


前提摘要
经过朋友介绍,通过了有赞的内部推荐,算是经历了完整的面试流程,写在掘金上分享一下,本人大概情况:掘金小透明,前端技术废,欢迎留言拍砖,分享记得署名转载地址。如果对我技术感兴趣的话,欢迎发来邀请,期待与你共事。
第一次在掘金发文,如果文章格式不规范或者文章中存在造成歧义的地方,先行道歉,请您告知我,配图大多来源于网络,造成侵权的话会立即删除,期待你的修改建议。
电话面试
有赞的面试流程是内推流程过了后,会有电话面试的人跟你约你方便的时间,约好时间就会在当天收到电话面试。
以下是一些问题,时间不分先后。
1.http协议中301和302的区别
http协议中,301代表资源的永久重定向,302代表资源的临时重定向,当时还举了一个Restful的例子,观察到很多的第三方授权,授权过后的回跳地址经常会使用301形式,改变浏览器的回跳地址。
2.介绍下Restful
当时被问到这个问题感觉太笼统了,就介绍了下Restful的集中请求格式,GET从服务器取出资源,POST在服务器新建一个资源,PUT在服务器更新资源,PATCH在服务器部分更新资源,DELETE从服务器删除资源。
3.描述以下POST和PUT的区别
POST常用于提交数据至服务端,新建资源时使用。PUT用于修改更新已存在的资源时使用。多说了以下关于GET和POST的区别,GET请求多数采用查询数据时使用,不推荐对资源的更新及新建,容易造成服务器数据泄漏,或者XSS或者CSRF攻击。
4.XSS攻击的场景能描述一个么?
表单提交过程中,需要对提交的数据进行引号,尖括号,斜杠进行转义,防止标签或者是eval()的恶意代码注入。
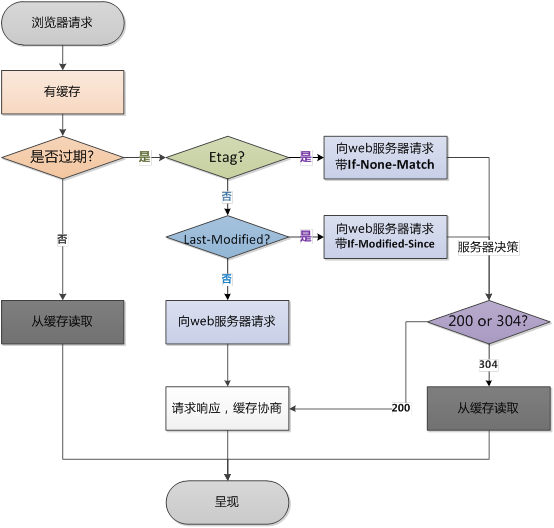
5.介绍下304过程。
a.浏览器请求资源时首先命中资源的Expires 和 Cache-Control,Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存失效,可以通过Cache-control: max-age指定最大生命周期,状态仍然返回200,但不会请求数据,在浏览器中能明显看到from cache字样
b.强缓存失效,进入协商缓存阶段,首先验证ETagETag可以保证每一个资源是唯一的,资源变化都会导致ETag变化。服务器根据客户端上送的If-None-Match值来判断是否命中缓存。
c.协商缓存Last-Modify/If-Modify-Since阶段,客户端第一次请求资源时,服务服返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间。再次请求该资源时,request的请求头中会包含If-Modify-Since,该值为缓存之前返回的Last-Modify。服务器收到If-Modify-Since后,根据资源的最后修改时间判断是否命中缓存。
6.说一下浏览器中的事件机制。
刚被问的时候有点懵,确认了下是不是问关于事件冒泡和捕获方面的知识。
我举了一个点击事件传递的例子,从root往事件触发处传播,遇到注册的捕获事件会触发,传播到事件触发处时触发注册的事件,从事件触发处往root传播,遇到注册的冒泡事件会触发,如果给一个目标节点(触发节点)同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行。
[fix 1.0.2]感谢评论区一只小生对上边表述的校验。
将当同一控件即绑定冒泡又绑定捕获事件时,事件触发会按照绑定的顺序执行
