

This project's goal is the hosting of very large tables -- billions of rows X millions of columns
对比ES来学习。例如读写流程。
为什么要有hbase
mysql快吗?
- 高并发查询慢。单机查询非常快。B+树。
- 提高mysql效率的方式:分库分表,读写分离。
hbase
- 想提高效率就是充分使用内存。查询出来的结果也缓存在内存提高效率。
- 磁盘顺序读写。
- nosql,not only sql。
- 高可靠性(使用hdfs存储)、高性能、面向列。
- 利用MR分析hbase里的数据。使用ZK作为分布式协调服务。
- 主要存储非结构化和半结构化数据。(列存nosql数据库)
- 实时读写
hbase数据模型
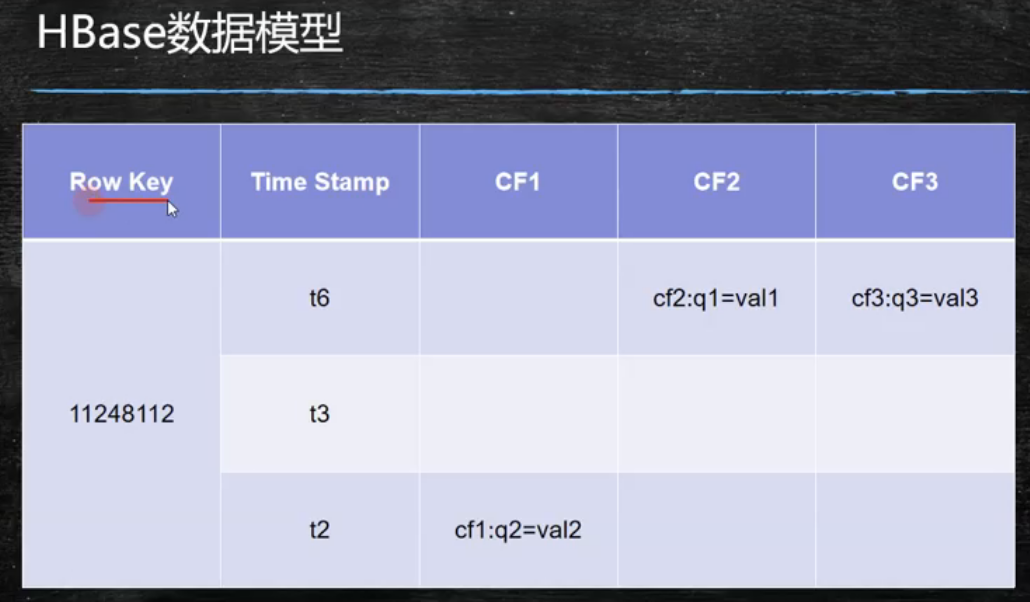
- row key 主键,字典序
- 时间戳---版本区别。
- CF列族。最小控制单元。列族中以后很多列。官方文档说列族不要超过2-3个。
- 默认取最新版本的记录。默认保留一个版本。落后版本只是给了失效标记。在文件合并的时候真正删除旧版本。
- rowkey 列族 列名 时间戳 这4个属性一起确定一个value
rowkey
- 决定一行的顺序。(唯一标识)
- 按照字典序排序。(查范围数据比单条数据多,rowkey需要设计。)
- 只能用64k的字节(实际上不用这么大,64k太大了,越短越好)
column family列族& qualifier 列
- 列族必须在创建表时给出。
- 列可以动态加入。
- 权限控制,存储及调优都是列族层面。
- 同一列族的数据在同一个目录下。由几个文件保存。
timestamp
- hbase每个cell存储单元对同一份数据有多个版本,根据时间戳来区分版本。按照时间戳倒序
- long类型 64位。
- 数据写入时自动赋予当前系统时间。
- 这个时间戳可以用户自己制定(UUID不行,因为按版本倒序排列),这个其实不用改。
- 旧的版本只是有了失效标记。
- 版本利用好可以解决问题。
cell单元格
- 单元格是有版本的
- 由{row key, column(列族+列名), version}确定
- cell中的数据是没有类型的(不像mysql需要指定是varchar int 等等),全部是字节数组存储。
hbase架构
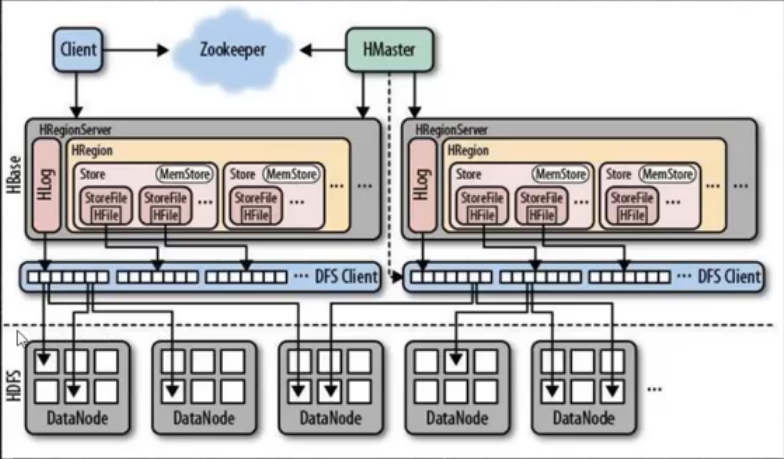
- 主备(HMaster) 高可用。
- 主从 主HMaster 从regionServer
- client提交请求到ZK,client和ZK没有直接相连,ZK中存的是部分元数据,比如元数据在hbase中存储地址。
- HLog WAL(类似mysql binlog,预写日志,ES里的translog)。
