

介绍
用过riot.js的都知道,他是一个依托于自定义模板的JS框架,自定义模板都是采用.tag文件(版本4改成了.riot),这类文件对于浏览器来说是识别不了的,必须要有一个工具将他们编译成js文件。
riot.compile 就是将他的.tag(@v3)/.riot(@v 4)模板文件编译成浏览器可以识别的js代码的函数(我们主要研究版本3的源码)。
用法
riot提供了2种编译方式,浏览器端和服务端(node):
服务端(node端):
node 端比较简单:
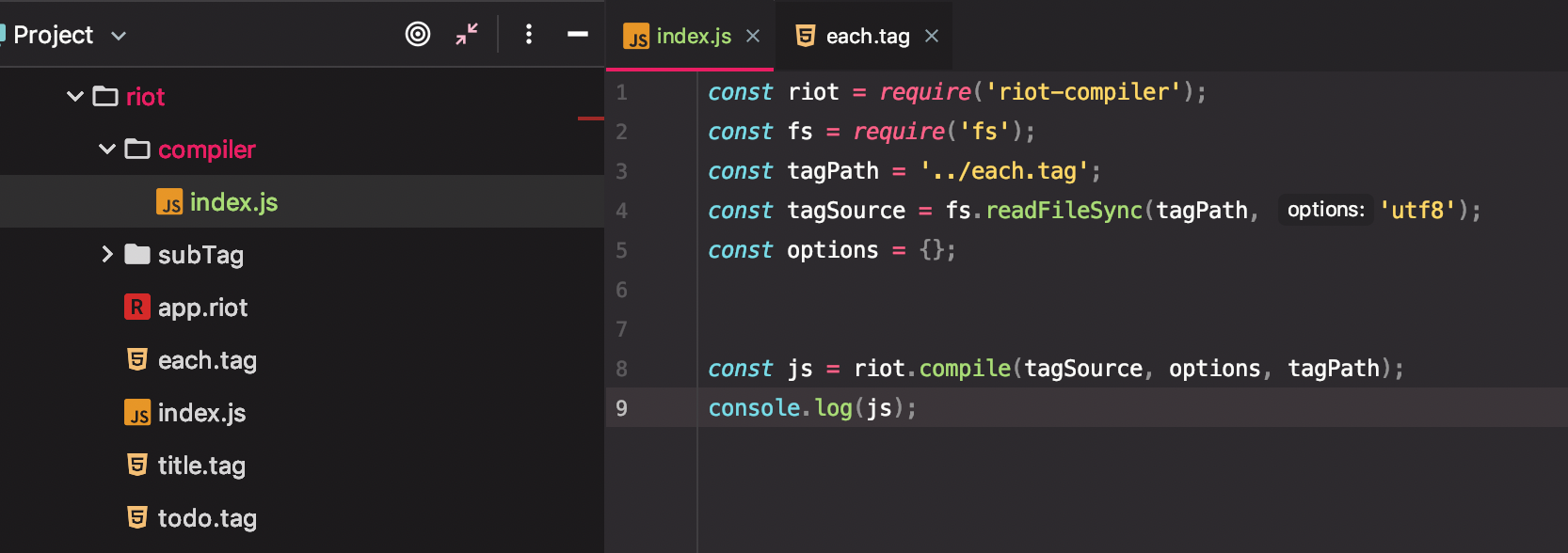
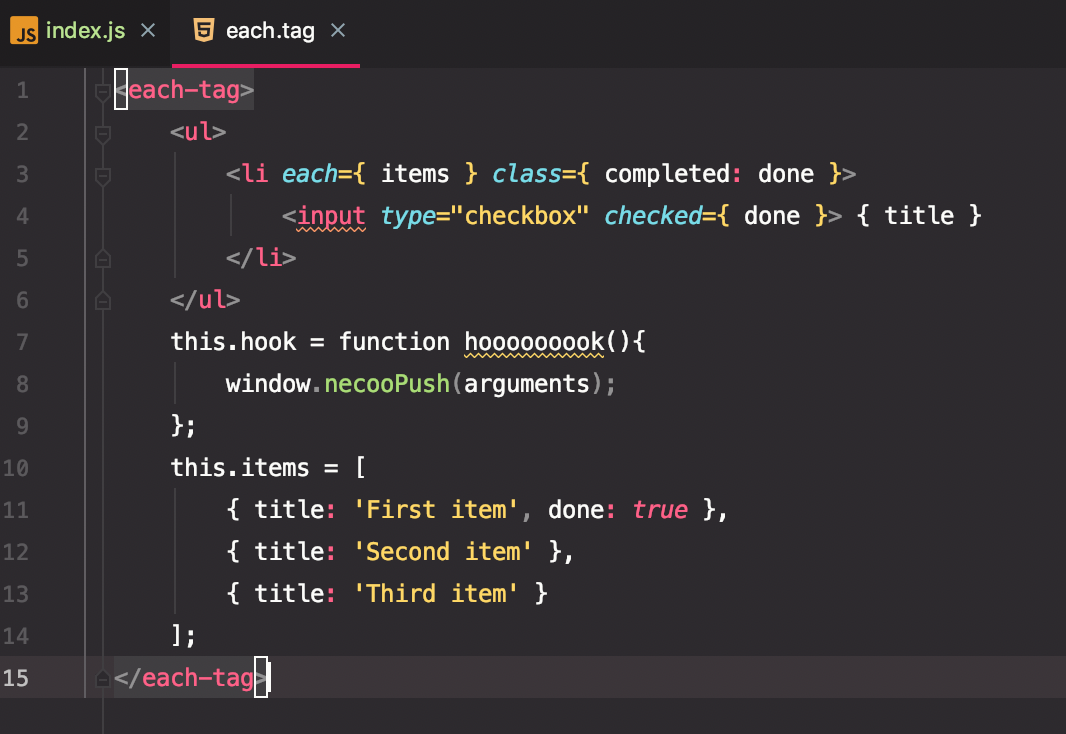
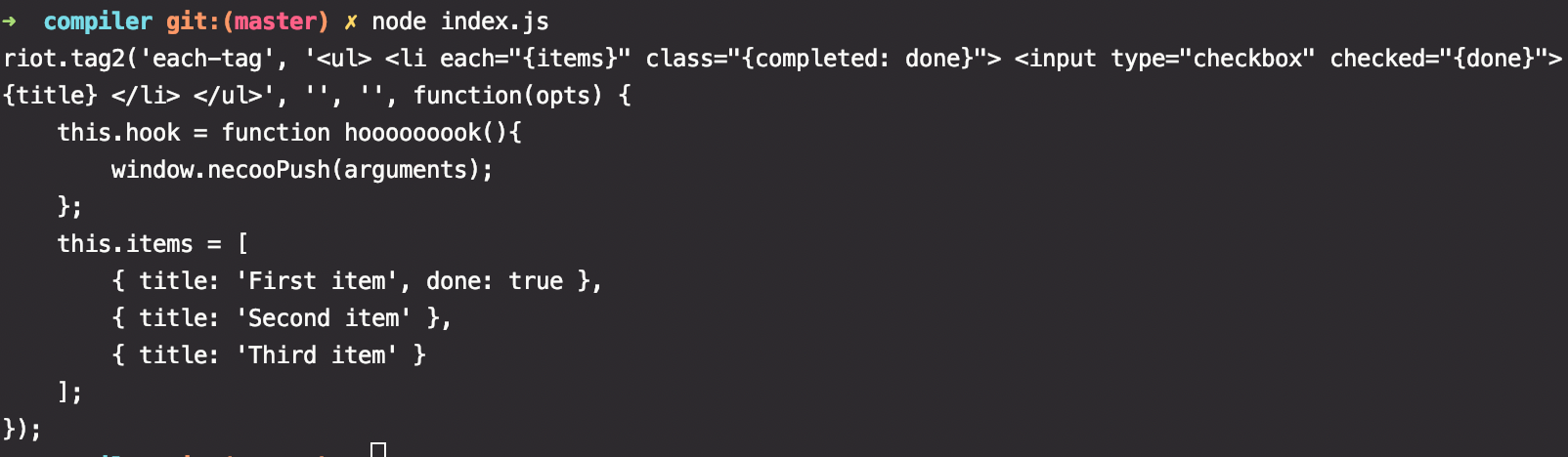
可以看到它其实是把模板文件转成了一个执行函数形式的字符串,字符串内容:
riot.tag2('each-tag', '<ul> <li each="{items}" class="{completed: done}"> <input type="checkbox" checked="{done}"> {title} </li> </ul>', '', '', function(opts) {
this.hook = function hooooooook(){
window.necooPush(arguments);
};
this.items = [
{ title: 'First item', done: true },
{ title: 'Second item' },
{ title: 'Third item' }
];
});
那么有人就要问了,riot.tag2是干嘛的,在这里我先简单讲下他的参数和作用:
- 参数:
riot.tag2(模板标签名字,模板的html部分字符串,模板的CSS部分字符串,模板的属性,模板里的js代码) - 作用:
就是把传入的4个参数存到(伪)全局变量__TAG_IMPL中,
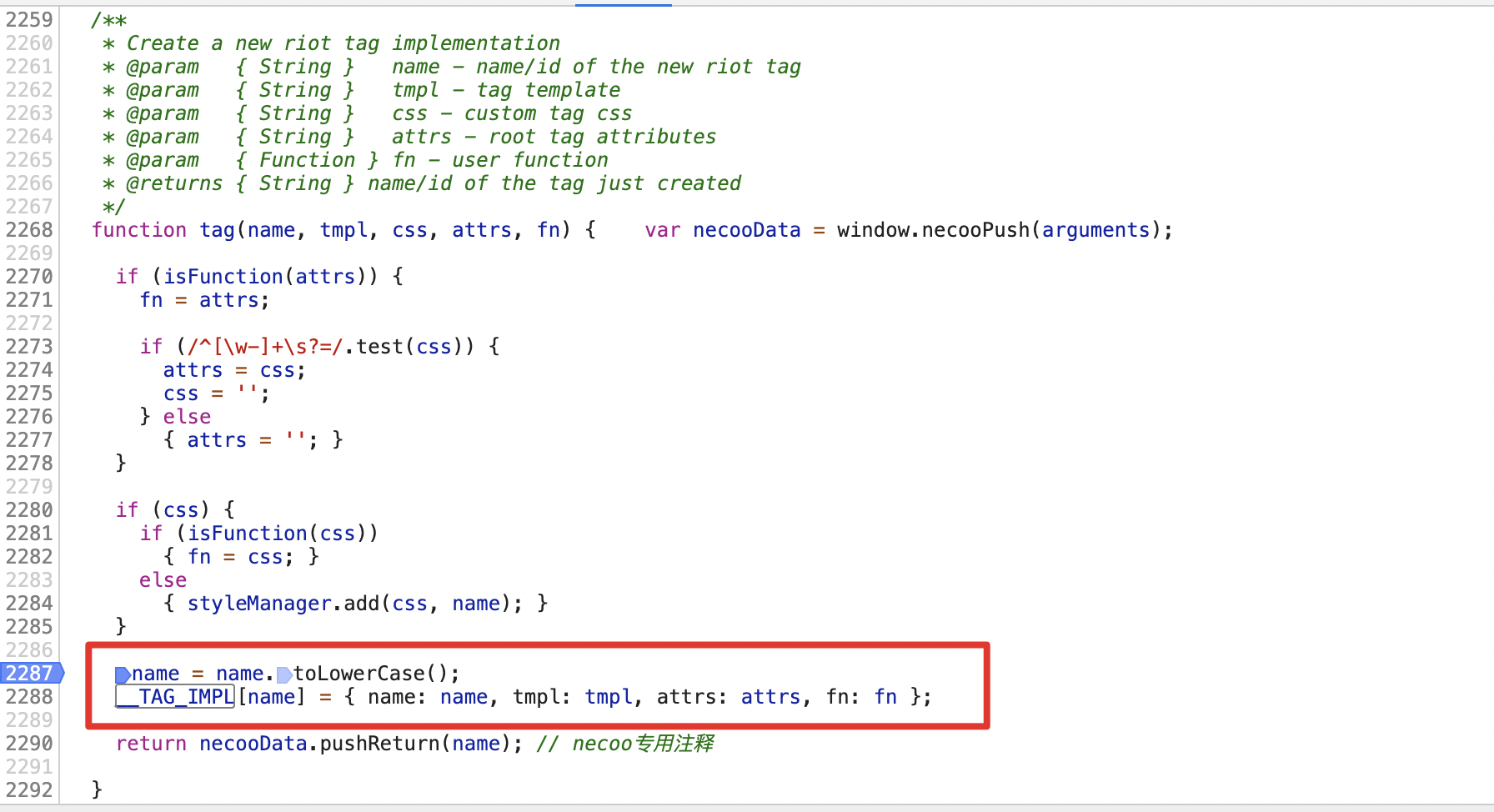
把生成的这个字符串丢到each.js文件中:
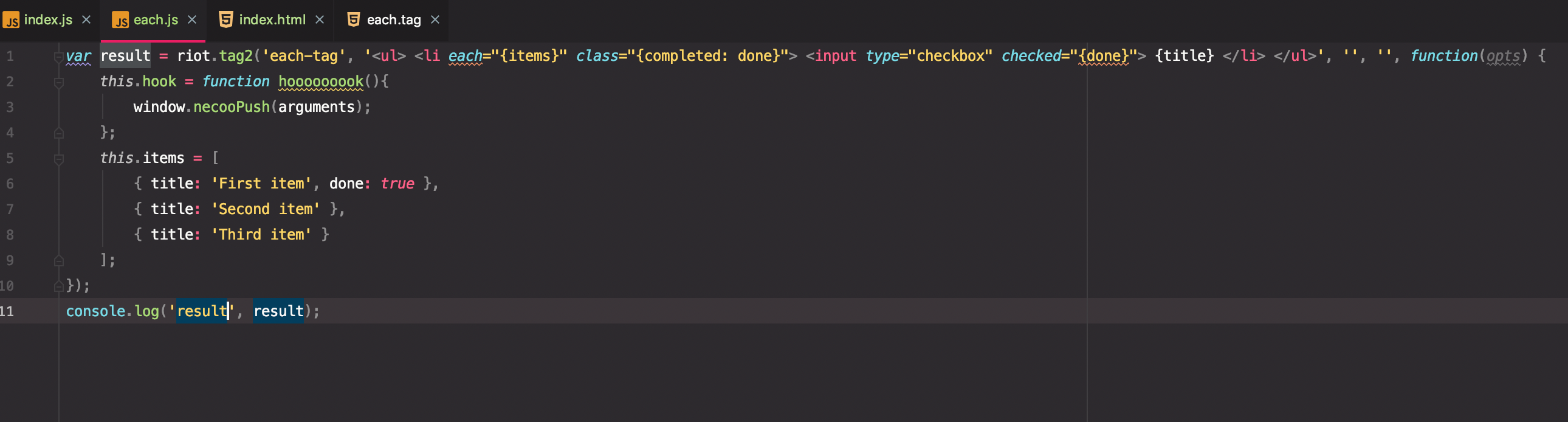
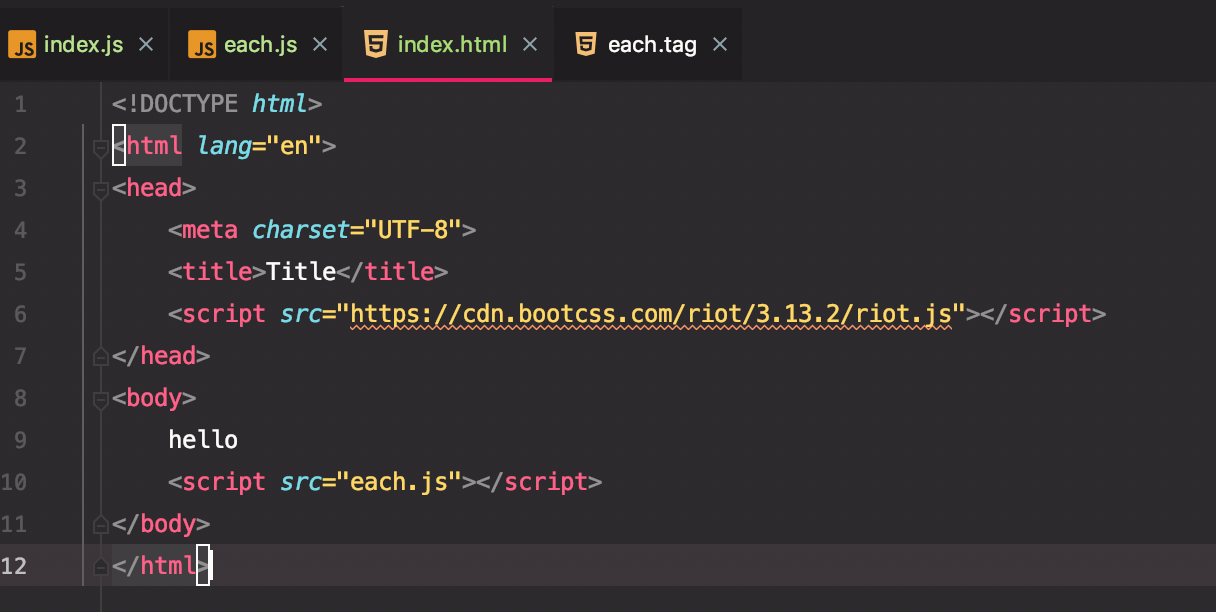
可以看到浏览器是可以正常执行的(riot.tag2函数执行后返回的是自定义标签的名字):

如果我们直接引入each.tag文件,浏览器绝对会报错:

