

搭建环境
安装时间同步Yum install -y ntpdate 网络时间同步命了 服务器地址是阿里云ntpdate ntp1.aliyun.com 手动时间同步方式date -s "20190622 12:32:00" #yyyymmdd hh:mm:ss完全分布式
服务器namenodesecondaryNameNodedatanode Hadoop01有 Hadoop02 有有 Hadoop03 有Hadoop04 有Ps:这里我们已经将时间同步,主机名称,网络通信,hosts映射都做完,以上步骤省略
上传到目录中然后进行解压

后面的路径自己写进入到对应的路径 就可以查看版本了配置环境变量是为了以后方便使用


将进入和这个里配置环境变量,这是一个全局的环境变量谁都可以使用了在最后添加

保存退出 然后然后重新加载资源文件

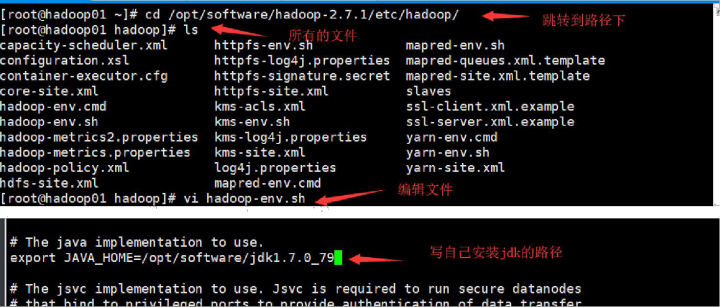
然后执行java -version 1.先解压hadoop安装包 到 /opt/softwar/路径下

2. 修改配置文件先修改 /hadoop2.7.1/etc/hadoop/hadoop-env
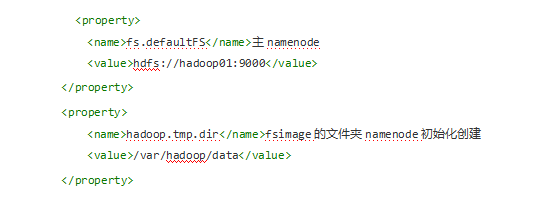
3.修改相同路径下 core-site.xml hdfs-site.xml
修改core-site.xml内容
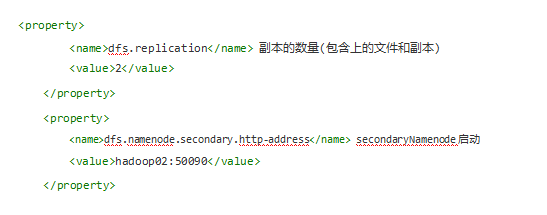
修改hdfs-site.xml
4. 添加从节点(datanode) 相同路径下 slaves

5.添加hadoop路径作为全局
修改 vi /etc/profile

重新加载资源
source /etc/profile
6.免秘钥
图解:
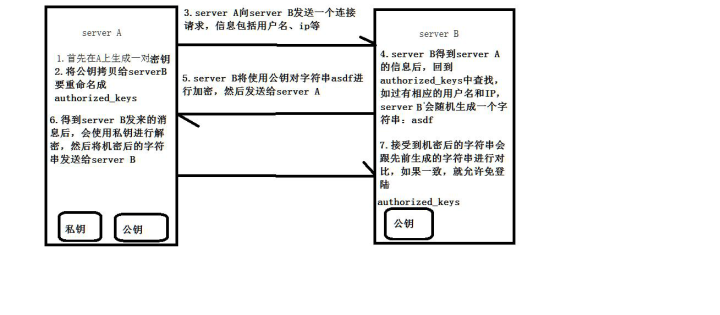
hadoop01和hadoop02,03,04免秘钥.因为hadoop01是namenode需要管理01,02,03,04服务器,所以应该完成面秘钥操作
若机器中没有ssh命令 yum install openssh-clients.x86_64 -y 先产生.ssh文件夹 隐藏文件 并且在~(家)目录下
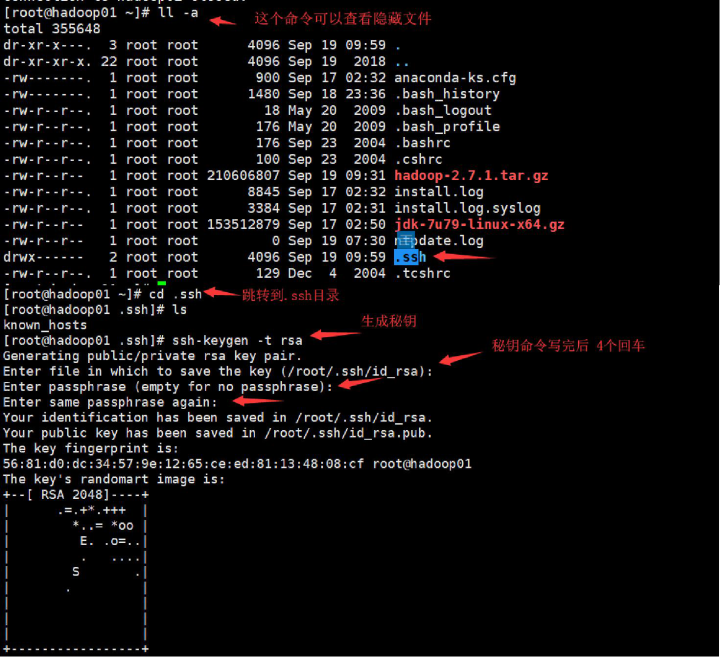
发送公钥给01,02,03,04
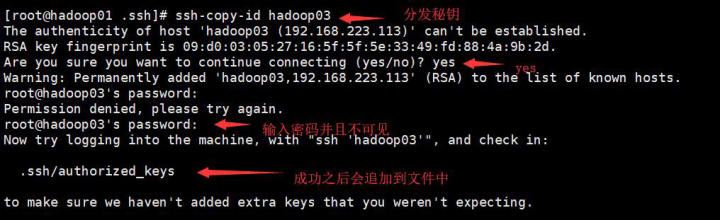
ssh-copy-id 服务器名称 下面图片是一个例子
7.分发hadoop安装包 因为已经配置完成直接分发即可 分发给02,03,04分发命令是scp -r是递归 代表分发的是文件夹并且文件夹下面还有文件 scp 发送文件
scp -r 当前主机软件安装的路径 主机名/IP:发送过来软件要存在在当前机器下的路径
scp -r /opt/software/hadoop-2.7.1/ hadoop02:/opt/software/
8.修改02,03,04机器上vi /etc/profile文件并配置HADOOP_HOME
配置成功后从新加载 source /etc/profile
9.启动集群但是 当前集群是第一次配置
需要格式化 namenode 在hadoop01
hdfs namenode -format
ps:这个命令只能第一次开启集群的时候格式化,以后进入公司,集群是搭建好的,千万不要
10.开启集群
start-dfs.sh 开启集群
stop-dfs.sh 停止集群
模块化开启
ps:
全部启动 start-all.sh
全部停止 stop-all.sh
单个角色启动
hadoop-daemon.sh start namenode或datanode或secondarynamenode hadoop-daemon.sh stop namenode或datanode或secondarynamenode直接杀死角色 kill -9 进程