- 一个region是一个表的一部分,表里有很多store。一个store代表是一个列族
- 类似mysql有系统表的概念元数据存在hbase内部
client
包含访问hbase的接口并且维护cache(客户端的一点小缓存,和hbase集群没有关系)来加快对hbase的访问。
zookeeper
- 保证和master的高可用。
- 存储所有region的寻址入口。
- 实时监控HRegionServer的上下线信息。(regionServer是注册到ZK上的)ZK再通知HMaster。
- 存储少量的元数据
master
- 为region server分配region
- 负责region server 的负载均衡(防止数据倾斜,比如一张表的数据都在region server1上,那么region server2就空闲出来了。把这个表的一半数据分到region server2上,进行负载均衡)
- 发现失效的region server。并重新分配其上的region
- 管理用户对table的增删改的操作。
region server
- 维护region,处理这些region上的IO请求。
- region server负责切分(等分)大region。 映射上面master负责region server的负载均衡。
region
- 每个region会保存一个表中某段连续的数据。
- 每个表最开始都只在一个region里面。随着数据的增多,到一个阈值的时候,region会等分为两个region(裂变),分布在不同的
region server上。负载均衡。
memstore&storefile
- 一个region由多个store组成。一个store是一个列族。
- store位于memstore和storefile。
- 当memstore达到阈值(64MB)hregionserver会启动flashcache进程写入storefile(落盘)。每次都是产生一个新的storefile。
- 当storefile文件数量达到一定阈值后,系统会进行合并。在这个过程中会进行版本的合并和删除(对比ES中的segment merge)。持久化完成后,HLOG也会删除(oldWAL,两天后删除)
- 当一个region所有的storefile的大小和数量达到一个阈值后,会把当前的region分割为两个,并由
hmaster分配到相应的region server机器上实现负载均衡。
读写流程
- 第一次去ZK中拿元数据表存储的地址,在哪个RegionServer上。
- 第二次去上一步得到的RegionServer节点上通过元数据表获取目标表所在的RegionServer。
- 第三次去对应的RegionServer获取数据。
- 根据表的名称确定在哪个region上,再根据列族名确定在哪个store上。
写
- memstore内存(充分利用内存,非常非常快)
- 内存的数据是不安全的!