所以我们理一下riot.compile(node端)的作用:.tag => 【riot.compile】 => 【riot.tag2(...)字符串】,这个过程叫做预编译,在我们项目中现在采用的都是这种预编译模式,我们npm run dev/build的时候其实都是把项目中所有的.tag文件转换成.js文件,然后最终打入dist.js中,html再引入这个文件,即可以访问到我们需要的模板
浏览器端编译
其实浏览器端的编译在我看来并没有什么卵用,他的用法:



需要注意的是前面三种用法都会直接执行编译出来的riot.tag2函数
源码分析
浏览器端编译和node端编译原理其实是一样的,我们只需分析一下浏览器端的源码即可。分析过程中使用到的源码分析辅助工具是 necoo-loader,欢迎star 😉😂😂😂😂😂
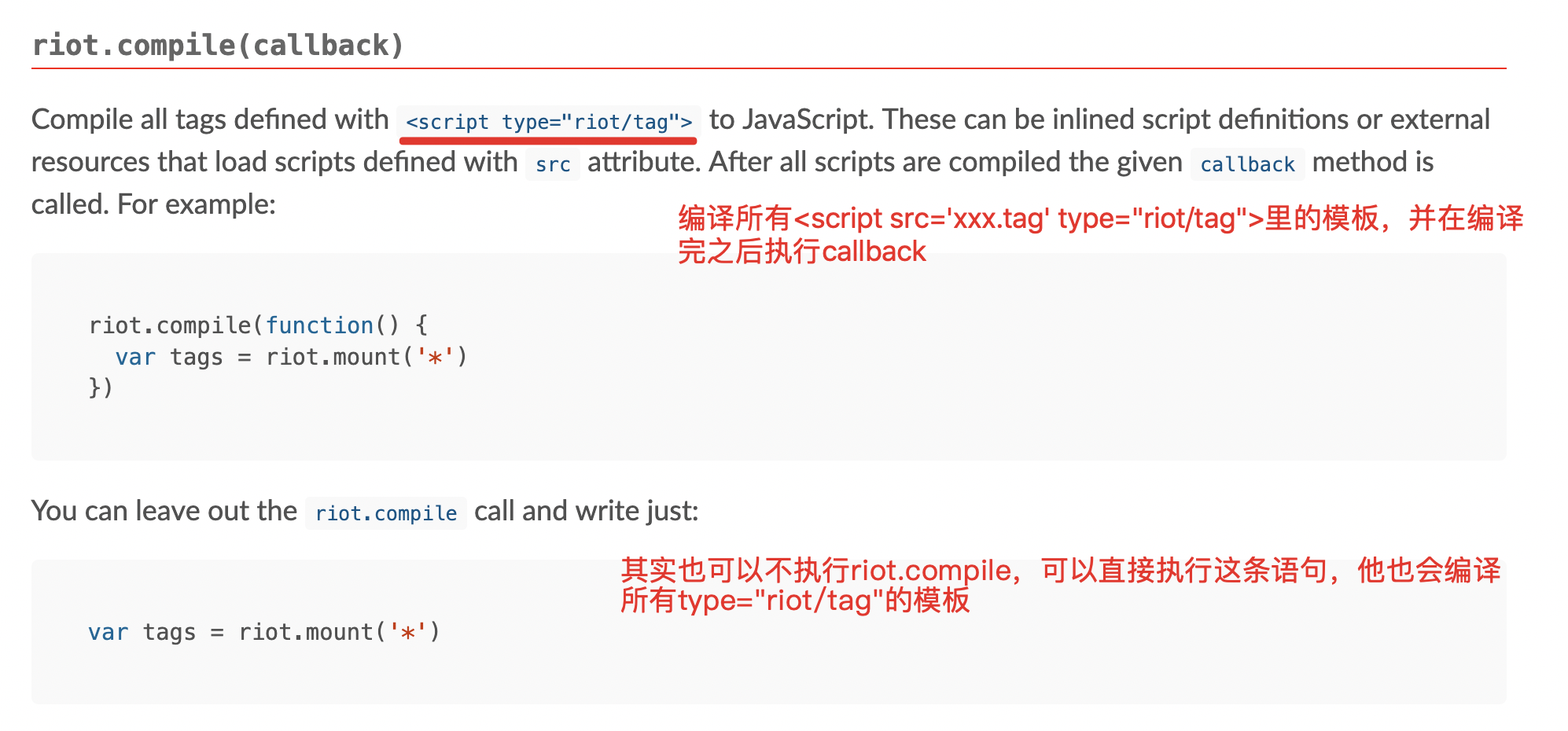
riot.compile(callback)
我们的demo代码(demo越简单越好)如下:
import riot from 'riot';
// necoo-loader专用
window.necooIndex = 0;
// riot.compile(callback)
riot.compile(function comileHook() {
});
假如页面上一个<script type="riot/tag">标签都没,他的代码执行顺序是这样的:
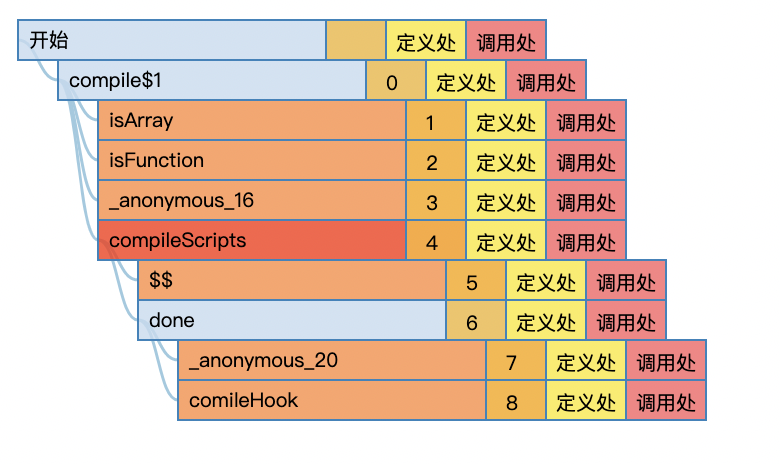
我们需要关注2个核心函数: compile$1和compileScript
/*
Compilation for the browser
*/
function compile$1(arg, fn, opts) {
if (typeof arg === T_STRING) {
// 2nd parameter is optional, but can be null
if (isObject(fn)) {
opts = fn;
fn = false;
} // `riot.compile(tag [, callback | true][, options])`
if (/^\s*</m.test(arg)) {
var js = compiler.compile(arg, opts);
if (fn !== true) {
globalEval(js);
}
if (isFunction(fn)) {
fn(js, arg, opts);
}
return js
} // `riot.compile(url [, callback][, options])`
GET(arg, function _anonymous_88(str, opts, url) {
var js = compiler.compile(str, opts, url);