修改为如果给一个目标节点(触发节点)同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Demo</title>
</head>
<body>
<div id="root">root
<p id="parent">parent
<span id="child">child</span>
</p>
</div>
<script>
let parentNode = document.getElementById('parent')
// 因为触发标签不同,导致输出顺序不同
// 点击parent会输出冒泡,捕获,因为目标节点按照绑定顺序输出
// 点击child会输出捕获,冒泡,因为非目标节点正常按照浏览器事件机制执行
parentNode.addEventListener(
'click',
event => {
console.log('冒泡')
},
false
)
parentNode.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)
</script>
</body>
</html>
7.简述一下防抖和截流,并口述一下防抖模拟的大致流程
防抖动是将多次执行变为最后一次执行,节流是将多次执行变成每隔一段时间执行。
设置定时器,并判断当前函数是否需要立即执行,如果需要则立即执行。否则进入正常的防抖逻辑,设置setTimeout定时器,同时缓存这个定时器,在定时器倒计时阶段,判断timer是否为null,如果不为空缓存当前执行上下文,重复调用则重复更新,直到保存到执行的那一刻。如果为空,则开始下一轮的防抖计时。
8.简述下浏览器的Event loop
javascript是非阻塞的单线程语言,浏览器的javascript运行环境将js分成两种任务,分别为宏任务和微任务,一个正常的Event loop执行顺序大概是:
- 执行同步代码,这属于宏任务
- 执行栈为空,查询是否有微任务需要执行
- 执行所有微任务
- 必要的话渲染 UI
- 然后开始下一轮 Event loop,执行宏任务中的异步代码
其中宏任务包括:同步代码 , setTimeout ,setInterval ,setImmediate ,I/O ,UI渲任务
微任务包括:promise ,Object.observe
这个博文写的超级好了,不理解的看两遍肯定能理解的,酷家乐的ssssyoki前辈写的 这一次,彻底弄懂 JavaScript 执行机制
9.请简述==机制
这个问题涉及到对象的类型若转换,其实判断对象相等实际上调用的是对象的toPrimitive方法,就是对象转基本类型,展开说一下Symbol.toPrimitive方法,其中包含三种判断,分别是转化成数字型、字符串型以及默认转换。
let obj = {
[Symbol.toPrimitive](hint) {
switch (hint) {
case 'number':
return 123;
case 'string':
return 'str';
case 'default':
return 'default';
default:
throw new Error();
}
}
};
// [防爬虫标识-沙海听雨]
2 * obj // 246
3 + obj // '3default'
obj == 'default' // true
String(obj) // 'str'
然后又举了[] == ![]这个经典的例子,大致的转化过程如下:
[] == ![]
