

背景
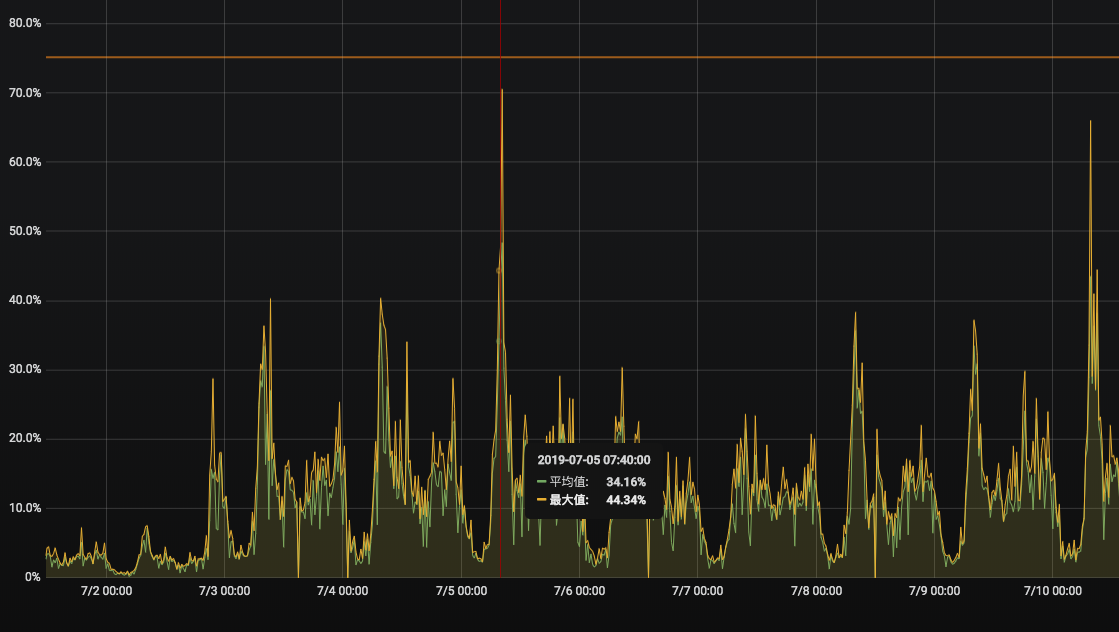
话不多说,先上图,这是得到App静态资源更新服务的CPU使用率监控,可以看到7月2号到7月3号后,cpu使用率发生了爆涨,在八点的早高峰和下午六点的晚高峰,几乎可以把cpu打满。发现问题当机立断,升级配置将2核4g升级至4核8g,先保证服务稳定,我们再继续查问题。
下图是升级配置后的截图,所以看到的图已经温柔很多了,本人当时看到监控的时候,所有波峰都是打在红线以上的,虽然还没有引起报警,但是默默掏出小本本记下找时间查问题。
问题分析
因为有很明显的发生变化的时间点,直接能找到这一次的改动,经过一点点的代码级review,并没有发现变动的代码上有什么问题。作为一个小前端没遇到过这种问题呀,毫无头绪的我,把救世主锁定在了火焰图身上,想看一看到底什么地方耗时长到底cpu占用在了什么东西上。
火焰图
于是怎么生成火焰图成了我最大的难题,开始Google搜索,“如何生成火焰图” ,“node 火焰图”,“node cpu profiler”, “node flamegraph”。看来看去所有文章千篇一律,95%以上的文章都是如下解决方案。
1.Linux perf
参考文章:nodejs调试指南 perf + FlameGraph
Linux自带的系统性能分析工具,一堆功能我就不多说了,有兴趣的自己去看nodejs调试指南打开书的第一页。因为使用的局限性不是Linux的我,第一步apt install linux-tools-common都安不上,如果还要跑在虚拟机什么的上面是不是太麻烦了,方案一卒。
2.Node.js 自带的分析工具
参考文章:易于分析的 Node.js 应用程序 | Node.js
Node.js4.4.0开始,node本身就可以记录进程中V8引擎的性能信息(profiler),只需要在启动的时候加上参数--prof。 Node自带的分析工具:
- 启动应用的时候,node需要带上—-prof参数
- 然后就会将性能相关信息收集到node运行目录下生成isolate-xxxxxxxxxxxxx-v8.log文件
- npm有一个包可以方便的直接将isolate文件转换成,html形式的火焰图GitHub - mapbox/flamebearer: Blazing fast flame graph tool for V8 and Node 🔥
完成以上步骤火焰图果不其然的跑了出来
3.使用Dtrace收集性能数据
直接查到应用的pid直接对pid进行收集,然后也可以将收集到的数据制成火焰图,具体操作就不做赘述了,最后跑出来的图如下,
好了以上就是我Google出来的各种方案在我一一踩坑后全部以失败告终,其实也还有一些更简单的方案,例如直接接入alinode用阿里云的平台就好,一方面该项目没有接入阿里云,刚好用的node镜像又不是ali的,另一方面,如果可以在开发环境查出问题,不希望再通过上线去查问题。
方案四:v8-profiler
Node.js 是基于 V8 引擎的,V8 暴露了一些 profiler API,我们可以通过 v8-profiler 收集一些运行时的CPU和内存数据。 在安装v8-profiler的时候遇到了一些问题总是安装失败,并且得不到解决。不过好在有大神基于v8-profiler发布了v8-profiler-node8,下面是v8-profiler-node8的一段描述。