globalEval(js, url);
if (fn) {
fn(js, str, opts);
}
}, opts);
} else if (isArray(arg)) {
var i = arg.length; // `riot.compile([urlsList] [, callback][, options])`
arg.forEach(function _anonymous_89(str) {
GET(str, function _anonymous_90(str, opts, url) {
var js = compiler.compile(str, opts, url);
globalEval(js, url);
i--;
if (!i && fn) {
fn(js, str, opts);
}
}, opts);
});
} else {
// `riot.compile([callback][, options])`
if (isFunction(arg)) {
opts = fn;
fn = arg;
} else {
opts = arg;
fn = undefined;
}
if (ready) {
return fn && fn()
}
if (promise) {
if (fn) {
promise.on('ready', fn);
}
} else {
promise = observable();
compileScripts(fn, opts);
}
}
} // it can be rewritten by the user to handle all the compiler errors
function compileScripts(fn, xopt) {
var scripts = ?('script[type="riot/tag"]'),
scriptsAmount = scripts.length;
function done() {
promise.trigger('ready');
ready = true;
if (fn) {
fn();
}
}
function compileTag(src, opts, url) {
var code = compiler.compile(src, opts, url);
globalEval(code, url);
if (! --scriptsAmount) {
done();
}
}
if (!scriptsAmount) {
done();
} else {
for (var i = 0; i < scripts.length; ++i) {