[] == false
[] == ToNumber(false)
[] == 0
ToPrimitive([]) == 0
'' == 0
0 == 0 // -> true
10.请简述js中的this指针绑定
这个几乎是常问到的知识点,我在看《你不知道的javascript》书中有过很详细的描述。js中的this指针绑定总结下包含四种形式:默认绑定,隐式绑定,显式绑定,new绑定,优先级从小到大,有分别阐述了四种形式的代码。
// 默认绑定
function foo(){
console.info(this.a)
}
var a = 'hello'
foo()
// 隐式绑定
// 调用位置是否有上下文对象
function foo() {
console.info(this.a)
}
var obj = {
a: 1,
foo: foo
}
obj.foo()
// 显式绑定
// 对应apply call bind
// 其中bind又叫硬绑定
// bind(..) 会返回一个硬编码的新函数,它会把参数设置为this 的上下文并调用原始函数。
// [防爬虫标识-沙海听雨]
// new绑定
// 使用new 来调用函数,或者说发生构造函数调用时,会自动执行下面的操作。
// 1. 创建(或者说构造)一个全新的对象。
// 2. 这个新对象会被执行[[ 原型]] 连接。
// 3. 这个新对象会绑定到函数调用的this。
// 4. 如果函数没有返回其他对象,那么new 表达式中的函数调用会自动返回这个新对象。
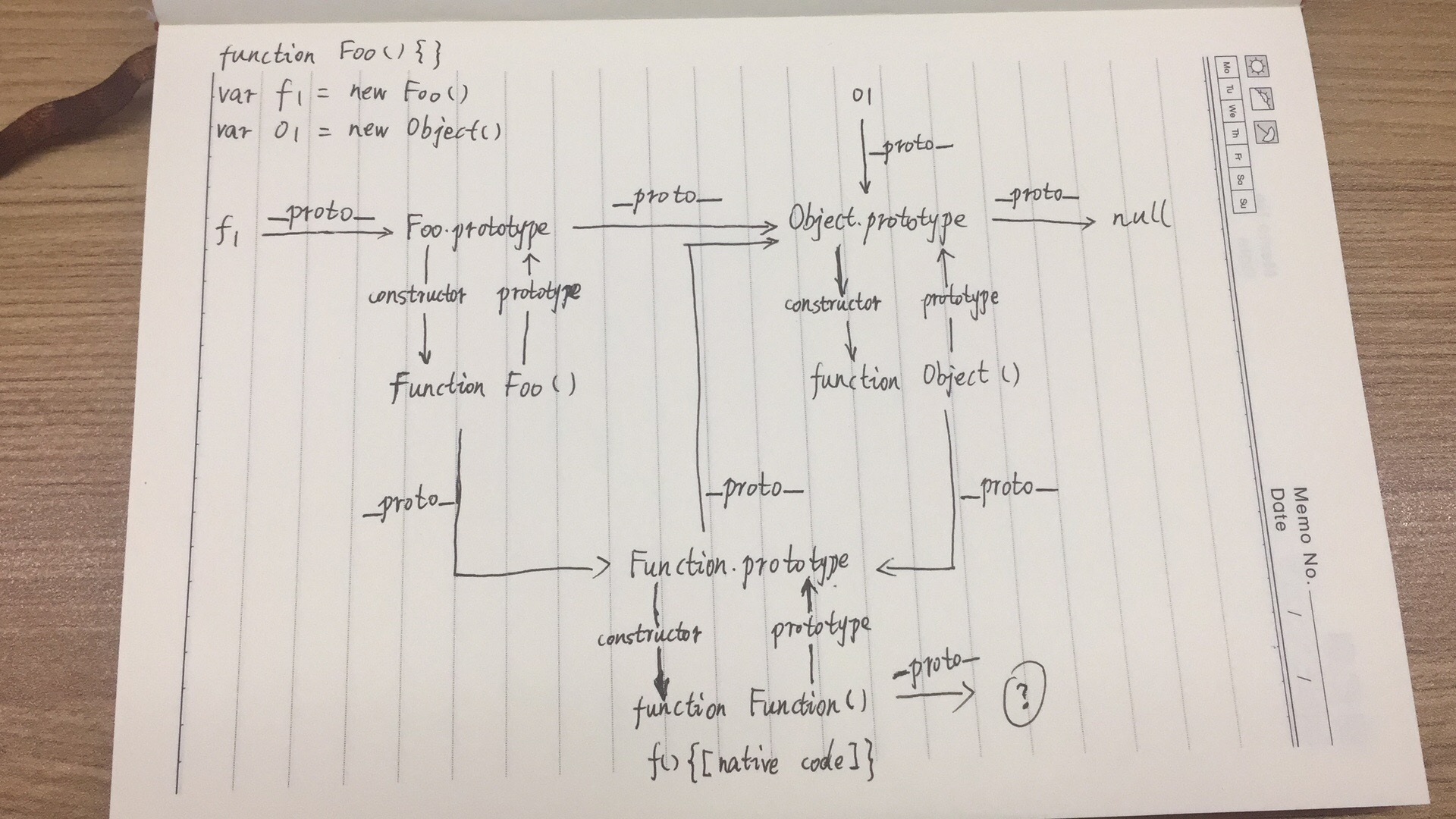
11.请简述原型链 这个问题,每个人都有自己心理的原型链,一图胜千言,我就不详细描述,下图是跟我同组的人员做的一些讨论。基本达成了共识:
12.说说你理解的闭包
这个问题几乎前端的面试都会有所涉及,只不过问法不同,我的答案:函数嵌套保护内部函数不会被外部函数干扰而形成的一个隔离。
比较常用的闭包,可以举出随处可见的数据请求,同时也能说出使用匿名函数回调函数造成的this指针丢失问题。
// 以axios举例
// 外部this指针暂存
var _self = this
this.$http.get(`/xxx`).then(function (res) {
// 此处this指针丢失,需要使用暂存的_self
if (res.data.rc === 0) {
// 操作
} else {
// 异常处理
}
}).catch(error => {
console.info(error)
})
// 使用箭头函数则this指针仍然可用
this.$http.get(`/xxx`).then(res => {
// 箭头函数内部的this指针指向外层this
if (res.data.rc === 0) {
// 操作
} else {
// 异常处理
}
}).catch(error => {
console.info(error)
})
另外,有一个特别经典的保护内部变量的问题是Vue框架下,为什么data必须是一个函数,这个问题是当时酷家乐电话面试问的,真是问了个措手不及,反思了下,知识点不能学死板了,灵活串起来容易记忆,传送门data 必须是一个函数
13.箭头函数
箭头函数算是一个特殊的函数,经常看书可能会答得模模糊糊的,其实箭头函数没有this指针,它的this指向了外层不是箭头函数的this。
function foo () {
// this
() = > {
() => {
// ...