Based on v8-profiler-node8@5.7.0, Solved the v8-profiler segment fault error in node-v8.x.
v8-profiler-node8 provides node bindings for the v8 profiler and integration with node-inspector
收集数据: 简单的npm install v8-profiler-node8后,开始收集CPU profile,收集时长五分钟。
const profiler = require('v8-profiler-node8');
const fs = require('fs');
const Bluebird = require('bluebird');
class PackageController extends Controller {
async cpuProf() {
console.log('开始收集');
// Start Profiling
profiler.startProfiling('CPU profile');
await Bluebird.delay(60000 * 5);
const profile = profiler.stopProfiling();
profile.export()
.pipe(fs.createWriteStream(`cpuprofile-${Date.now()}.cpuprofile`))
.on('finish', () => profile.delete());
this.ctx.status = 204;
}
}
然后立即用ab压测,给服务压力,
ab -t 300 -c 10 -p post.txt -T "application/json" http://localhost:7001/xxx/xxxxx/xxxxxx/xxxxx
收集完成后,得到一个cpuProfile文件,Chrome 自带了分析 CPU profile 日志的工具。打开 Chrome -> 调出开发者工具(DevTools) -> 单击右上角三个点的按钮 -> More tools -> JavaScript Profiler -> Load,加载刚才生成的 cpuprofile 文件。可以直接用chrome的性能分析直接读这个文件打开分析。 这里我要推荐一下 speedscope 一个根据cpuProfile生成火焰图的工具,他生成的火焰图,更清晰,还有leftHeavy模式,直接将CPU占用率最高的排在最左边,一目了然,快速的可以定位到问题。

根据火焰图解决问题
下面是该火焰图的leftHeavy模式
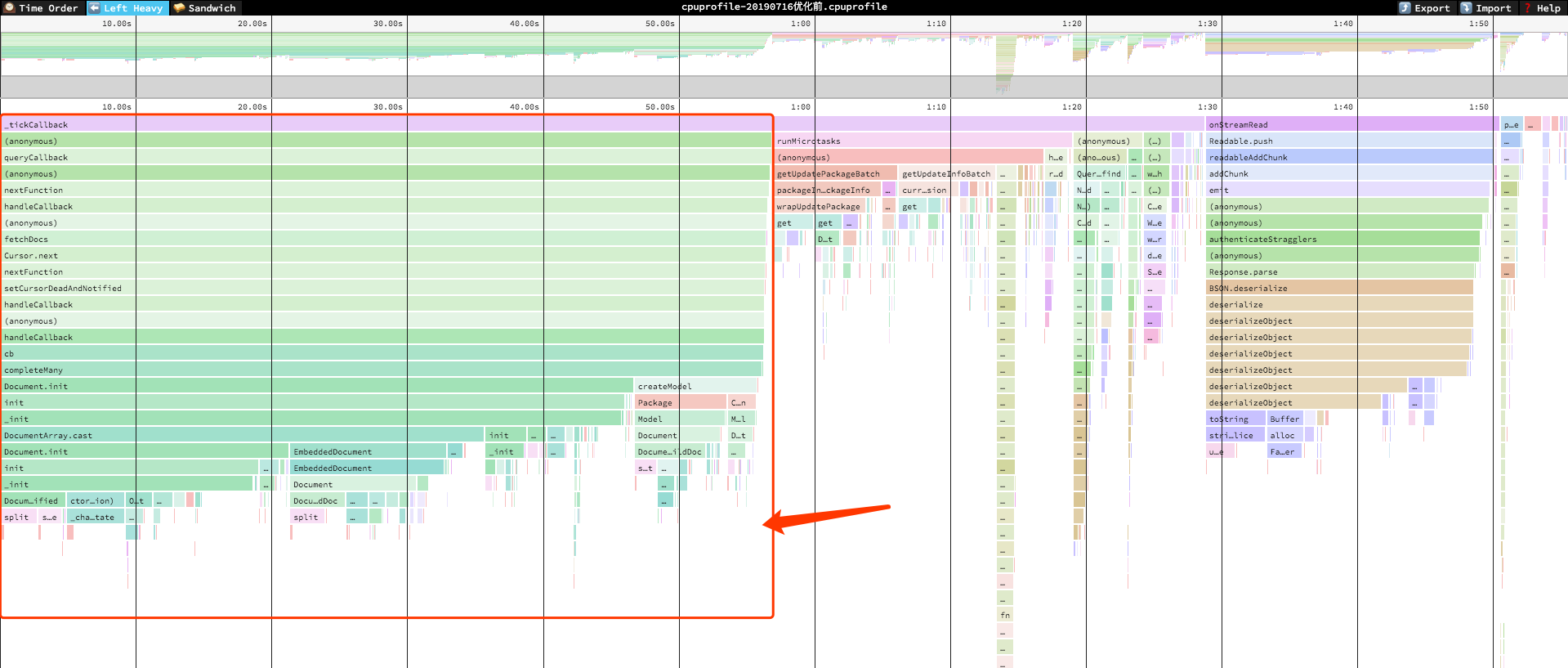
看火焰图的时候越图形越尖说明越正常,横条越长说明占用时间越长,从图中可以看到压测的五分钟里,CPU占用时间长达两分钟,其中绝大多数被红框中占据,来张大图

/*!
* hydrates many documents
*
* @param {Model} model
* @param {Array} docs