var script = scripts[i],
opts = extend({
template: getAttribute(script, 'template')
}, xopt),
url = getAttribute(script, 'src') || getAttribute(script, 'data-src');
url ? GET(url, compileTag, opts) : compileTag(script.innerHTML, opts);
}
}
}
我们发现,其实他是这样的:
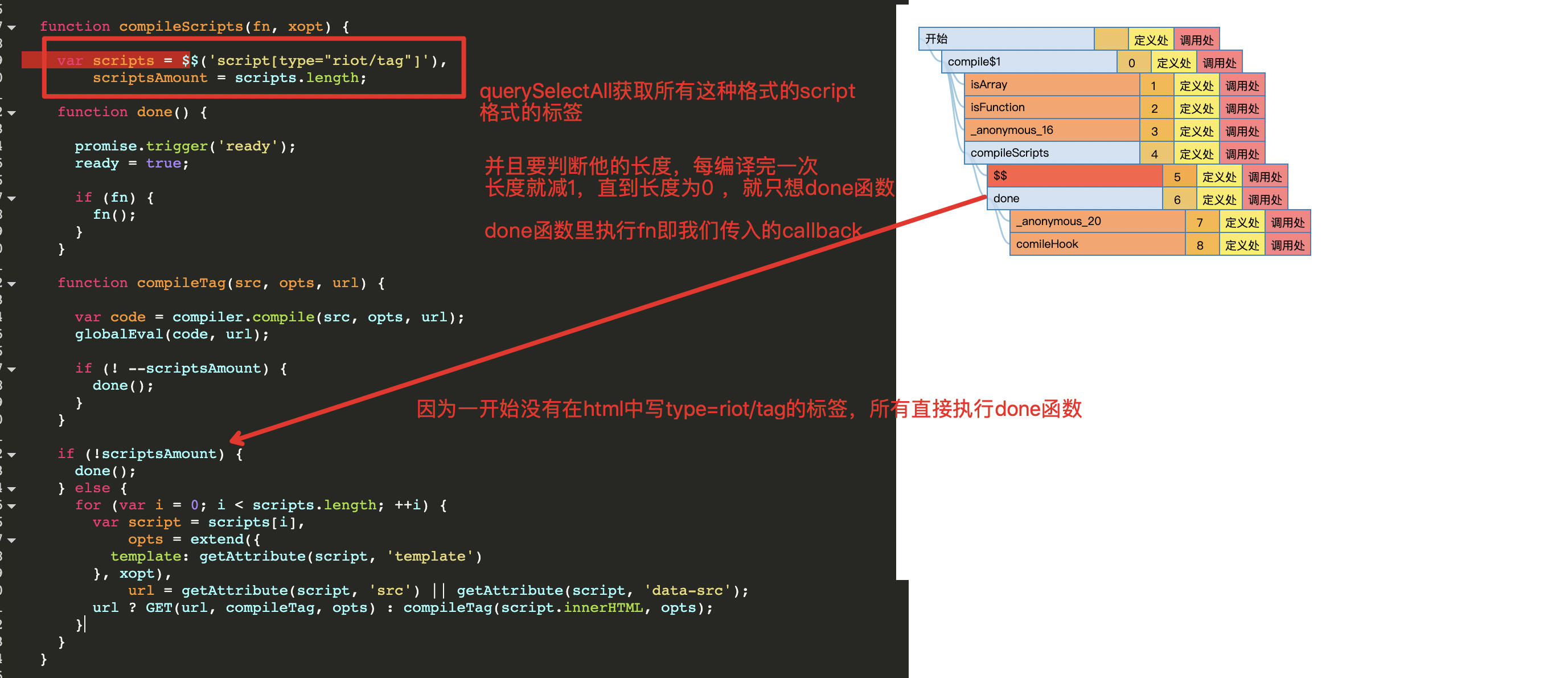
当我们在页面中写入一个标签:

这个时候再看执行轨迹,我们发现,有几个重要函数出现:
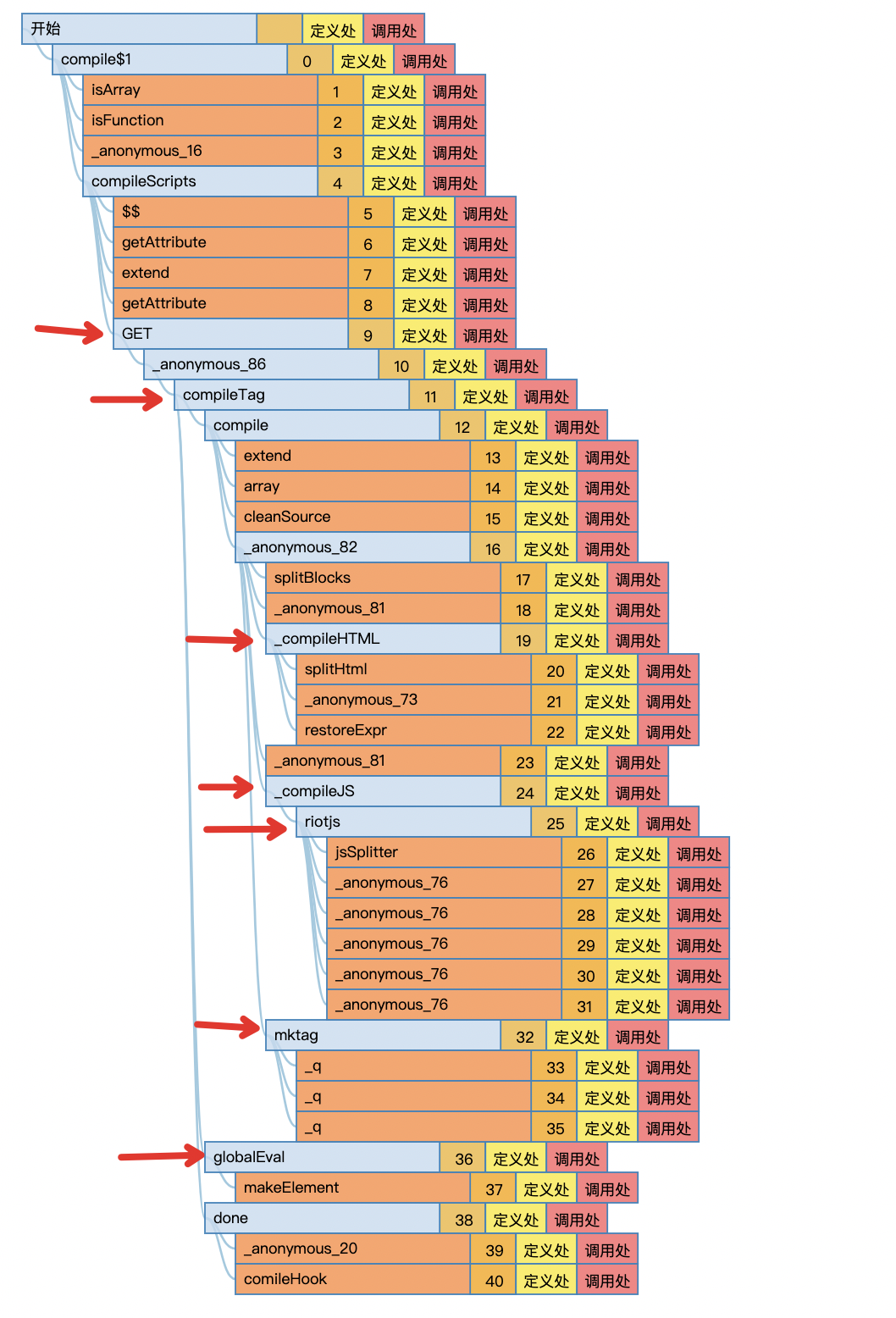
GET
原来原理就是使用ajax get请求去获取url内的内容
function GET(url, fn, opts) {
var req = new XMLHttpRequest();
req.onreadystatechange = function _anonymous_86() {
if (req.readyState === 4) {
if (req.status === 200 || !req.status && req.responseText.length) {
fn(req.responseText, opts, url);
} else {
compile$1.error("\"" + url + "\" not found");
}
}
};
req.onerror = function _anonymous_87(e) {
return compile$1.error(e)
};
req.open('GET', url, true);
req.send('');
} // evaluates a compiled tag within the global context
compile
编译GET函数获取的字符串:
获取到内容后,再传给compile函数解析:
function compile(src, opts, url) {
var parts = [],
included,
output = src,
defaultParserptions = {
template: {},
js: {},
style: {}
};
if (!opts) {
opts = {};
}
opts.parserOptions = extend$1(defaultParserptions, opts.parserOptions || {});