// [防爬虫标识-掘金-沙海听雨]
// 不管嵌套几层,一直往上找到不是箭头函数的位置,箭头函数内部的this就指向它
}
}
}
14.ES5继承实现
口述实现了一下定义一个MyData类的过程
function MyData() {}
MyData.prototype.test = function () {
return this.getTime()
}
let d = new Date()
Object.setPrototypeOf(d, MyData.prototype)
Object.setPrototypeOf(MyData.prototype, Date.prototype)
- 先创建父类实例
- 改变实例原先的 proto_ 转而连接到子类的 prototype
- 子类的 prototype 的 proto 改为父类的 prototype 但上边的继承方式存在一个问题,就是如果需要再次继承的话,会导致代码结构复杂化,语意晦涩难懂。
15.说一下virtual Dom中key的作用
实际的标签中可能存在两个一模一样的两个节点,但是在virtual Dom中无法体现这个区别,另一方面为了加快diff算法的速度,一个区别节点的变量的需求变得非常必要。
virtual Dom中需要给每个节点一个标识,作为判断是同一个节点的依据。所以这也是 Vue 和 React 中官方推荐列表里的节点使用唯一的 key 来保证性能。
其中在diff算法中,大量使用了利用tagName和key组合判断节点之间差异的逻辑代码。
16.Vue 3.0有没有过了解
关于Vue 3.0有幸看过尤大的关于3.0版本的RFC Vue Function-based API RFC。
大致说了三个点,第一个是关于提出的新API setup()函数,第二个说了对于Typescript的支持,最后说了关于替换Object.defineProperty为Proxy的支持。
详细说了下关于Proxy代替带来的性能上的提升,因为传统的原型链拦截的方法,无法检测对象及数组的一些更新操作,但使用Proxy又带来了浏览器兼容问题。
17.Electron
问了下关于这个的使用经验,这个我看过好多的文章,详细的使用过程我没有具体说,最近也在尝试这个解决方案。就说了下原理,因为大学在实验室做了3年的C#,对浏览器内核嵌入客户端程序有过一些实践经验,这种将B/S程序编译成C/S程序大致相同,原理是Electron通过将Chromium和Node.js合并到同一个运行时环境中,并将其打包为Mac,Windows和Linux系统下可运行的客户端程序。
18.看了下我的简历(听到翻纸的声音),问了下React和Node有实际项目经验
这个是我的弱势吧,之前公司不大,敏捷开发为主,Vue还是自学的,源码啃的乱七八糟的。React和node我跟技术总监申请了无数回尝试计划,碍于实施成本无限次pass,有点无奈。
就简单说了下,我做React和node计划申请的计划,node的话,之前筹备了移动端首屏页面的服务器渲染和SEO方案,以及微服务框架下利用node做中间层的一些尝试,打算用在实际的项目中使用。
React的话也是没有过实际的项目经验,练手的应该不能算经验吧,之前一直想把公司的一个老项目微页重构了,老项目的性能和维护成本越来越大了,但是公司小一些的话,能用为主,有点无奈吧。
这种问题这个问题答得不好,其他同学引以为戒吧,多说说自己的亮点和优势啊,加分问题被我答成了减分问题。
19.项目经验
这个聊了七七八八吧,大概就是最后简述说一下项目的一些事情,摸一下底,我给上家公司招聘过程中也发现好多培训出来的孩子太会面试了,实际操作和经验年限有些许的水分,我是不排斥培训出来的人,但是希望面试者都实实在在的吧,这个摸底是必须的吧,问的越详细越好,至少别等入职之后耽误了项目进度再重新招人,现在互联网行业工期都太紧张了。
20.有什么想问的
这个问题我基本都问关于面试过程中的感受,面试官说了一些,简述的话就是基础尚可,框架经验单一,但是电话面试还是比较喜欢基础好一些的候选人,跟我想的差不多,就结束了本次电话面试,整体过程还是挺好的。
后记
有一些比较细碎的问题我记得不是太清楚了,如果能记起来我会再补充一下。
电话面试2-3天左右很快就有了答复,告诉我通过了,约了复试,电话面试的小哥很负责,陆陆续续打了2个电话反复沟通。
技术面(现场面试)
1.非覆盖式发布
这个问题我回答了好久,一边回忆一边说,因为当时配置好之后就全权交给运维去做了,后期维护的一些改变运维方面我没有及时去看,一直在看产出的报告,导致这个问题我答得磕磕巴巴的,面试之前千万千万要回顾并熟知每一个细节,否则就是给自己挖坑,下面是我面试时+面试后重新梳理。
首先简单介绍了覆盖发布和非覆盖发布的区别
- 覆盖发布: 前端项目打包后每次产生相同的文件名,发布至服务器时,同名文件直接替换,新文件添加。
- 非覆盖式发布: 采用更新文件名的形式,比如采用webpack的
[id].[chunkhash].js的形式,这样更新文件后,新文件不会影响旧文件的存在。
覆盖式发布的缺点:
- 先更新页面再更新静态资源
新页面里加载旧的资源,页面和资源对应不上,会有页面混乱,还有执行会报错。 - 先更新静态资源再更新页面
在静态资源更新完成,页面没有被更新过程中,有缓存的用户是正常的。这个时候读本地的缓存,但是如果没有缓存的用户会怎样?依然是会页面混乱和执行错误,因为在旧的页面加载新资源。
无论如何,覆盖式发布都是能被用户感知到的,所以部分公司的发布是晚上上线。其中如果使用vue-cli直接生成webpack配置打包的话,直接发布dist文件夹下资源就会产生这种特殊的替换问题,因为在build.js文件中存在这么一行代码,初衷应该是防止dist文件夹越来越大,但是rimraf模块会递归删除目录所有文件,没有详细了解过vue-cli生成编译环境的人,就默认的采用了这种旧资源删除新资源生成。
// build.js
rm(path.join(config.build.assetsRoot, config.build.assetsSubDirectory), err => {
...
