

JavaScript 单元测试如今对于前端开发来说并不陌生,前端工程化之后项目的代码质量越来越受到重视,单元测试无疑是一种衡量代码质量的重要手段,而测试覆盖率则是衡量测试完整性的一种手段:通过已执行代码的覆盖率,用于评测代码的可靠性和稳定性,可以及时发现没有被测试用例执行到的代码块,提前发现可能的逻辑错误。
伊斯坦布尔(以下简称 Istanbul)是一个基于 JavaScript 的测试覆盖率统计工具,目前绝大多数测试框架比如 jest mocha 等都是使用 Istanbul 来统计覆盖率的。伊斯坦布尔有一个比较老的版本 istanbul.js(已不再维护)和一个新的版本 nyc。虽然使用 Istanbul 的人很多,但是几乎没有介绍其实现原理的文章,那么 Istanbul 计算和统计测试覆盖率的整个流程是怎样的呢?
在剖析源码之前,我们首先需要了解衡量测试覆盖率的四个维度:
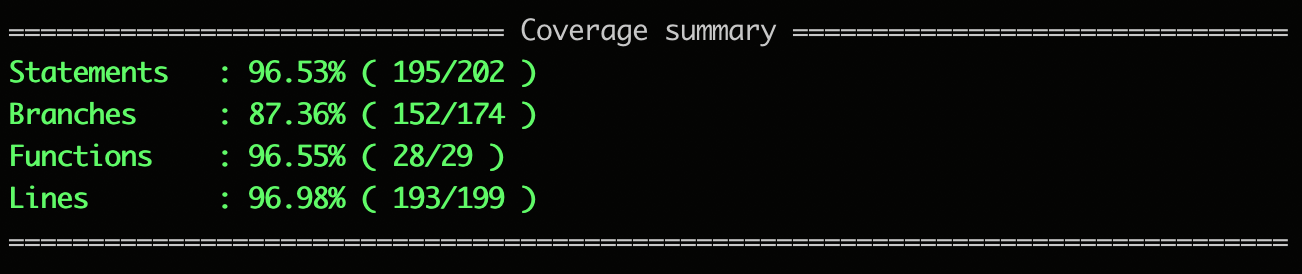
- Statements: 语句覆盖率,所有语句的执行率;
- Branches: 分支覆盖率,所有代码分支如 if、三目运算的执行率;
- Functions: 函数覆盖率,所有函数的被调用率;
- Lines: 行覆盖率,所有有效代码行的执行率,和语句类似,但是计算方式略有差别;
以上四个指标维度就是 Istanbul 最终要输出的结果,可以看出 Istanbul 的核心任务就是实现对这四个指标的计数器,它的内部实现流程大致可以分为以下三个步骤:
第一步:构造源代码装饰器
“装饰器”源码里面称为 instrumenter,是 Istanbul 的核心,它的作用是“装饰”源代码,注入计数器。要往源代码中注入计数器就需要识别代码行、语句和函数等。首先读取指定目录(用户配置)下的源码并一一构造语法树(AST),区分出四个维度的代码段并进行标记,这个功能的具体实现逻辑本文不作详细展开,有兴趣的可以去看下源码或者 babel/parser 这个插件。简单来说装饰器的工作流就是:
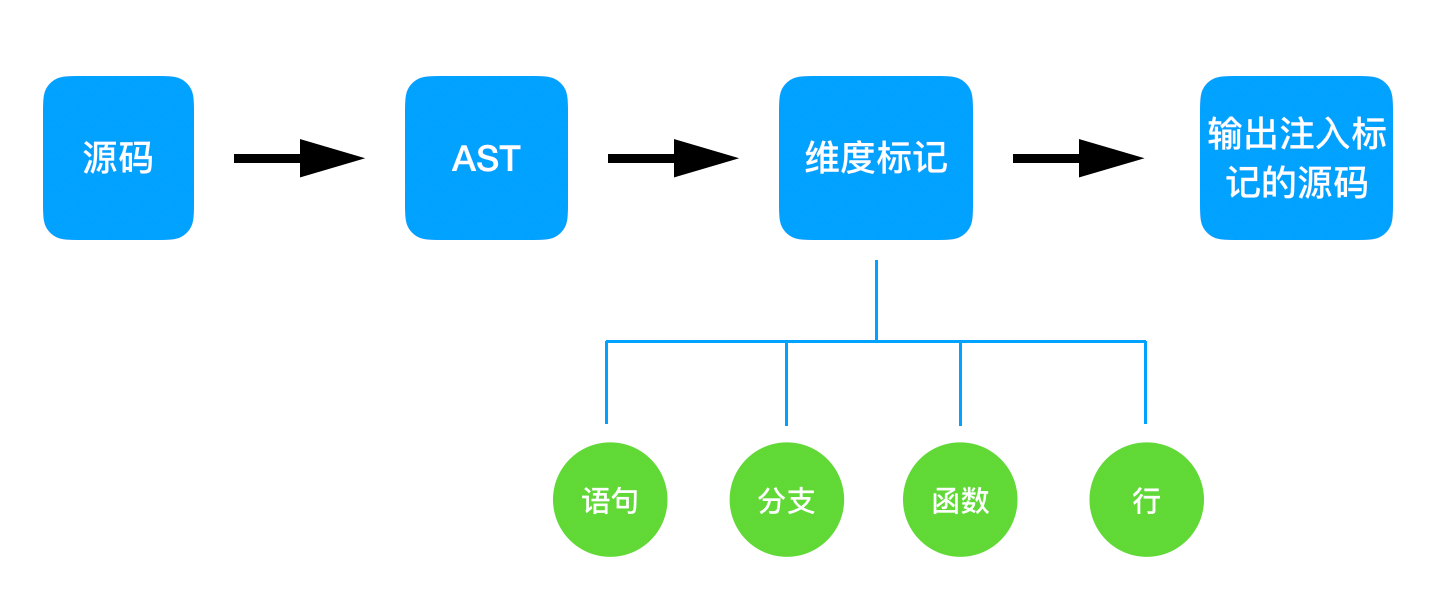
还是觉得抽象?来看一个直观的例子就明白了,比如待测试的源码文件为:
function AFunctionThatNeverBeCalled () {
return Math.random() > 0.5 ? true : false
}