included = opts.exclude ? function _anonymous_80(s) {
return opts.exclude.indexOf(s) < 0
} : function _anonymous_81() {
return 1
};
if (!url) {
url = '';
}
var _bp = brackets.array(opts.brackets);
if (opts.template) {
output = compileTemplate(output, url, opts.template, opts.parserOptions.template);
}
output = cleanSource(output).replace(CUST_TAG, function _anonymous_82(_, indent, tagName, attribs, body, body2) {
var jscode = '',
styles = '',
html = '',
imports = '',
pcex = [];
pcex._bp = _bp;
tagName = tagName.toLowerCase();
attribs = attribs && included('attribs') ? restoreExpr(parseAttribs(splitHtml(attribs, opts, pcex), pcex), pcex) : '';
if ((body || (body = body2)) && /\S/.test(body)) {
if (body2) {
if (included('html')) {
html = _compileHTML(body2, opts, pcex);
}
} else {
body = body.replace(RegExp('^' + indent, 'gm'), '');
body = body.replace(SCRIPTS, function _anonymous_83(_m, _attrs, _script) {
if (included('js')) {
var code = getCode(_script, opts, _attrs, url);
if (code) {
jscode += (jscode ? '\n' : '') + code;
}
}
return ''
});
body = body.replace(STYLES, function _anonymous_84(_m, _attrs, _style) {
if (included('css')) {