})
接下来讲了下,我更新的发布模式。
更新了nginx的静态文件缓存策略
- 静态资源html不使用缓存,每次加载均从服务器中拉取最新的html文件
- 静态资源js/css/图片资源,采取强缓存策略,这个时间可以尽可能的长一些,因为是非覆盖式发布,所以如果html中加载资源URI更新,那么资源也会统一的更新
nginx可以对不同文件进行不同的缓存策略,大致配置如下(需要注意location匹配的优先级):
location ~ .*\.(?:jpg|jpeg|gif|png|ico|cur|gz|svg|svgz|mp4|ogg|ogv|webm)$
{
expires 7d;
}
location ~ .*\.(?:js|css)$
{
expires 7d;
}
location ~ .*\.(?:htm|html)$
{
add_header Cache-Control "private, no-store, no-cache, must-revalidate, proxy-revalidate";
}
然后发布的时候先将除html文件移动至发布路径,同名文件默认跳过,新生成的文件会产生新的hash,新旧文件不会冲突,共存在发布路径。
html文件的更新当时做了两种方案
- html完全由前端管理,前端发布的时候会有html文件,webpack打包时自动在html里写文件名;
- html由后端管理(服务器渲染),前端只负责发布js、css等资源文件。在前端发布之后,后端修改版本号再发布;
因为node经验匮乏,当时第二种方案用了python写了一个服务,配置manifest.[chunkhash].js及vendor.[chunkhash].js,如果项目中存在首页骨架屏,那么还需要替换html文件body中的内容,用户服务进来后直接加载这个渲染后的页面。
最后的最后,被一个问题弄的有些头大,面试我的TL反复对我第一种在html中写文件名的方法提出质疑,我当时是真的有点记不清那个plugin的名字了,回到家review了一下项目,那个plugin的名称是html-webpack-plugin,这个问题大概卡了接近10分钟,不知道为什么需要追问这个点,也是自己有点差劲,细节没记得那么清楚。
2.python发布
我就知道我提到了python就会被问这个问题,但没有问服务器渲染的问题,而是问了我django发布的问题,我上一个django项目是两年前的事情了,也可能是第一个问题耗掉了好多经历,思绪有些切换不过来了,表述的不好。
当时只记得是wsgi+apache进行配置的,可能面试我的TL对python了解也不多,又问我这种发布模式不会造成异常中断,说python是即时编译型的语言,这种发布会不会造成异常导致服务全部宕机。我说不会的,这种模式的我们当初采用的定时任务偶尔会挂掉,但是主服务不会的。
我可能有点被TL的思路绕进去了,表述的不好,回来总结过后有了些印象。
3.cdn
答不好什么就会一直往下问,面试如果发现状态不对的话,尽量别被牵着鼻子走吧,这个问题我中间说错了一个环节,导致有点崩,我当时说了我当时部署的项目一部分文件是不走cdn的,可能耐心值达到红色线了,这个是答得是有歧义的。
分场景的话:
- 服务器渲染,那么除html文件均分发一份在cdn上,保证服务器负载
- 频繁更新的配置,比如某些项目是插槽模式嵌入功能的,就需要后端接口生成相应的配置文件,以接口的形式发给前端进行解析。
cdn的配置经验我比较少,公司的业务场景暂时没有提供cdn功能,所有的图片走的是七牛云的cdn,而服务器的css/js文件方面的cdn部署,没有相关的使用经验,面试回到家后一直在找相关的解决方案,如果你有比较好的科普性质的博文,欢迎在评论区留言。
4.项目经验,个人角色
可能前面的问题答得有些失误,为了缓和气氛问了这个问题。因为我之前一直做公司的web前端负责人,所以这个问题聊的比较迅速。我之前的公司是刚开始是没有前端的,我算是半路出家,公司从30人发展到500人,前端团队由2个人发展到接近10个人。然后说了下我主要负责的项目,以及一些团队协作,风险评估,需求评审,代码质量保证的一些事情,可能我做的工作有点low,TL的表情反馈有些平静。
5.gzip编码协议
这个看过一些,大概就是和缓存策略一样,需要在服务器进行配置,同时需要浏览器的支持。
http {
...
gzip on; // 开启gzip
gzip_min_length 1k; // 最小1k的文件才使用gzip
gzip_buffers 4 8k; // 代表以8k为单位,按照原始数据大小以8k为单位的4倍申请内存
gzip_comp_level 5; // 1 压缩比最小处理速度最快,9 压缩比最大但处理最慢(传输快但比较消耗cpu)
gzip_types application/javascript text/plain application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png; // 支持的文件类型
gzip_disable "MSIE [1-6]\."; // IE6一下 Gzip支持的不好,故不实用gzip
...