function AFunctionThatWillBeCalled (string) {
return string
}
module.exports = function sayHello (name) {
if (name) {
return AFunctionThatWillBeCalled('Hello, ' + name)
} else {
return 'Should pass a name'
}
}
经过装饰器的 AST、维度标记等操作处理后,源码就被装饰成了这个样子:
var cov_1pwyfn0t92 = (function() {
// 此处省略较多的代码,这里面返回的是一个计数器对象,包括 AST 解析数据等,详见下文
})();
function AFunctionThatNeverBeCalled() {
cov_1pwyfn0t92.f[0]++;
cov_1pwyfn0t92.s[0]++;
return Math.random() > 0.2
? (cov_1pwyfn0t92.b[0][0]++, true)
: (cov_1pwyfn0t92.b[0][1]++, false);
}
function AFunctionThatWillBeCalled(string) {
cov_1pwyfn0t92.f[1]++;
cov_1pwyfn0t92.s[1]++;
return string;
}
cov_1pwyfn0t92.s[2]++;
module.exports = function sayHello(name) {
cov_1pwyfn0t92.f[2]++;
cov_1pwyfn0t92.s[3]++;
if (name) {
cov_1pwyfn0t92.b[1][0]++;
cov_1pwyfn0t92.s[4]++;
return AFunctionThatWillBeCalled('Hello, ' + name);
} else {
cov_1pwyfn0t92.b[1][1]++;
cov_1pwyfn0t92.s[5]++;
return 'Should pass a name';
}
};
可以看到最开始的源代码几乎被转换成了另一个样子,但原来的代码逻辑是不会改变的,只是注入了一些对原代码执行没有影响的计数语句,很明显这些计数代码就对应了各个维度的计数器:
| ------ | ------ | | cov_1pwyfn0t92 | 文件唯一计数对象| | cov_1pwyfn0t92.s | Statement 计数器 | | cov_1pwyfn0t92.b | Branch 计数器 | | cov_1pwyfn0t92.f | Function 计数器 |
细心的朋友可能发现缺少了行覆盖率指标 Lines 计数器,其实行覆盖率是通过语句中的起始行和结束行之间语句的执行率计算得来的。如果再把 cov_1pwyfn0t92 这个对象展开来看里面的内容,那么经过装饰器“装饰”后的产出和解析结果就更加直观明了了:

一句话总结装饰器的作用就是:篡改源代码,注入计数器。
第二步:拦截模块加载器
但是实际上总不能真的把源码给改了吧,那么 Istanbul 是如何让测试用例引用的源代码变成自己篡改过的代码呢?当单元测试框架(jest、mocha 等)开始跑(执行)测试用例的时候,只要把当前运行时的模块加载器要加载的源代码拦截掉,换成 Istanbul 装饰过的代码即可,也就是对测试用例所引用到的源代码进行“偷梁换柱”:
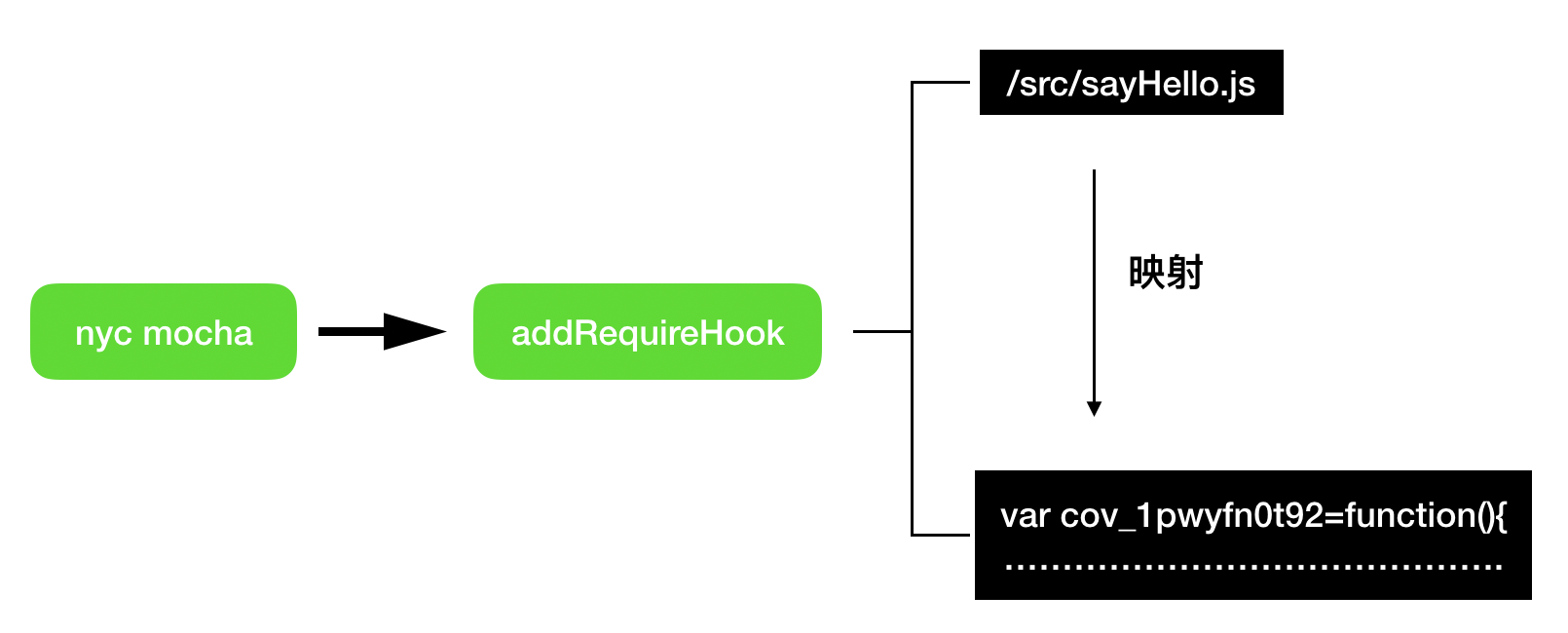
Istanbul 实现 addRequireHook 方法是用了一个 npm 模块 append-transform,大致原理就是类似 nodejs 的 require.extensions 和增加一些特殊处理,具体的细节就不详述了,这里只需要知道它起到了拦截加载器的作用。
第三步:统计和输出覆盖率报告
经过了前面的步骤,已经篡改了源代码并注入计数器,那么执行完测试用例后再去收集每一个文件的四个指标覆盖率就水到渠成了,最后拿到结果就可以输出直观的统计报告,Istanbul 支持输出多种统计报告类型:
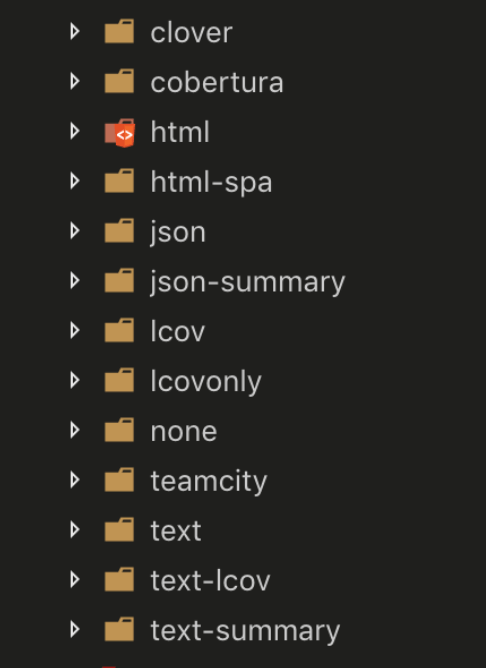
每一种类型都有对应的独立模块去处理,比如 html 类型的报告需要生成直观的 html 文件;lcov 则需要生成二进制文件等等。
这就是 Istanbul 的基本实现原理,本文只是描述了最主干的实现,一些细节的功能比如忽略代码块、ES6 的支持和 SourceMap 等等也非常值得去阅读和深挖。
AlloyTeam 欢迎优秀的小伙伴加入。
简历投递: alloyteam@qq.com
详情可点击 腾讯AlloyTeam招募Web前端工程师(社招)