styles += (styles ? ' ' : '') + cssCode(_style, opts, _attrs, url, tagName);
}
return ''
});
var blocks = splitBlocks(body.replace(TRIM_TRAIL, ''));
if (included('html')) {
html = _compileHTML(blocks[0], opts, pcex);
}
if (included('js')) {
body = _compileJS(blocks[1], opts, null, null, url);
if (body) {
jscode += (jscode ? '\n' : '') + body;
}
jscode = jscode.replace(IMPORT_STATEMENT, function _anonymous_85(s) {
imports += s.trim() + '\n';
return ''
});
}
}
}
jscode = /\S/.test(jscode) ? jscode.replace(/\n{3,}/g, '\n\n') : '';
if (opts.entities) {
parts.push({
tagName: tagName,
html: html,
css: styles,
attribs: attribs,
js: jscode,
imports: imports
});
return ''
}
return mktag(tagName, html, styles, attribs, jscode, imports, opts)
});
if (opts.entities) {
return parts
}
return output
}
在compile中,他会先cleanSource => _compileHTML => _compileJS => mktag,
我们用中文翻译过来就是,清理源码 => 编译html => 编译js => 制作tag,
接下来我们分析一下细节:
cleanSource
cleanSource就是清除注释啥的

看下exec的解释:
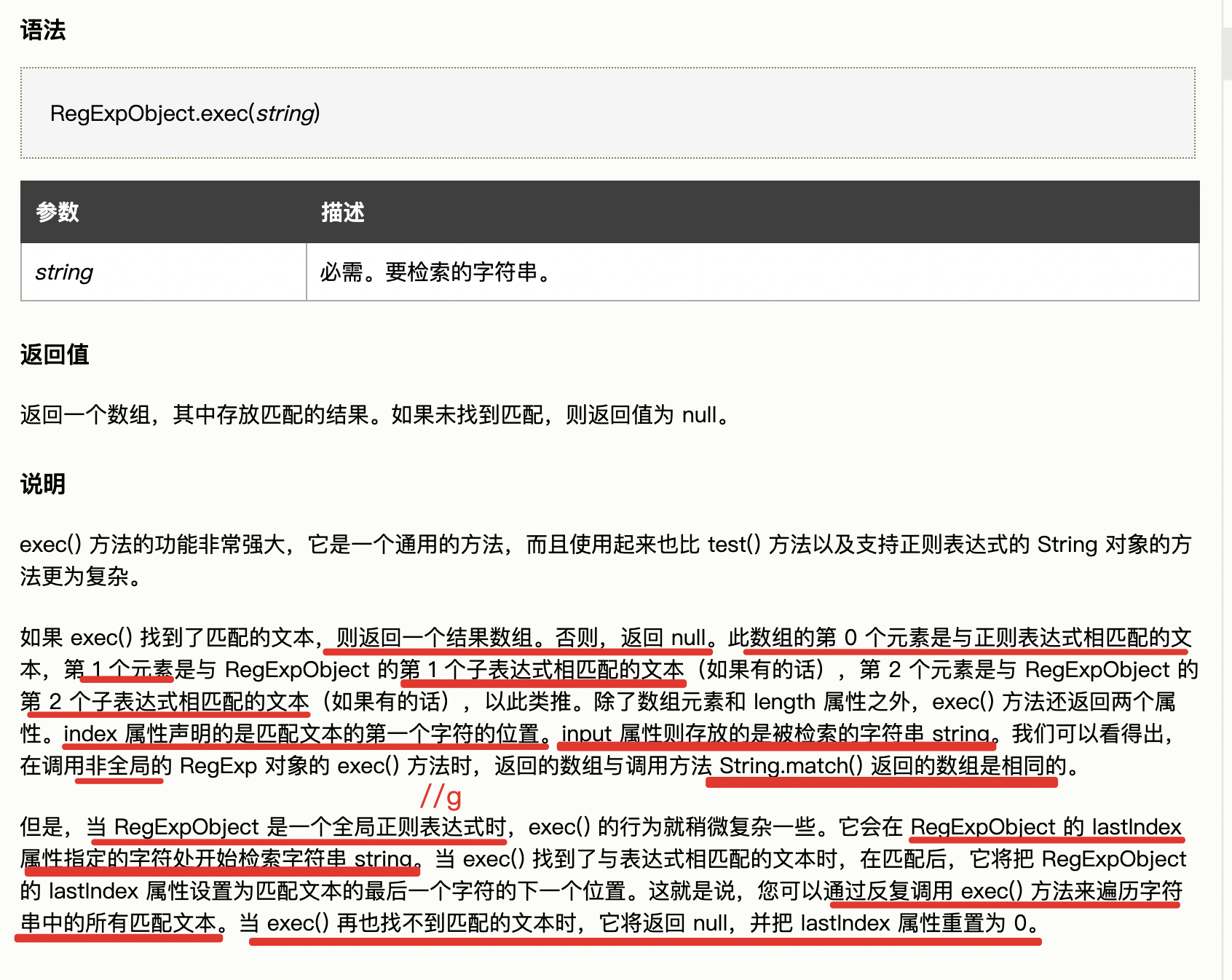
所以mm[0][0]表示的是匹配中的字符串的第一个字符。
再看下这个函数的输入输出:
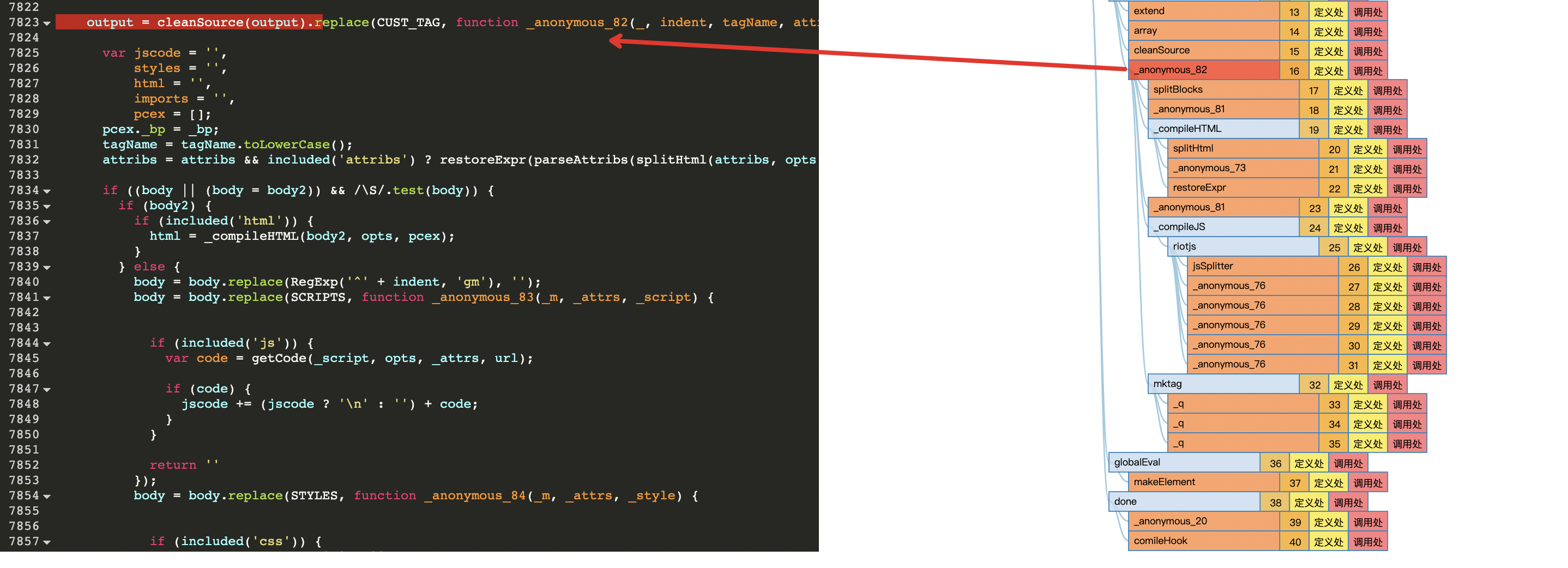

我们先看下参数的英文解释应该是啥:
- _: 匹配中的字符串本身
- indent: 缩进
- tagName: 标签名
- attribs: 属性
- body: 不知道
- body2: 不知道