- memstore 64MB然后溢写,溢写完变成StoreFile。这时持久化完成。
- memstore也可以手动溢写(flush)到磁盘。多个磁盘上的小文件会进行compact。(分为minor compact(3~10个文件)和major compact(大范围))
memstore默认是64MB进行溢写。如果48MB了突然停电了怎么办?有HLog
- 每次写入先向HLog写。HLog**除了存数据还有操作!**还能补救。
- 写HLog也是用内存。
- 有一个LogSync的线程默认会盯着HLog。默认会一秒溢写一次HLog。
HLog是1s溢写一次,那么如果是0.5s的时候停电了呢。没办法了。丢就丢了。
- 一个store是一个列族
- storefile放在磁盘里的文件。(HFile和storefile等价,在hdfs里面就叫HFile。同一份文件在不同集群里的名称)
LSM树
读
- 先从memStore(写缓存)里读。
- 读也有缓存叫blockCache,如果memstore中没有数据的话去blockCache中读取。
- blockCache没有的话。最后才会去遍历storefile 文件(磁盘上),这时会把数据放入blockCache。以便下次能快点读。
- 避免select*,因为blockCache是LRU。
- blockCache占用堆内存的40%可以调。
更新过的数据如何确保读到。
- 从blockcache或者storefile中读取数据的时候,都是经过索引的。索引会维护版本。所以blockcache中是旧版本,新版本在storefile中。所以能保证是新的版本。
搭建
standalone
standalone所有的角色,master、regionserver、zookeeper都在一个JVM进程中,
持久化用的是本地文件系统而不是HDFS。
- 配置环境变量
HBASE_HOME - 修改
hbase-env.sh中的JAVA_HOME - 修改配置
conf/hbase-site.xml文档 bin/start-hbase.sh启动- webUI
node1:16010 hbase shell进入hbase命令行。
报异常了没起来。
Unhandled Java exception: java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
jline-xxx.jar这个包版本导致的。
完全分布式
- 四台机器时间得同步
- 所有机器配置免密。两个master放在1、4上。
hbase-env.sh里面export HBASE_MANAGES_ZK=false这个配置改为false。用单独的ZK集群。hbase-site.xml修改配置。
<configuration>
<!--持久化到hdfs上-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<!--分布式的-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--ZK集群-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node02,node03,node04</value>
</property>
</configuration>
- 在
regionservers中添加regionservers的信息。后三台机器。 - 高可用创建文件
backup-masters中添加内容node4。node4和其他机器包括自己进行免密 - 这块hbase作为hdfs的client需要有
hdfs-site.xml,copy it.
基本操作命令行
list_namespaces列出所有的命名空间。(类比数据库)list列出表。默认是default命名空间中的表。list_namespace_tables 'hbase'后面加命名空间。scan 'hbase:meta'获取数据。create 'psn','cf'创建了一个表名为psn的表,包含一个列族名为cf.create 'psn','cf1','cf2'创建表,包含多个列族describe 'psn1'列族的描述信息put 'psn1','1','cf1:name','zhagnsan'添加数据,需要四个参数分别为- 表名
- row key
- 列族+列名
- value
- 一次只能插入一个列。
- row key是字典序。1<11<2。(每次put新的数据进去会进行排序)
- 删除一个表。需要先disabled它。
/hbase/data/default/psn/59c9d640783515e2bbee87e6fe301135/cf中间59xxx是region的id。因为一张表有多个region组成。- 插入数据后,数据还在memstore中,还没有持久化。所以hdfs中看不到数据。手动
flush 'psn'就能看到文件了。由于是sequence file人类不可读。
hbase hfile -p -f hdfs://mycluster/hbase/data/default/psn/59c9d640783515e2bbee87e6fe301135/cf/4ef8e42ab6074f52af46c9884692f912
这个命令能解析持久化的文件。 如下KV
K: 1/cf:name/1565192379842/Put/vlen=4/seqid=4 V: kobe
java client
确保版本
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-clent -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.0.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
创建表
// 创建表需要标明和至少一个列族名。
@Test
public void createTable() throws IOException {
TableName tableName = TableName.valueOf("javaCLI");
TableDescriptorBuilder javaCLI = TableDescriptorBuilder.newBuilder(tableName);
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder("name".getBytes());
javaCLI.setColumnFamily(columnFamilyDescriptorBuilder.build());
// 判断表是否存在。存在就删除
if(admin.tableExists(tableName)){
// 删除前 要禁用掉
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
admin.createTable(javaCLI.build());
}
storefile合并问题
<!--1秒进行一次合并-->
<property>
<name>hbase.server.thread.wakefrequency</name>
<value>1</value>
</property>
<property>
<name>hbase.server.compactchecker.interval.multiplier</name>
<value>1</value>
</property>
insert
@Test
public void insert() throws IOException {
Table table = connection.getTable(tableName);
// 创建一个PUT对象。里面指定row key
Put put = new Put(Bytes.toBytes("1"));
