需要了解的可以点击一下连接查看
-
对Closure table 讲解详细www.jianshu.com/p/951b742fd…
-
四种方式都有讲解 www.cnblogs.com/wjq310/p/88…
-
MySQL实现嵌套集合模型 yq.aliyun.com/articles/50…
Adjacency list (邻接表)
下图是一个简单的邻接表结构的组织结构,也就是前面我们的说方式
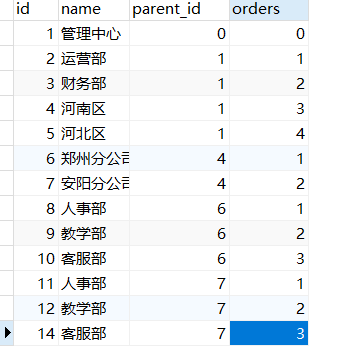
获取数据的方式
- 获取某组织下的直属部门,我们只需根据组织的id查询即可
select * from org where parent_id =1;
- 查询某组织下的所有组织,需要递归的+循环拿到子、孙...的下级节点,大概写法如下:
public List<Org> getOrgTree(String parentId){
List<Orgs> resultOrgs = new ArrayList<>();
// 拿到下级组织
List<Org> children = getChildren(parentId);
resultOrgs.addAll(children);
for(Org org :children){
resultOrgs.addAll(getOrgTree(org.parentID));
}
return resultOrgs;
}
Closure table (闭包表)
这种方式用帖子评论来介绍,数据构造麻烦,借用了www.jianshu.com/p/951b742fd…中的图,数据库模型如下:
.png)
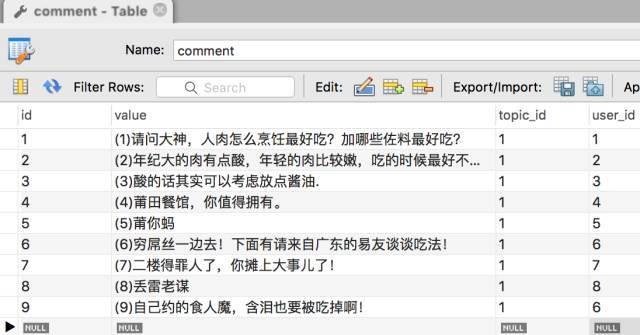
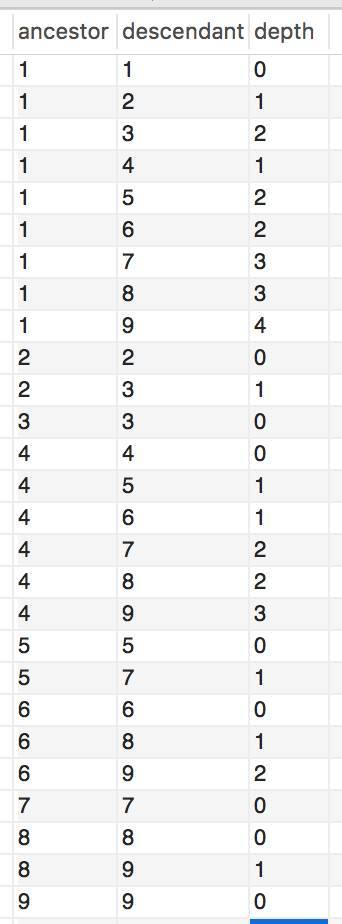
ancestor 存储回复的根Id,descendant 存储当前Id,中存储占空间,理论上讲需要O(n²)的空间来存储关系。
-- 父查子,连表查询comment 和 comment_path 拿到4号的评论
select c.* from comment c
left join comment_path cp on (c.id = cp.descendant)
where cp.ancestor = 4 and depth = 1;
-- 查询4号的所有子评论
select c.* from comment c join comment_path cp on (c.id = cp.descendant) where cp.ancestor = 4;
Nested Sets(嵌套集)
嵌套集解决方案将信息存储在每个节点中,每个节点对应于其后代的集合,而不是节点的直接父节点。
在嵌套集设计中,树的操作、插入和移动节点通常比在其他模型中更加复杂。
插入新节点时,需要重新计算所有大于新节点左值的左、右值。
嵌套集过于复杂,本人也没完全搞懂,本文不做详细介绍。可以参考MySQL实现嵌套集合模型
Path enumeration (路径枚举)
该方式以项目中组织表为例,与路径枚举的区别是这里采用org_num来代替path,
项目中我们约定每一层级的编号长度为2,最大层级为20,每层的子节点数99,最大可存储节点数为: 2的19次方个节点
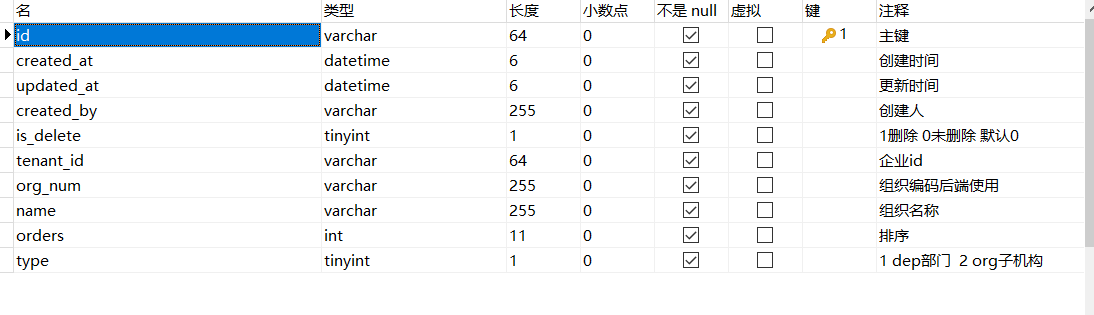
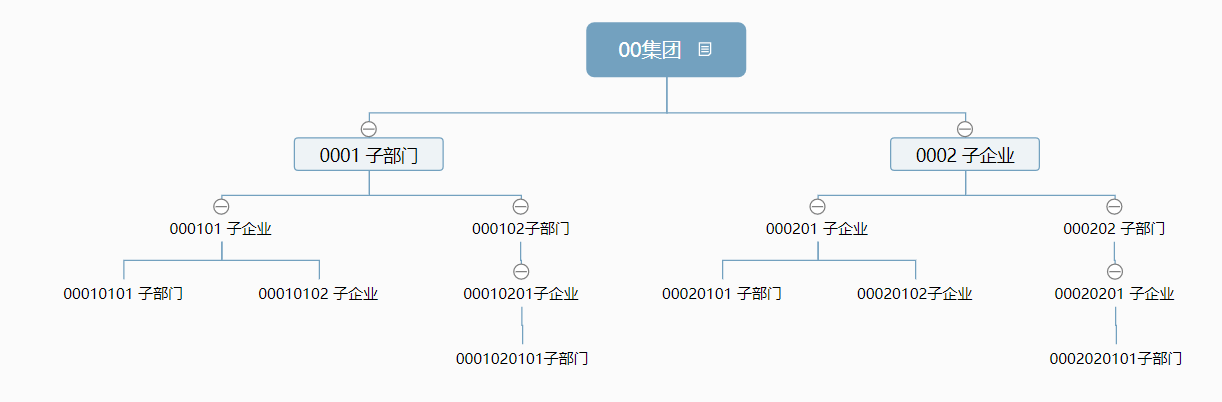
层级结构如下:
操作数据的几种方式
约定 orgNum某节点的编号, orgLen 某节点编号的长度