* @param {Object} fields
* @param {Query} self
* @param {Array} [pop] array of paths used in population
* @param {Function} callback
*/
function completeMany(model, docs, fields, userProvidedFields, pop, callback) {
var arr = [];
var count = docs.length;
var len = count;
var opts = pop ? { populated: pop } : undefined;
var error = null;
function init(_error) {
if (error != null) {
return;
}
if (_error != null) {
error = _error;
return callback(error);
}
--count || callback(null, arr);
}
for (var i = 0; i < len; ++i) {
arr[i] = helpers.createModel(model, docs[i], fields, userProvidedFields);
arr[i].init(docs[i], opts, init);
}
}
completeMany方法会将传入的每一个docs通过 helpers.createModel变成一个mongoose Document,我们再来看一下是哪里调用的completeMany方法,发现在find方法中会判断options.lean是否等于true如果不等于true才会去调用completeMany方法去包装查询结果。
/**
* Thunk around find()
*
* @param {Function} [callback]
* @return {Query} this
* @api private
*/
Query.prototype._find = function(callback) {
this._castConditions();
if (this.error() != null) {
callback(this.error());
return this;
}
this._applyPaths();
this._fields = this._castFields(this._fields);
var fields = this._fieldsForExec();
var options = this._mongooseOptions;
var _this = this;
var userProvidedFields = _this._userProvidedFields || {};
var cb = function(err, docs) {
if (err) {
return callback(err);
}
if (docs.length === 0) {
return callback(null, docs);
}
if (!options.populate) {
// 看这里 重点重点!