}
服务器配置之后,会在浏览器请求接口后的response header的Content-Encoding字段看到gzip。
客户端请求数据时,请求头中有个Accept-Encoding声明浏览器支持的压缩方式,当客户端请求到服务端的时候,服务器解析请求头,如果客户端支持gzip压缩,响应时对请求的资源进行压缩并返回给客户端,浏览器按照自己的方式解析。
然后拓展问了下,如果传输的数据希望后端压缩,但是算法没有声明如何启用后端算法。我就模拟了下这个流程,客户端利用header头部的自定义字段将可以容忍的压缩算法告诉服务端,服务端配置允许发送这个自定义header,逐个匹配服务器上当前的算法,匹配到则发送成功结果,无法匹配则告知客服端数据无法进行压缩,等待接下来的操作。
6.用javascript的知识介绍C++的指针
应该是看了我刚毕业的工作是嵌入式方向提出这个问题,这个问题是有点不是好类比的,因为javascript的设计原因,跟传统的编译型语言有很大的不同。我用的是原型链的知识解释的C++指针寻址过程,其中二级指针及三级指针的解释真的需要对两种语言理解很深入才能回答上来。原型链的东西已经在电话一章节阐述,此处类似,不再阐述,对C++有兴趣的话,推荐多看一下大学课本类似的书籍,干货很多。
7.高精度计时器
算是一个解决方案的问题,面试官列举了一个有赞整点抢单的业务场景,如何同步所有客户端的时间。由于setTimeout类似的计时器无法高精度还原时间,我提出的想法是利用socket保持和服务器的长链接,利用推送的模式,定期给客户端发送当前服务器时间作为校验基准,但是由于HTTP传输的时间无法保证,所以也只能尽可能的同步两端的时间。
面试官又问了这个服务器推送的频率你认为大概需要多少,因为没有相关业务经验,只能按照逻辑推理,这个我的描述是当前服务器时间 = 服务器系统返回时间 + 网络传输时间 + 前端渲染时间 + 校准常量(可选),所以这个推送的频率采用变频的思路,就是离活动时间有一段时间,那么推送频率大概1分钟2次左右,马上快开始就需要频繁推送了,socket性能问题需要通过不断的矫正才能达到最好的效果,但是如果想100%实现高级度的计时器,以我目前的知识面看,还是存在很多问题的。
其实这个问题我在C++中就时间过,如果想测试超高级度的定时器,需要中间没有阻塞线程或者进程,以及防止计算机优先级较高的任务中断,这个知识涉及到操作系统的好多知识,大概就说到这。
对于这个问题我还是很感兴趣的,因为我面试后发现很多这种活动都有这个时间误差的问题,或大或小。如果你有过相关的业务场景,欢迎留言区分享你的思路。
8.提取最长有效数字
技术面试过程的最后感觉自己可能没戏了,没想到还被问了一个现场编码的题目,大致题意如下:
Input:
'1024word'' -1024word''word1024''10word24'
Output:
1024-1024010
程序大概写了不到5分钟吧,印象不是太深刻了,代码写的有点多,可以更简单,欢迎在评论区写出你耳目一新的代码段。
function parseInt (value) {
// 输入值校验合法性
if (!value) { return 0; }
// 本需求对于空格需要剔除
let temp = value.toString().trim();
// 拦截全空字符串问题
if (temp.length === 0) {
return 0;
}
// 收集符号位
let result = temp[0] === '+' || temp[0] === '-' ? temp[0] : '';
// 设置开始索引
let i = result.length > 0 ? 1 : 0;
// 遍历,此处使用for循环为了方便中断遍历减少时间复杂度
for (;i < temp.length; i++) {