- 拿到某节点的某几层子节点
-- 在java代码中根据当前节点orgNum得到 orgLen和maxLength
select * from orgs where org_num like '#{orgNum}%' and length(org_num) > #{orgLen} and length(org_num) <=#{maxLength}
- 拿到某个节点的所有子节点
select * from orgs where org_num like '#{orgNum}%' and length(org_num) > #{orgLen}
- 获取父节点或向上找几层的父节点
-- 先在java代码中的根据当前节点orgNum, 计算得出要找节点的orgNum,
select * from orgs where org_num = #{orgNum}
- 删除组织结构
-- 删除所有子节点,和查询所有子节点类型
delete from orgs where org_num like '#{orgNum}%' and length(org_num) > #{orgLen}
- 节点移动
// 节点移动,更新当前节点的org_num以及所有下级子节点的org_num
// 如果牵扯到节点排序,则除了更新当前节点的orgNum外,还要考虑要移动到的同级节点的orders
- 组织树构造
// 先从数据库中得到某个节点本身rootOrg及所有下级节点OrgList
private OrgTreeDTO orgTreeGenerate(List<Org> OrgList, Org rootNode, Org parent) {
List<Org> subNodes = OrgList.stream().filter(x ->
x.getOrgNum().startsWith(rootNode.getOrgNum())
&& x.getOrgNum().length() == rootNode.getOrgNum().length() + OrgConst.ORG_NODE_LENGTH
&& !x.getId().equals(rootNode.getId())
).collect(Collectors.toList());
OrgTreeDTO orgTreeDTO = new OrgTreeDTO().setId(rootNode.getId())
.setName(rootNode.getName())
.setOrders(rootNode.getOrders())
.setType(rootNode.getType())
.setChildren(subNodes.stream().map(x ->
orgTreeGenerate(OrgList, x,rootNode)
).collect(Collectors.toList()));
if(!ObjectUtils.isEmpty(parent)){
orgTreeDTO.setParentId(parent.getId())
.setParentName(parent.getName());
}
return orgTreeDTO;
}
以上几种方法几乎可以满足大部分的组织结构调整需求。
该种方式的优点是可以通过简单查询从数据库中得到想要的数据,具体组装放在java代码中处理。
缺点如果层级过深,org_num会越来越长影响查询效率,所以项目中限制节点深度为20,可以满足几乎所有的组织结构数据。
总结
本文到此结束,如果类似设计上的想法或疑问,欢迎讨论。
理论明确实践的方向,实践鉴定理论的真伪。