再看下这个正则的值:
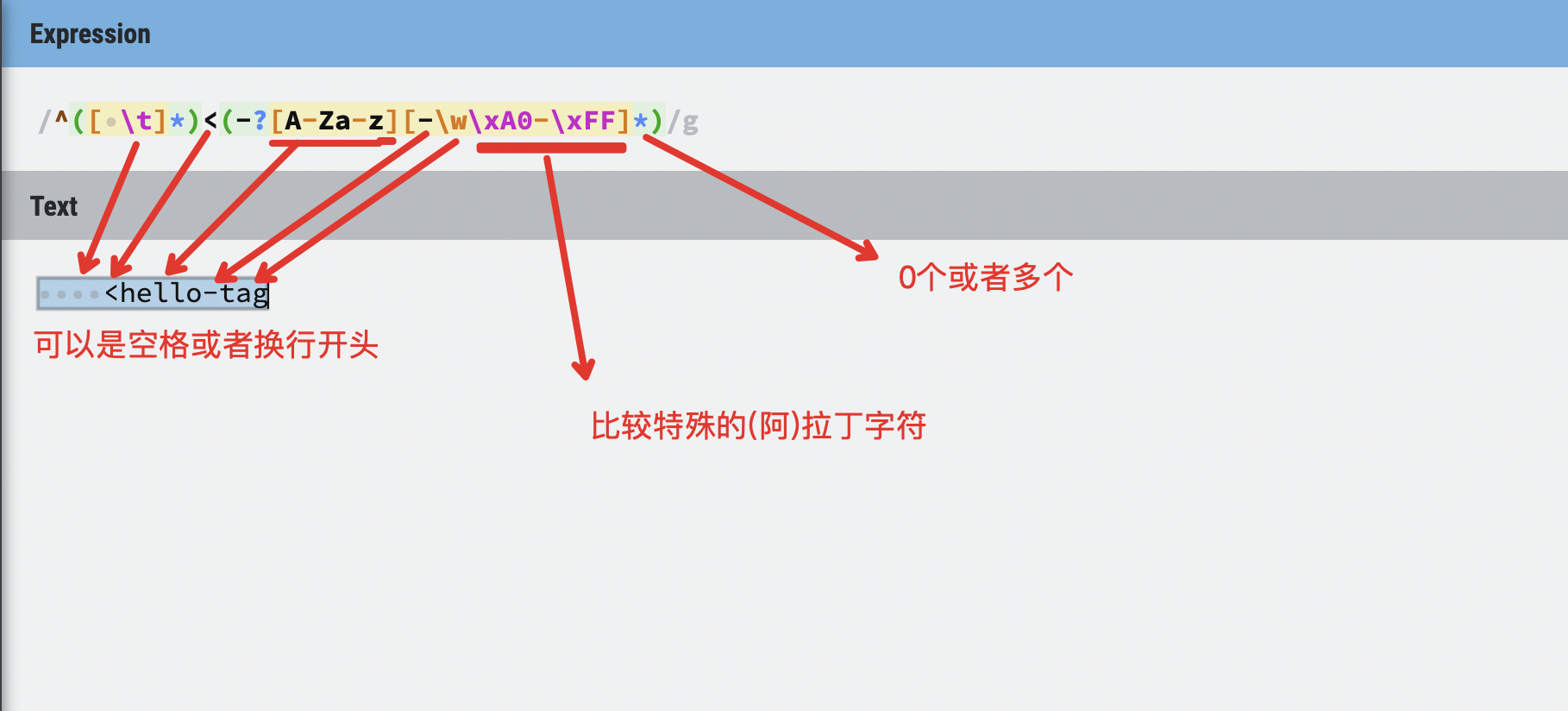
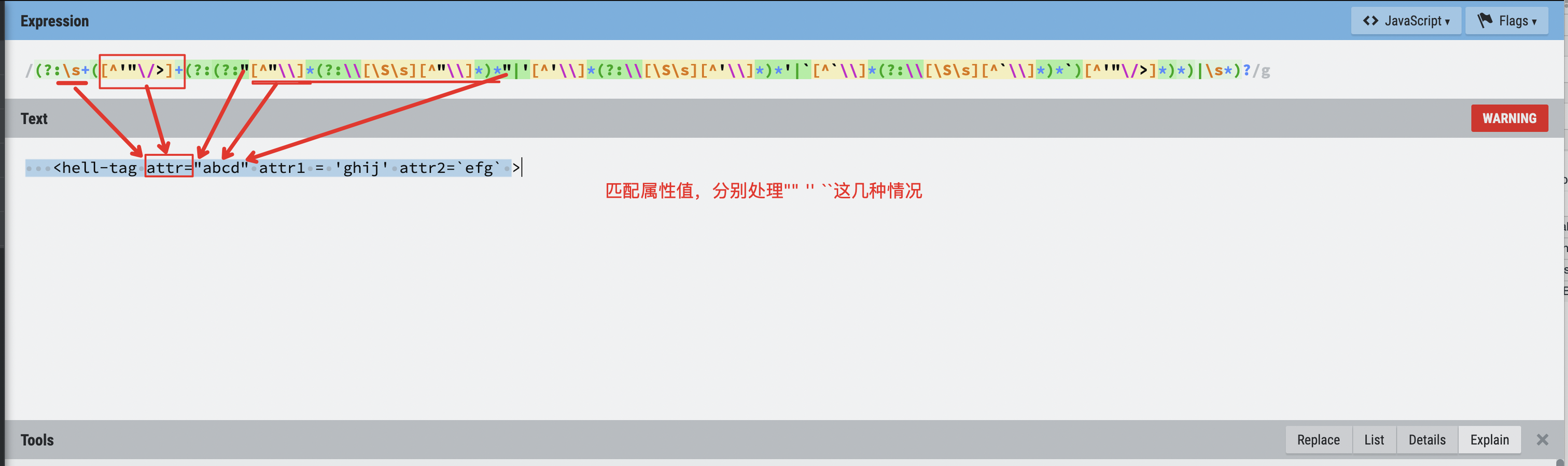
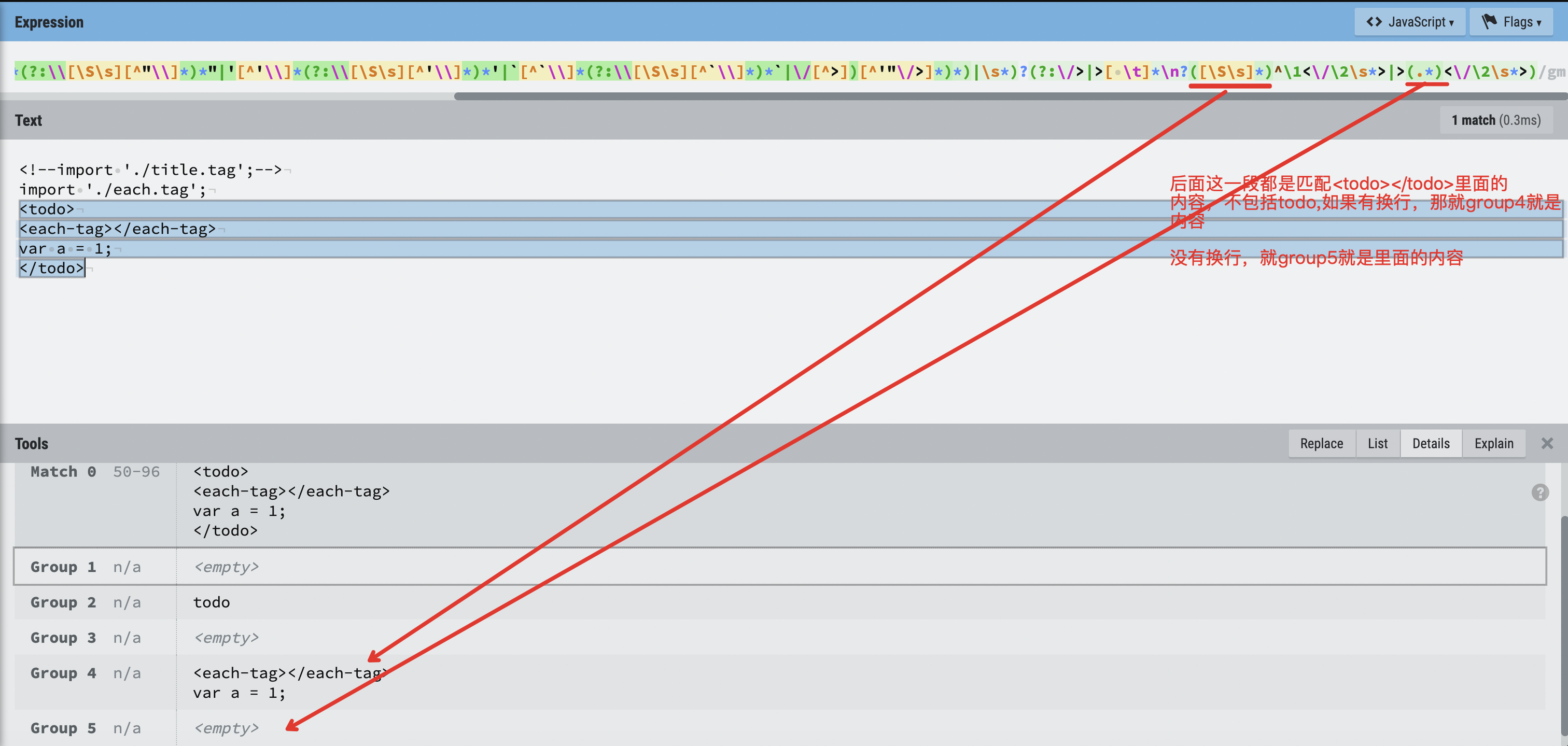
^([ \t]*)<(-?[A-Za-z][-\w\xA0-\xFF]*)(?:\s+([^'"\/>]+(?:(?:"[^"\\]*(?:\\[\S\s][^"\\]*)*"|'[^'\\]*(?:\\[\S\s][^'\\]*)*'|[^\\]*(?:\\[\S\s][^\])|\/[^>])[^'"\/>]*)*)|\s*)?(?:\/>|>[ \t]*\n?([\S\s]*)^\1<\/\2\s*>|>(.*)<\/\2\s*>)
好长,亮瞎我的狗眼😅
含泪😂解释 (正则分析的网址:regexr.com/):
^([ \t]*)<(-?[A-Za-z][-\w\xA0-\xFF]*):
(?:\s+([^'"\/>]+(?:(?:"[^"\\]*(?:\\[\S\s][^"\\]*)*"|'[^'\\]*(?:\\[\S\s][^'\\]*)*'|[^\\]*(?:\\[\S\s][^\])|\/[^>])[^'"\/>]*)*)|\s*)?
- (?:\/>|>[ \t]*\n?([\S\s]*)^\1<\/\2\s*>|>(.*)<\/\2\s*>) |
|---|
其实就是表示<hello>【asdasdas</hello>】后半部分【】里的内容。
整个正则中用到大量的非捕获组(?:)和 捕获组(),还用到了回溯引用(\1和\2), 在这个正则里捕获组只用5个(刚好对应上面6个参数的后五个),\1在这里表示的是第一个捕获组获取到的内容,即缩进,即标签名字,第二个是标签名字。
然后,我们发现会执行:
splitBlocks
分割HTML和JS/CSS
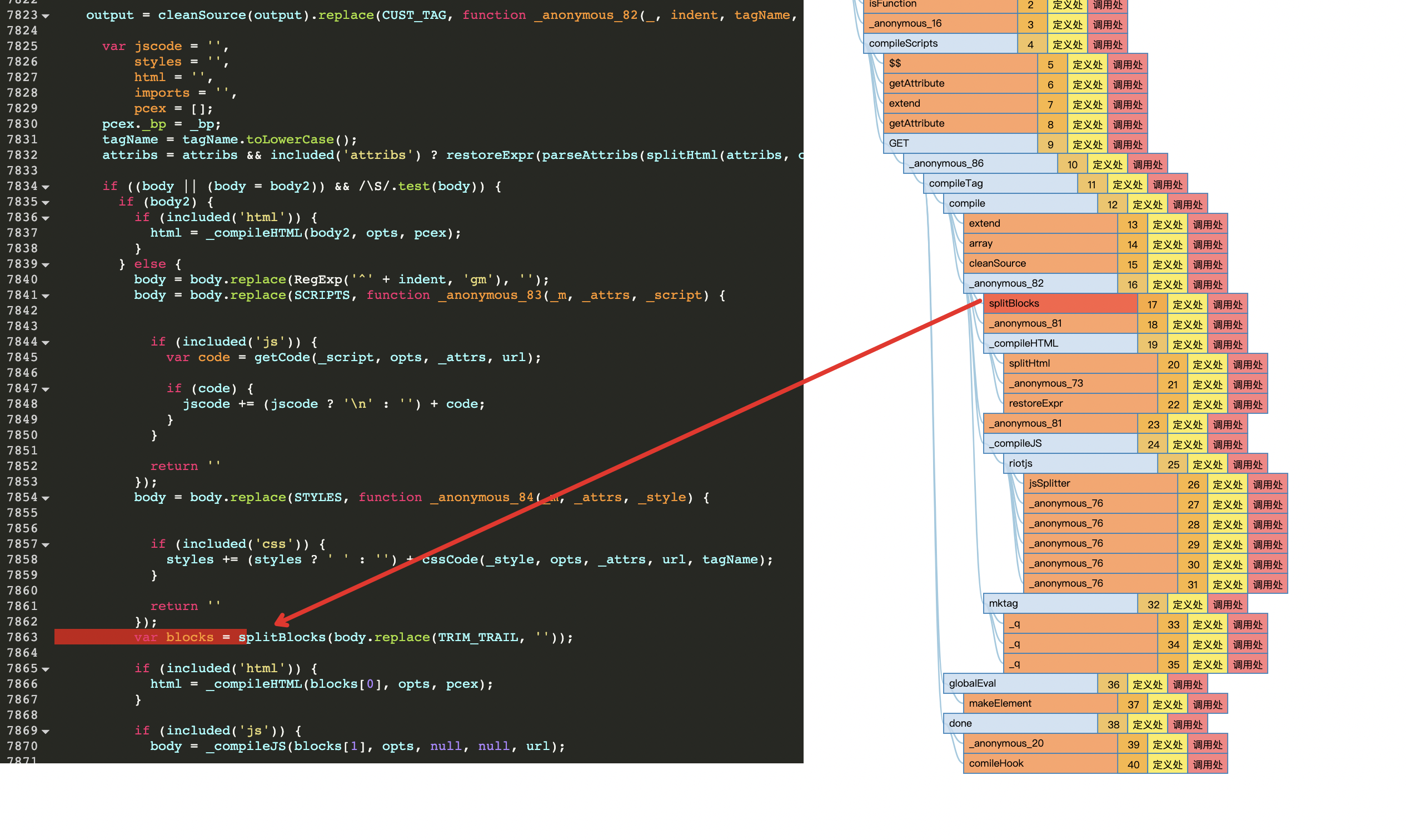

其原理就是判断最后一个HTML闭合标签(如:</each-tag>)的位置在哪,然后分割成2部分返回。

然后会执行到:
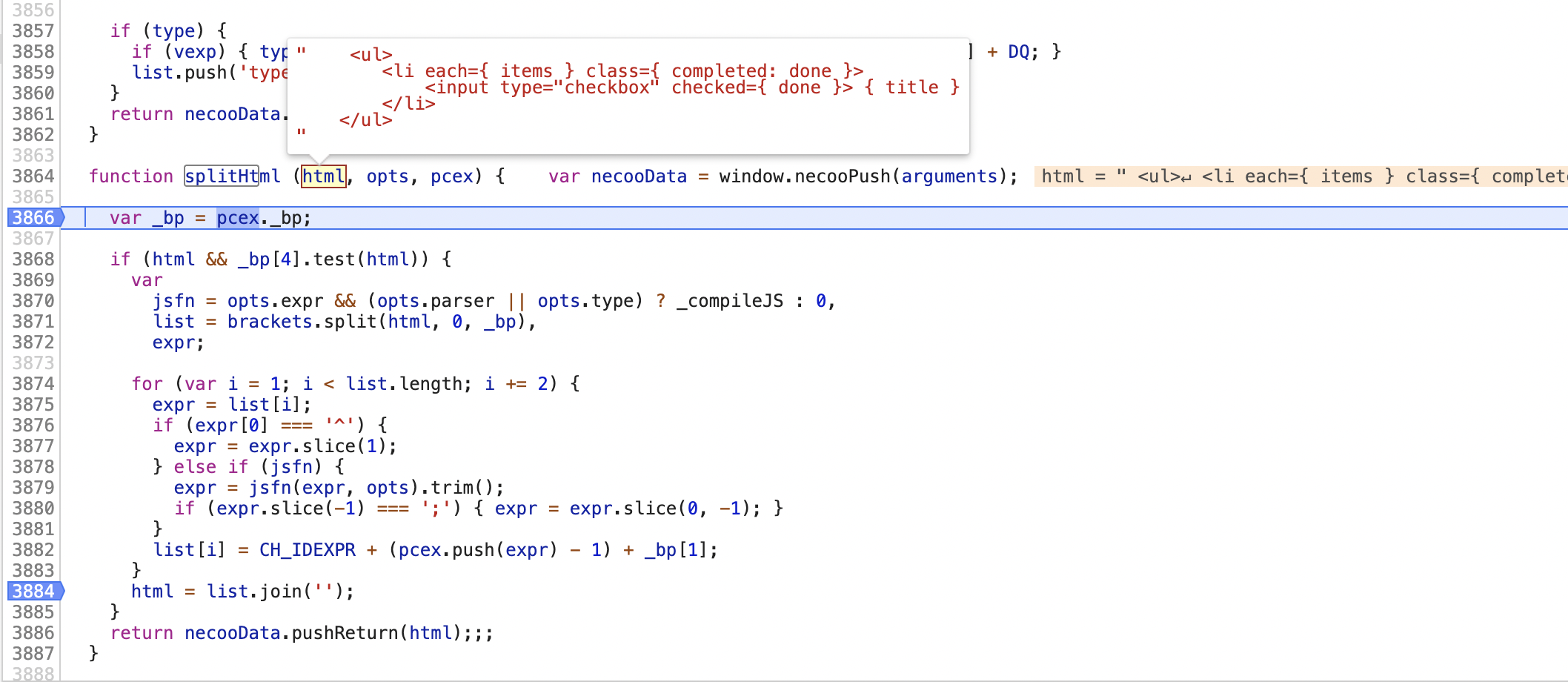
splitHtml
把HTML字符中的{xxx} 替换成 {#1}的形式, 并把xxx保存下来。

看这个函数的 输入
输出
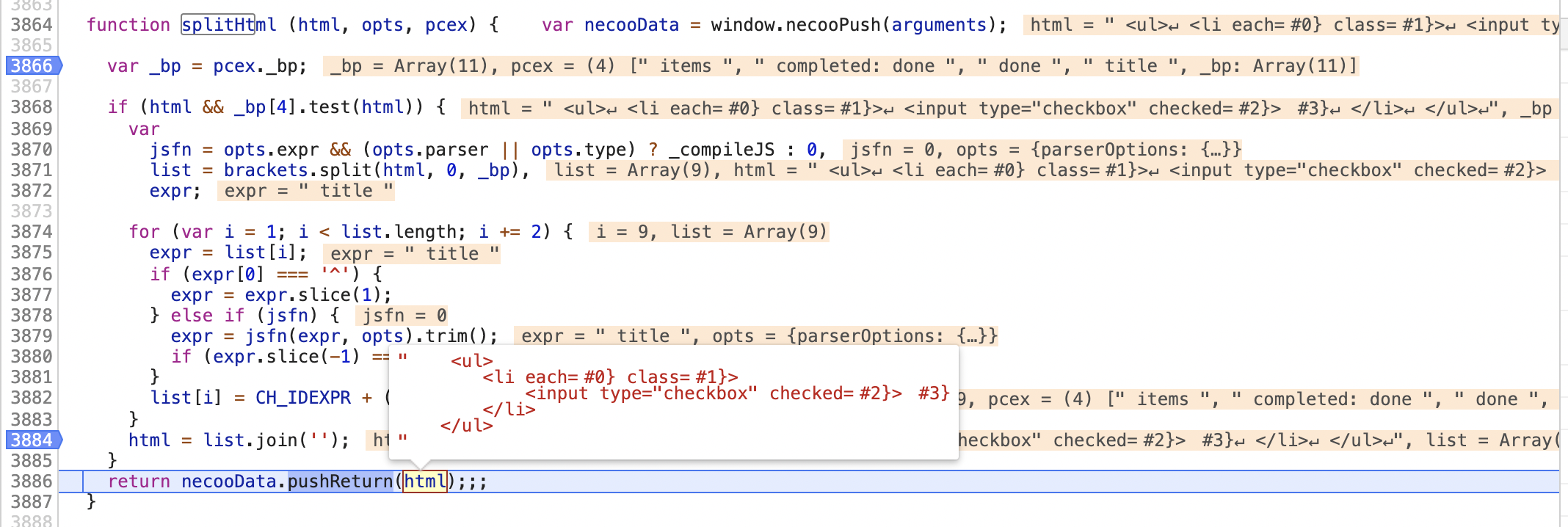
上面的结果输出后,再对HTML标签上的属性进行一层解析,起主要目的是对一些属性添加riot-,如:
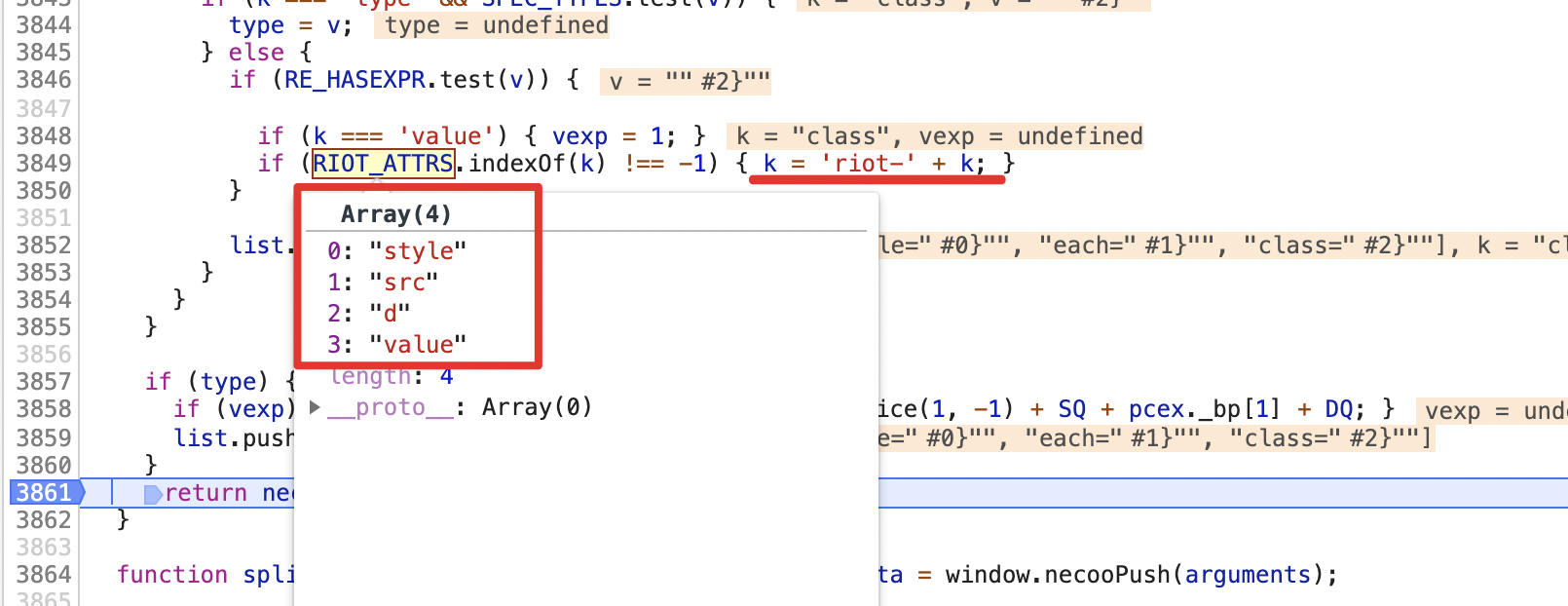