return !!options.lean === true
? callback(null, docs)
: completeMany(_this.model, docs, fields, userProvidedFields, null, callback);
}
var pop = helpers.preparePopulationOptionsMQ(_this, options);
pop.__noPromise = true;
_this.model.populate(docs, pop, function(err, docs) {
if (err) return callback(err);
return !!options.lean === true
? callback(null, docs)
: completeMany(_this.model, docs, fields, userProvidedFields, pop, callback);
});
};
return Query.base.find.call(this, {}, cb);
};
去文档上搜一下lean mongoose query lean 文档上说了如果使用了lean那么查询返回的将是一个javascript objects, not Mongoose Documents 。原话如下。
Documents returned from queries with theleanoption enabled are plain javascript objects, not Mongoose Documents . They have nosavemethod, getters/setters, virtuals, or other Mongoose features.
在文档中还提到了,lean精简模式,对于高性能只读的情况是非常有用的。
优化
回到问题上来,看到mongoose Document的问题,7月2号到7月3号后,为什么会突然导致CPU暴涨恍然大悟,自己之前review 代码,看着代码没问题,但是忽略了这一个版本因为业务调整导致查询压力大大增加,可能是过去的好几倍这个问题。随即将查询改成精简模式。只需要如下很简单的几处修改即可。