if (temp[i] >= '0' && temp[i] <= '9') {
result += temp[i]
} else {
break;
}
}
// [防爬虫标识-掘金-沙海听雨]
// 判断存在result为符号位造成Number('+')输出NaN问题
return result && (result === '+' || result === '-') ? 0 : Number(result)
}
问了能不能换种方法实现,我想了一下,说正则提取可以做到,但是当时就给了10分钟不到的时间,就没再继续了,其实是之前的问题把思路打乱了,一直在回忆之前没答好的问题。
[补充1.0.1]
根据评论区Akihi09大佬的正则表达式启发,想出了一个正则表达式写法
function parseInt (val) {
if (typeof val !== 'string') { return 0; }
let match = val.toString().trim().match(/[+|-]{0,1}[0-9]*/g)[0];
if (!match) {
return 0;
}
return Number(match)
}
[补充1.0.3]
附录评论区liuyu322的正则表达式,
function parseInt (val) {
if (!val || typeof val !== 'string') { return 0; }
return +val.toString().replace(/^\s*([-+]?\d+)?.*$/, ($0, $1) => $1 || 0)
}
这个表达是里面用到的概念有点多,一直没有时间更新,其中几个关键点,在此处分析一下。
^以什么为开始
\s匹配任意的空白符
*只匹配出现 0 次及以上 * 前的字符
()分组 []匹配方括号内的任意字符
?之前字符可选
\d匹配数字
+只匹配出现 1 次及以上 + 前的字符
.匹配任意字符除了换行符和回车符(贪婪匹配)
了解这个概念应该就对上边的公式有所了解,附上一篇我认为比较好的正则匹配文章可能是最好的正则表达式的教程笔记了吧
9.最后聊了一会骨架屏
好文推荐:饿了么的 PWA 升级实践
聊天内容大多是根据这篇文章我进行的一些尝试,但是没有脱离文章的中心。
10.面试的反馈
前端方面接触面过于窄,告诉我可以多拓展一下比如React和Node的一些实践经历,其他还有一些关于职业发展的方向,比较琐碎。
后记
本来感觉结束了,整体单方面被虐,没想到TL说等一下,让hr来找我聊聊,有点意外,等了大概10分钟吧,hr小姐姐就过来进行人事面。
hr面
这个面试流程我就基本精炼一下:
- 询问了公司经历,就是为什么入职为什么离职
- 由于我做技术比较杂,城市也比较多,聊了好久一阵子,可能是怕我简历有水分吧
我大学时期做ASP.Net,大学毕业第一份工作是C/C++嵌入式,后来又做了近一年的Django开发,最近两年才开始专一从事前端,所以这个聊的比较多,我觉得一个人能快速适应各种语言,算是一个优势吧,能侧面反应计算机基础,但另一方面广度过于宽会导致深度不够,这个我开始逐渐调整,由于掌握的语言比较多,所以上手很多技术还是很快的。 - 询问了个人发展规划
我的期许就是待遇上匹配的上时间成本,最重要的是想在一家规模比较大的企业做的久一些,沉淀一下业务能力和技术视野,大公司遇到的场景、并发、极端交互还是很令我向往的。 - 聊了下期许的薪资
我大概说了个数字,反正很诚心吧,有很大谈的余地,因为真的想跳出目前一直在小公司怪圈。 - 聊了整个面试流程感觉如何
- 说了合适的话会打电话沟通,不合适的话会发邮件通知原因
后记
hr面试让我心里有些释怀,一扫之前技术面的紧张感,出门的时候如释重负吧,算是一个小阶段的结束,为了这个面试大概准备了1个多月,后来可能太紧张又是杭州梅雨季,回到家有些低烧,都是小插曲了。