// 指定列族,列名,value
put.addColumn(Bytes.toBytes("name"),Bytes.toBytes("first"),Bytes.toBytes("obsidian"));
put.addColumn(Bytes.toBytes("name"),Bytes.toBytes("last"),Bytes.toBytes("huo"));
table.put(put);
}
GET
/**
* hbase是十亿级别的行和百万级别的列。
* 如果不限制列,那么会产生巨大的IO。
* @throws IOException
*/
@Test
public void get() throws IOException {
Get get = new Get(Bytes.toBytes("1"));
// 限制了列族 为 name 限制了列名 为 last
get.addColumn(Bytes.toBytes("name"),Bytes.toBytes("last"));
Result result = table.get(get);
Cell cell1 = result.getColumnLatestCell(Bytes.toBytes("name"), Bytes.toBytes("last"));
byte[] last = CellUtil.cloneValue(cell1);
System.out.println("last:"+Bytes.toString(last));
Cell cell2 = result.getColumnLatestCell(Bytes.toBytes("name"), Bytes.toBytes("first"));
byte[] first = CellUtil.cloneValue(cell2);
System.out.println("first:"+Bytes.toString(first));
}
scan
blockcache也没有那么脆弱。分为三块,里面根据热度不同来存放数据。
通话记录查询实例
- 背景:去营业厅查10年前的手机通话记录。
- 手机号,通话时间,对方号码,主叫/被叫。
- rowkey设计。充分利用字典序的特性。
rowkey设计:
因为通常查询是查我的手机号在某段时间的通话记录。
所以手机号放前,时间戳放后。
手机号可以翻转,防止数据倾斜。
由于最新的通话记录应该在上面显示。时间戳应该用倒序。用Long.MAX-时间戳
/**
* 插入10个人的通话记录每个人1W条。
*/
@Test
public void insertPhone() throws Exception {
List<Put> puts = new ArrayList<>();
for (int i = 0; i < 10; i++) {
// 电话号码 158开头后面随机
String phone = getPhone("158");
for (int j = 0; j < 10000; j++) {
long when = getDate();
// 对方的电话号码 199开头后面随机
String otherPhone = getPhone("199");
// 通话时长 0~99分钟
String times = String.format("%02d", RANDOM.nextInt(99));
int type = RANDOM.nextInt(2);
// row_key设计
String rowKey = phone + (Long.MAX_VALUE - when);
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("otherPhone"), Bytes.toBytes(otherPhone));
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("times"), Bytes.toBytes(times));
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("type"), Bytes.toBytes(type));
puts.add(put);
}
}
// 批量添加
table.put(puts);
}
/**
* 查找通话记录 15893253565 三月 的通话记录
*/
@Test
public void scanPhone() throws Exception {
Scan scan = new Scan();
String startTime = "15893253565_" + (Long.MAX_VALUE - SDF.parse("20190332000000").getTime());
String endTime = "15893253565_" + (Long.MAX_VALUE - SDF.parse("2019030000000").getTime());
scan.withStartRow(Bytes.toBytes(startTime));
scan.withStopRow(Bytes.toBytes(endTime));
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
Cell otherPhone = result.getColumnLatestCell(Bytes.toBytes("cf"), Bytes.toBytes("otherPhone"));
Cell times = result.getColumnLatestCell(Bytes.toBytes("cf"), Bytes.toBytes("times"));
Cell type = result.getColumnLatestCell(Bytes.toBytes("cf"), Bytes.toBytes("type"));
byte[] bytes = CellUtil.cloneValue(otherPhone);
// 得到 rowKey
String row = Bytes.toString(result.getRow());
String[] strings = row.split("_");
// 各种解析 打印
System.out.println(strings[0] + "_" + new Date(Long.MAX_VALUE - Long.valueOf(strings[1])) + ":"
+ Bytes.toString(CellUtil.cloneValue(otherPhone)) + ":" + Bytes.toString(CellUtil.cloneValue(times))
+ ":"
+ Bytes.toString(CellUtil.cloneValue(type)));
}
}
/**
* 查出是主叫的 type 为1
*/
@Test
public void scanWithFilter() throws IOException {
Scan scan = new Scan();
FilterList filterList = new FilterList();
SingleColumnValueFilter scv = new SingleColumnValueFilter(Bytes.toBytes("cf"), Bytes.toBytes("type"),
CompareOperator.EQUAL, Bytes.toBytes("1"));
filterList.addFilter(scv);
// 前缀过滤器
PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes("15893253565"));
filterList.addFilter(prefixFilter);
scan.setFilter(filterList);