restoreExpr
把{#1}的格式还原成{xxx}

输入输出:
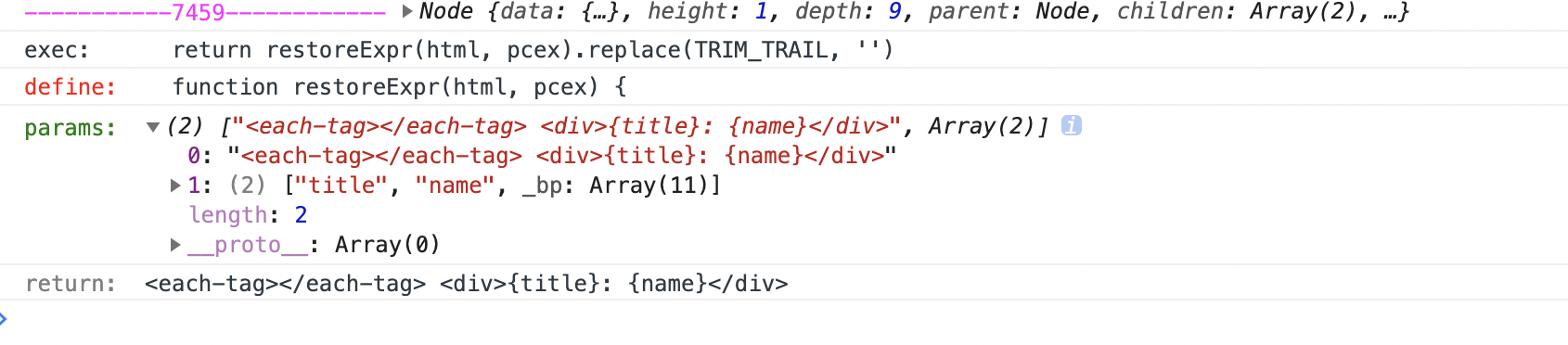
_compileJS
他的作用与splitHtml类似,只不过他是把js字符串内的所有单双引号'xxx'替换成<%>,然后再对js代码进行es6的一些转换啥的,然后又替换回来。
然后走到:
mktag
拼接最终输出的字符串

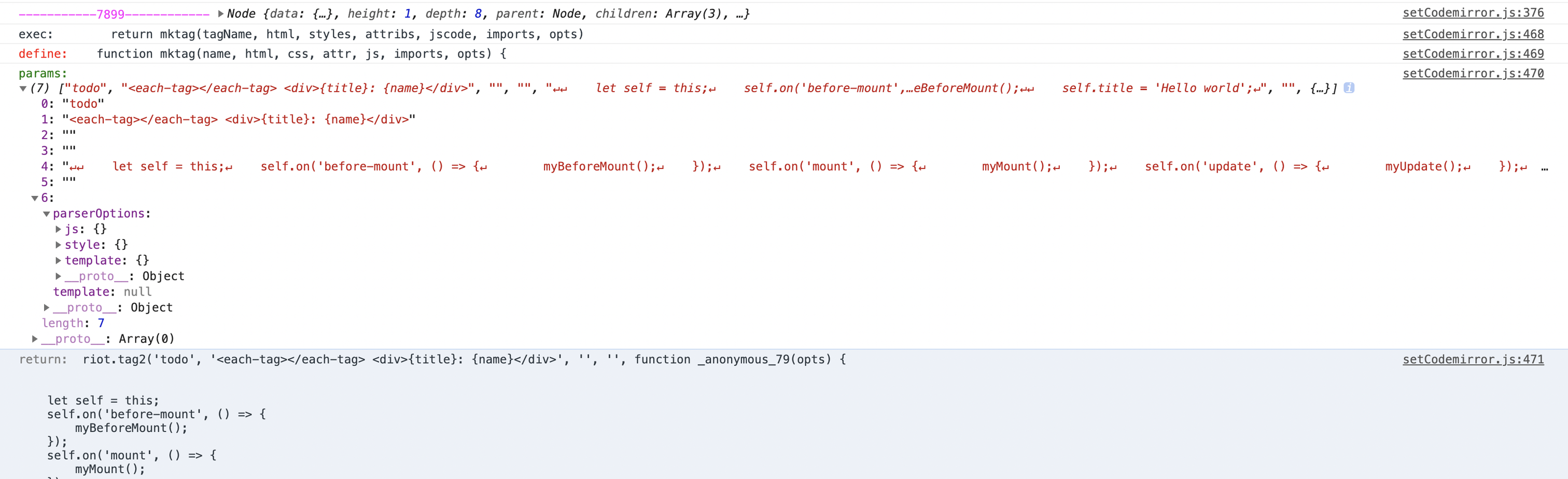
这里其实就是拼接riot.tag2函数的最终部分。
globalEval
通过脚本标签append到body中去执行上面拼接出来的riot.tag2函数

function globalEval(js, url) {
if (typeof js === T_STRING) {
var node = makeElement('script'),
root = document.documentElement; // make the source available in the "(no domain)" tab
// of Chrome DevTools, with a .js extension
if (url) {
js += '\n//# sourceURL=' + url + '.js';
}
node.text = js;
root.appendChild(node);
root.removeChild(node);
}
} // compiles all the internal and external tags on the page
这里其实是一种执行脚本的hack方式,就是生成一个script元素,然后把script的text设置成我们之前设置好的riot.tag2字符,然后append到dom中,就会立即执行riot.tag2这个函数,然后再移除(不然会生成很多script)
分析到这里,大部分原理已经明白了,riot.compile的其他用法的原理以上的一样,只不过某些地方的判断分支走的不一样。
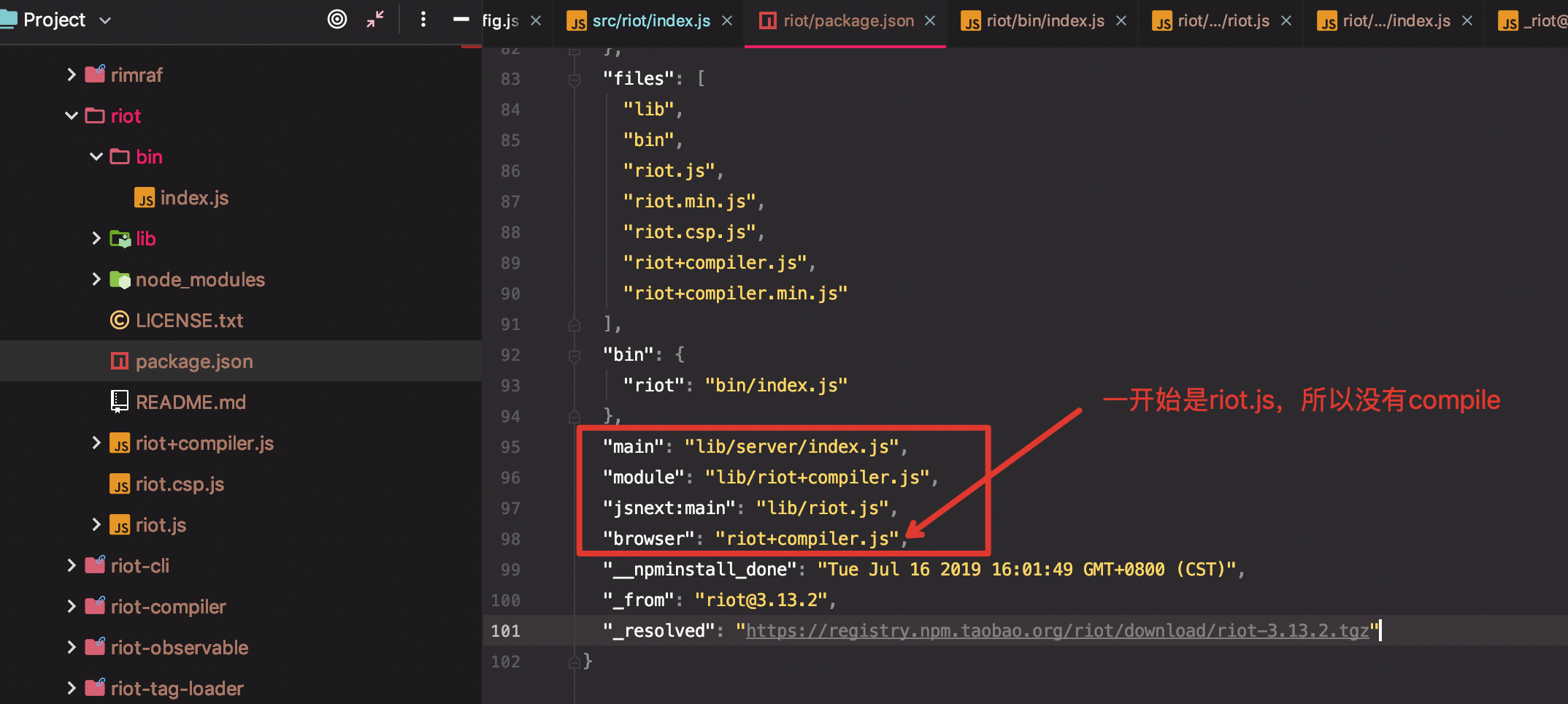
问题记录:在
import riot from 'riot';的时候,返现输出的riot没有riot.compile,去翻阅他的package.json的时候发现browser字段才是起作用的那个,main字段不是!
总结:
- riot.compile的作用就是把.tag转成riot.tag2(xxx)字符串并且立即执行(根据参数控制)
- riot.compile中用到了大量的正则,所以,学好正则是分析这种类型的框架源码的第一步