最后的最后,等了大概一周多吧,还是没有消息,我对面试还是特别有诚意的,想等到结果再进行下一步,就问了内推我的朋友,得知面试被淘汰了,没接到正式婉拒通知有点小意外,可能各种原因,当个经历继续前行吧。
准备
javascript基础
看了yck大大总结的前端知识点小结,在掘金应该是有掘金小册,有条件的话可以购买,我平时当作javascript基础的归纳总结大纲查缺补漏,有好多点都有被问到。
yuchengkai.cn/docs/fronte…
还有一本书挺好的,《你不知道的javascript》一共分3册,有些点描述的挺深刻的,是个常读常新的好书。
其他就是多看多总结,每个开发者都有个自己的小知识库吧,我大多都是写在云笔记里面了,最近打算整理一下不定期发布出来。
css
这方面的话没有过多的准备,基本都是平时移动端+PC端开发过程中实际编码的经验,但有一些点不是太好钻进去,在这里简单说下。
css动画效果,这个完全看自己平时的业务场景,也可能看一些源码库,推荐animate.css这个开源库,很经典代码结构也很清晰
github.com/daneden/ani…
关于webGL这方面的知识,这个真的随缘,有过相关业务的话,面试过程应该不至于冷场想要突击的话,不是太适合。
另外css3有本书也不错,《css揭秘》,可能当字典看。特别基础的css知识,推荐MDN或者一些写的比较好的文档了。
框架相关
看源码,看开源社区,有很多优质的文章值得花费时间去阅读。
这里写一个我的一个小技巧吧,因为之前写后段比较多,而且调试的经验也超级多,一直想能不能前端代码调整也能那么智能一些,还真被我找到了一个小技巧。
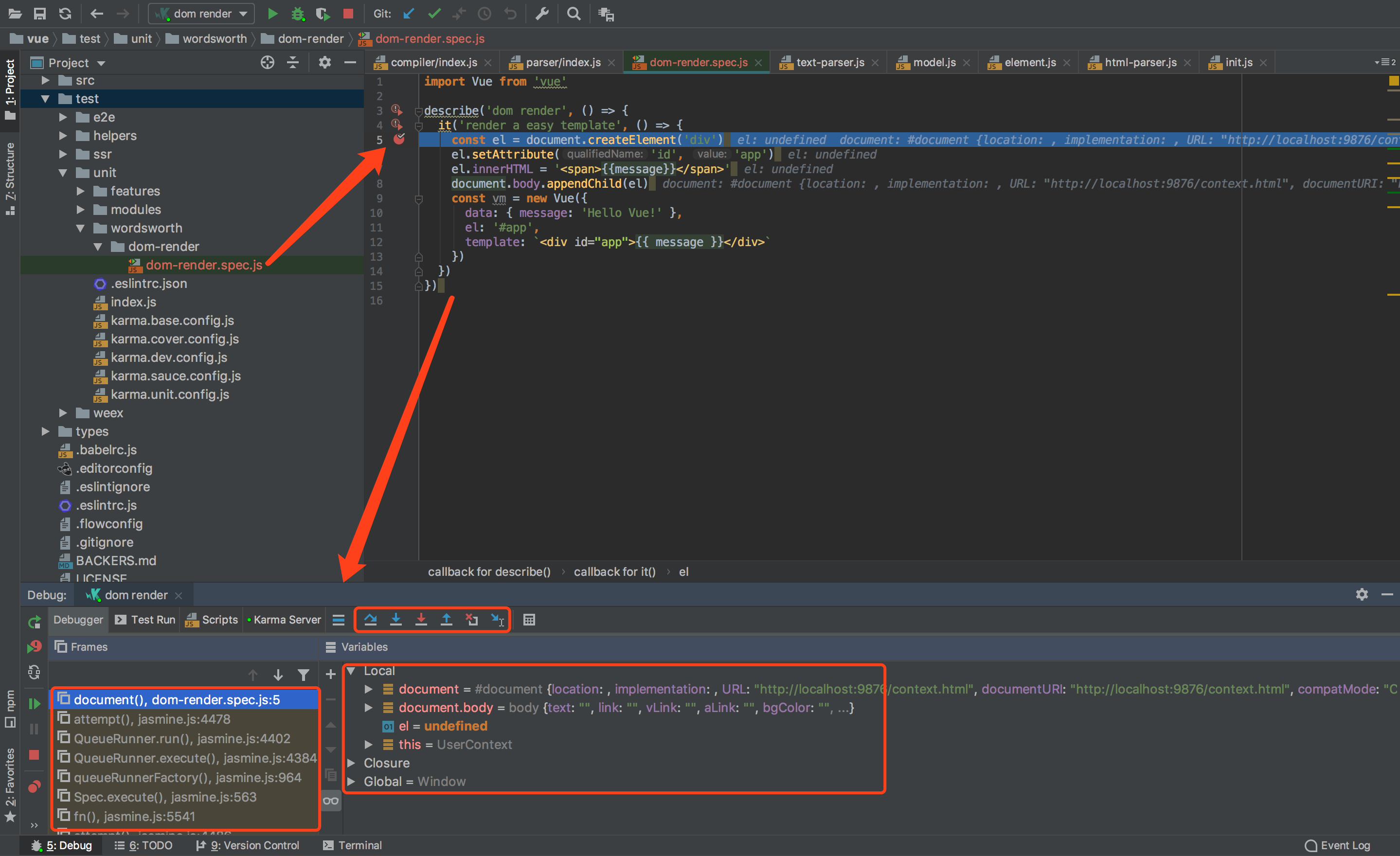
WebStrom对Karma单体测试支持特别好,可以看到临时变量以及代码段步入,对框架源码某处不懂,写一个小的测试用例提高测试覆盖率,就能很容易的理解源码中晦涩难懂的一些代码段了,上一张截图,用了都说好。
// 首先定义一个xxx.spec.js
// [防爬虫标识-掘金-沙海听雨]
import Vue from 'vue'
describe('dom render', () => {
it('render a easy template', () => {
const el = document.createElement('div')
el.setAttribute('id', 'app')
el.innerHTML = '<span>{{message}}</span>'
document.body.appendChild(el)
const vm = new Vue({
data: { message: 'Hello Vue!' },
el: '#app',
template: `<div id="app">{{ message }}</div>`
})
})
})
前端工程化
这方面总结的东西比较多,推荐从自己的简历经验上多提炼一下,在掘金上看到一篇文章比较好,大型项目前端架构浅谈可以在里面找到一些启发,并从你的项目经历中提炼出一些关键点。
总结
经历了完整的大企业面试算是对自己的一个自我认知的过程,虽然中间经历还是比较曲折的,但是算是成长吧,今年逆形式找工作还是有些吃力的,但是还是期待大公司的工作机会吧。
如果你觉得本文对你有些许的帮助,或者能博您深思,别忘点个赞加个关注或是留下你的看法和见解。
同时期待能与您共事,欢迎并期待重新出发的机会,简历的话欢迎留下您的邮箱索取。
辛苦阅读本文
以上
沙海听雨(Wordsworth)
参考文章:
[1] InterviewMap-yck yuchengkai.cn/docs/fronte…
[2] HTTP强缓存和协商缓存-puhongru segmentfault.com/a/119000000…