ResultScanner scanner = table.getScanner(scan);
}
安装常用开发工具包 yum groupinstall "Development tools"
protobuf
- 序列化工具。不能用过滤器搜索了,热数据不能用。
hbase MR
//从hdfs计算Wordcount,然后结果写入hbase。
public class HbaseWC {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration(true);
configuration.set("hbase.zookeeper.quorum", "node2,node3,node4");
configuration.set("mapreduce.app-submission.cross-platform", "true");
configuration.set("mapreduce.framework.name", "local");
Job job = Job.getInstance(configuration);
// mapper
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// reducer 这里面指定了hbase的表名,最后一个值传入的是false是因为在本地运行的MR。
TableMapReduceUtil.initTableReducerJob("wc", WCReducer.class, job, null, null, null, null, false);
job.setOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Put.class);
FileInputFormat.addInputPath(job, new Path("/wc/wc.txt"));
job.waitForCompletion(true);
}
}
// 和往常一样的Mapper
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split(" ");
for (String token : tokens) {
context.write(new Text(token), new IntWritable(1));
}
}
}
// -----------reducer---------------
public class WCReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum++;
}
// 一个组 put一次。
Put put = new Put(key.toString().getBytes());
put.addColumn("cf".getBytes(), "count".getBytes(), String.valueOf(sum).getBytes());
// 这里为什么是null。因为源码中没有用过这个key。
context.write(null, put);
}
}
// 从hbase读,写入hdfs
public class WC {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration(true);
conf.set("hbase.zookeeper.quorum", "node2,node3,node4");
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapreduce.framework.name", "local");
Job job = Job.getInstance(conf);
Scan scan = new Scan();
scan.setCaching(500);
scan.setCacheBlocks(false);
TableMapReduceUtil.initTableMapperJob("wc", scan, MyMapper.class, Text.class, IntWritable.class, job, false);
job.setReducerClass(MyReducer.class);
FileOutputFormat.setOutputPath(job, new Path("/wc/result"));
boolean b = job.waitForCompletion(true);
if (!b) {
throw new Exception("有问题");
}
}
}
//-------------mapper-------------
//这泛型只有两个,因为输入的KV 指定好了是ImmutableBytesWritable、Result
public class MyMapper extends TableMapper<Text, IntWritable> {
static byte[] family = "cf".getBytes();
static byte[] qualify = "count".getBytes();
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
Cell cell = value.getColumnLatestCell(family, qualify);
byte[] bytes = CellUtil.cloneValue(cell);
context.write(new Text(key.get()), new IntWritable(Integer.valueOf(Bytes.toString(bytes))));
}
}
//-------------reducer-------------
public class MyReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for(IntWritable i:values){
context.write(key,i);
}
}
}
源码分析
hbase表设计
- 从关系型数据库转换思想。
多对多
人员角色表:
人员有多个角色,角色有优先级。
角色有多个人员。
人员 删除添加角色
角色 添加删除人员
人员 添加删除
角色 添加删除
-------------两张表-------------------
人员表
rowkey cf1:人员属性 cf2:角色列表
001(pid) cf1:name=xxx(人员相关属性) cf2:100=10,cf2:200=9(角色和角色优先级)
角色表
rowkey cf1:角色属性 cf2:人员列表
100(rid) cf1:name=xxx cf2:001=小黑,cf2:002=小白
删除人员中的角色时,需要同时删除角色中的人员。触发器。
一对多
组织架构 部门-子部门
查询 顶级部门
查询 每个部门的所有子部门
部门 添加、删除子部门
部门 添加、删除
微博表设计
微博不是用的hbase,用的redis
关注和粉丝表:
rowkey(pid) cf:(关注列表) cf:(粉丝列表)
001 cf:002=小黑 cf:002=小黑,cf:003=小白
002 cf:001=小红 cf:003=小白
003 cf:001=小红 cf:002=小黑
微博表,时间倒叙,新的微博在前面,不考虑热度。查看一个人的微博
rowkey(wid) cf:(微博信息)
pid_(long.max_value-timestamp) cf:content,cf:title
微博收取表。所有人的微博按顺序
rowkey(wid) cf:(所有关注人发布的微博)version=10000
pid cf:sq=wid3
cf:sq=wid2
cf:sq=wid1
巧!!!!!!妙运用版本信息。每个人的新微博增加版本。