await model.Package.find(query).lean();
那说到频繁的处理mongoose Document导致的性能问题,那其实还有一个优化点可以做,其实在查询的时候多多使用find的第二个参数projection去投影所需要返回的键,需要用什么就投影什么,不要一股脑把所有的键值一起返回了。处理完这一系列,重写在本地进行了一次同样的压测五分钟,出了一份火焰图,下面图1就是这五分钟期间的火焰图,图二就是经过speedscope解析过后的leftHeavy图,直接观察重灾区。
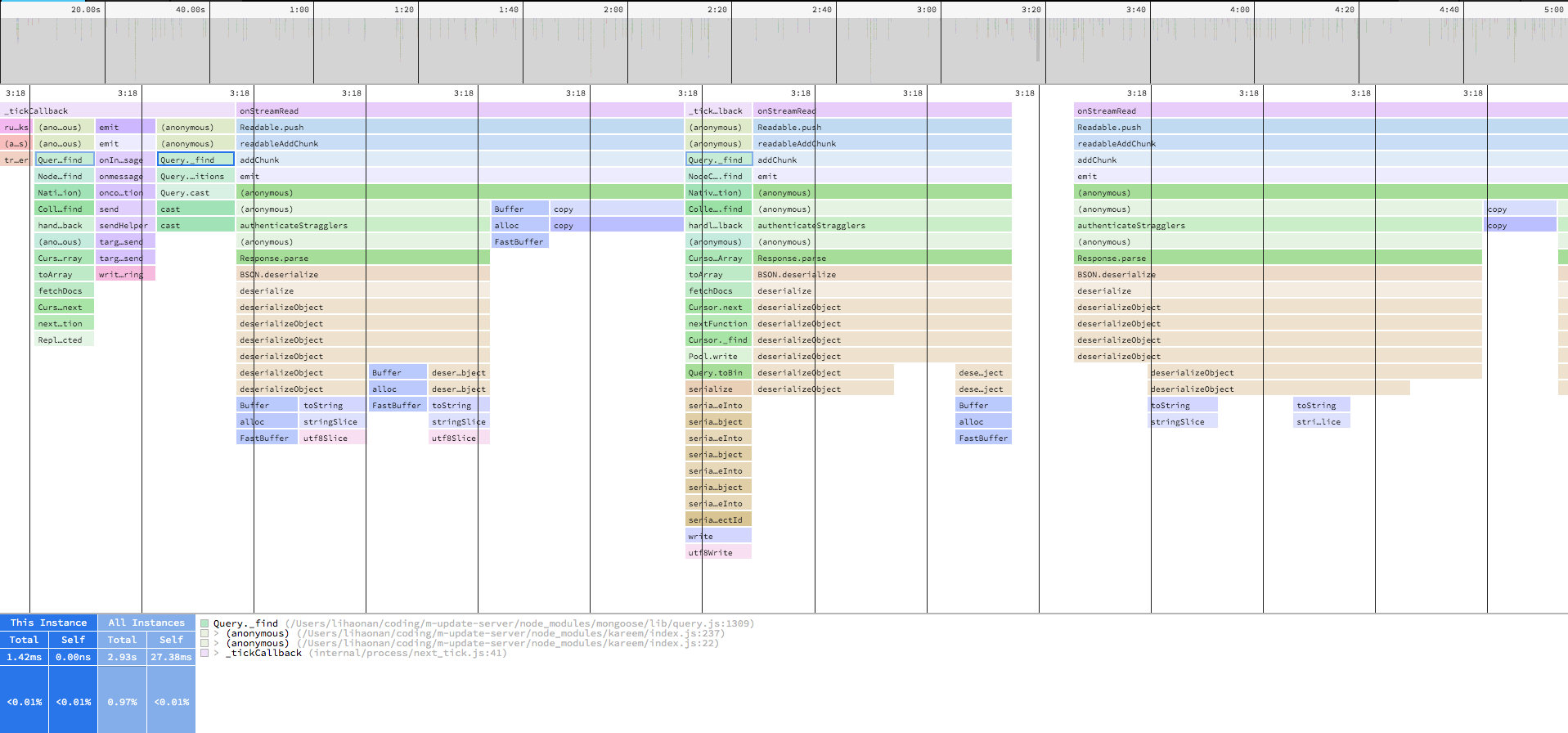
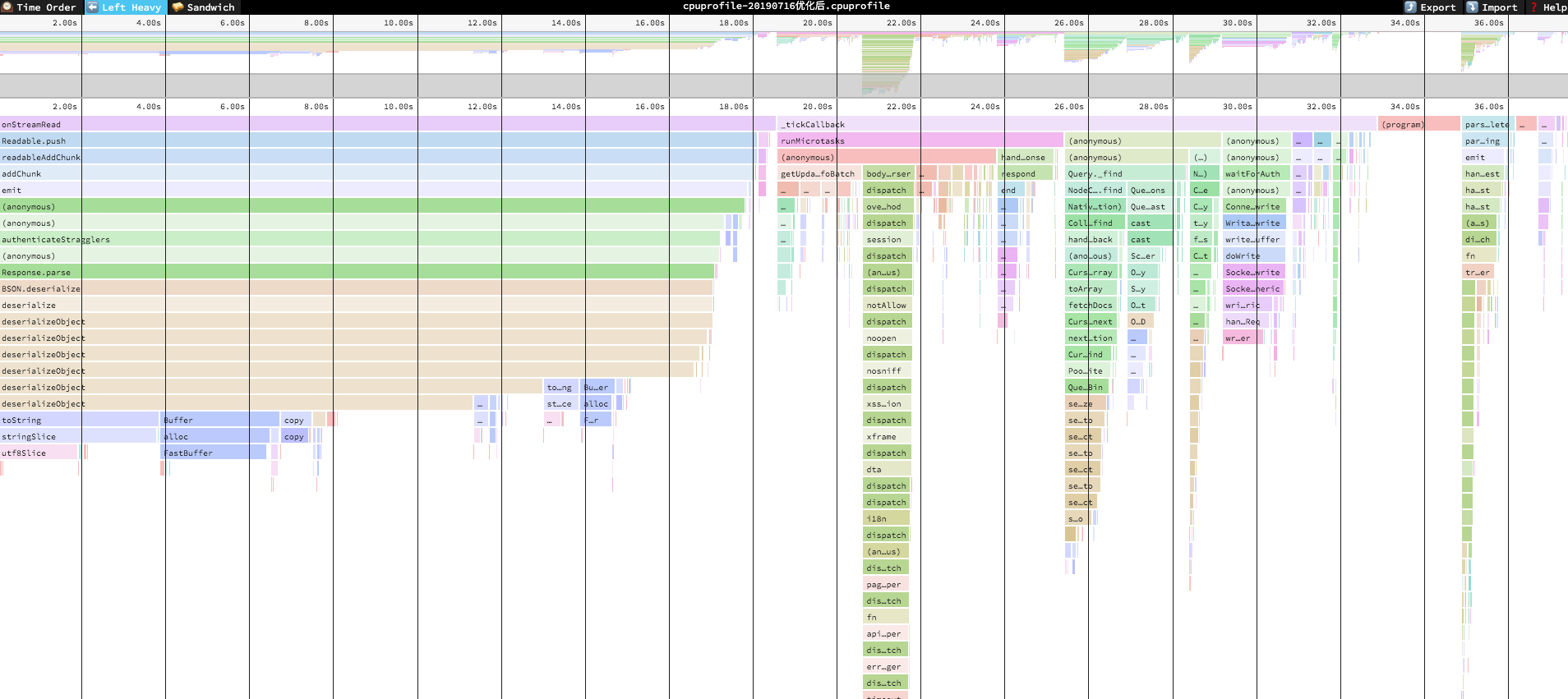
从图一的火焰图中,并不能看出明显的区别,但是一看到图二就知道我们的优化是有效果的,从最直观的,原本左侧红框中completeMany的部分直接没有了,然后cpu占用的总时长也由原本的接近两分钟直接降到了36s,优化效果还是十分明显的。上线观察几天看看效果
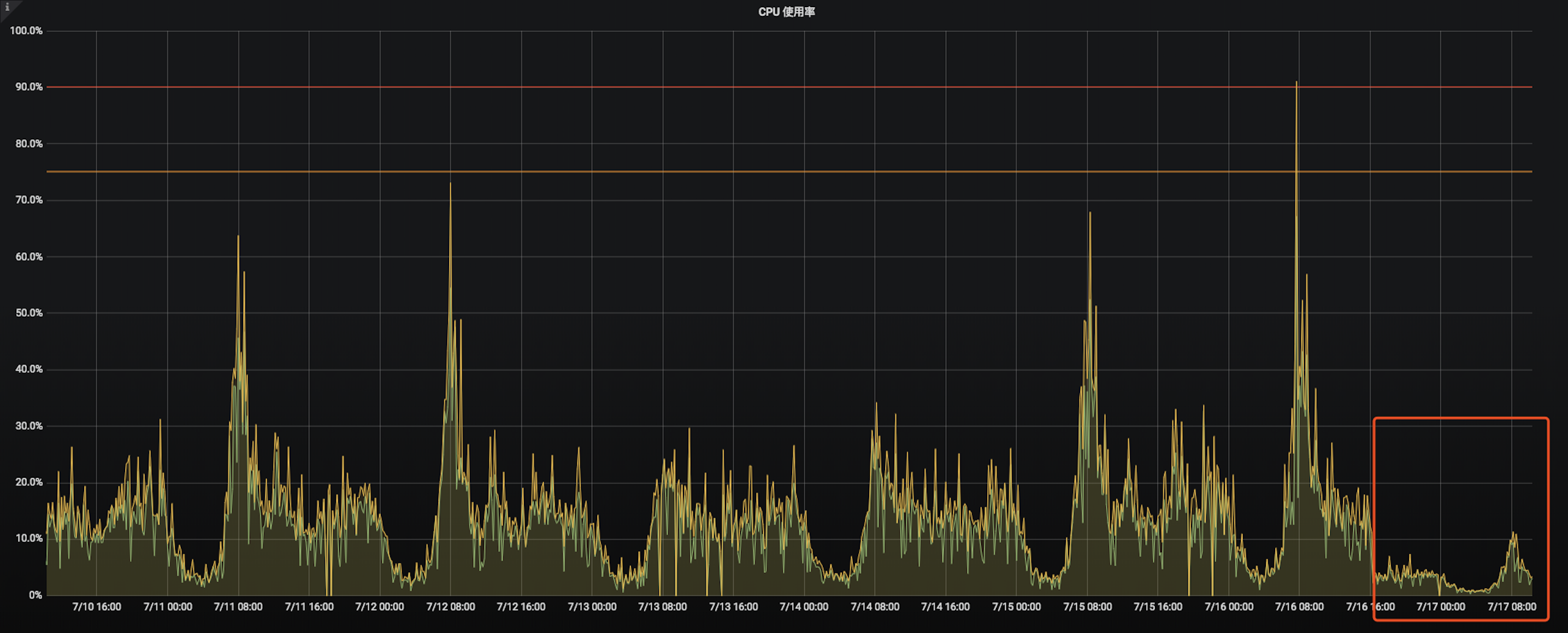
谨记。
