PHP爬虫 -- 008 爬虫初探
什么是爬虫?
- 从本质上来说,就是利用程序在网上拿到对我们有价值的数据
- 爬虫能做很多事,能做商业分析,也能做生活助手,
- 比如:分析北京近两年二手房成交均价是多少?
- 深圳的Python工程师平均薪资是多少?
- 北京哪家餐厅粤菜最好吃?等等。
- 这是个人利用爬虫所做到的事情,而公司,同样可以利用爬虫来实现巨大的商业价值。
- 比如你所熟悉的搜索引擎——百度和谷歌,它们的核心技术之一也是爬虫,而且是超级爬虫。
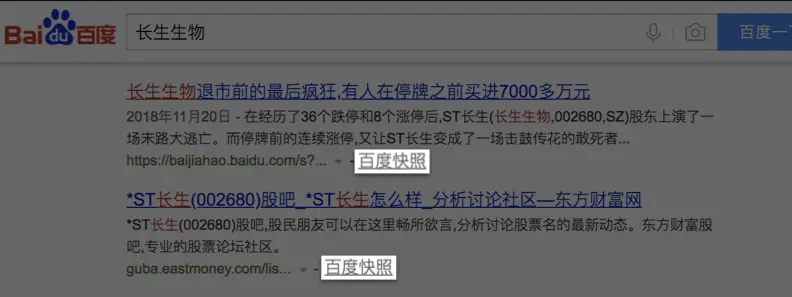
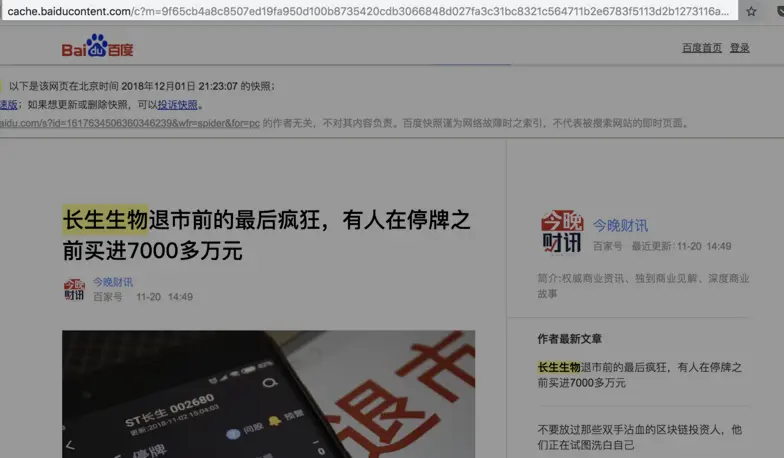
- 百度这家公司会源源不断地把千千万万个网站爬取下来,存储在自己的服务器上。
- 你在百度搜索的本质就是在它的服务器上搜索信息,
- 你搜索到的结果是一些超链接,在超链接跳转之后你就可以访问其它网站了
浏览器工作原理
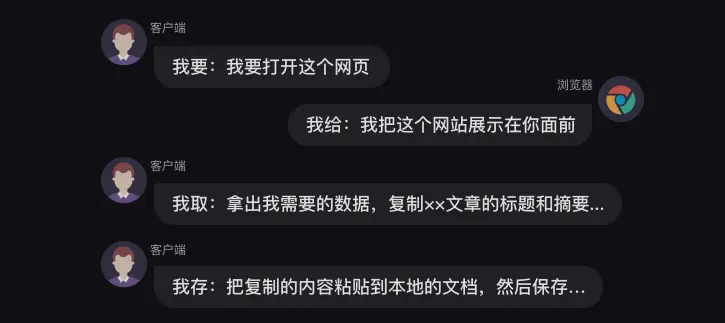
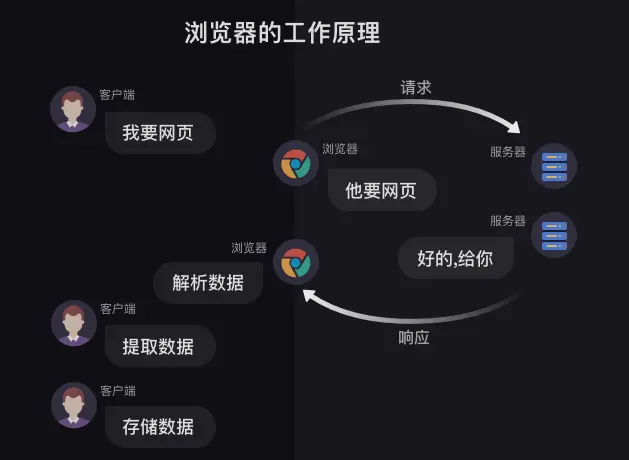
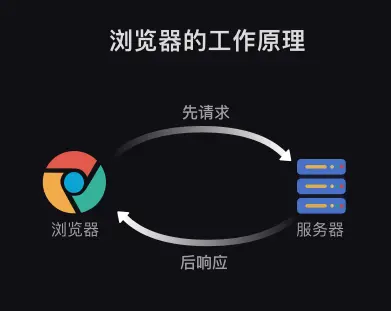
- 当服务器把数据响应给浏览器之后,浏览器并不会直接把数据丢给你。
- 因为这些数据是用计算机的语言写的,浏览器还要把这些数据翻译成你能看得懂的样子,
- 这是浏览器做的另一项工作【解析数据】。
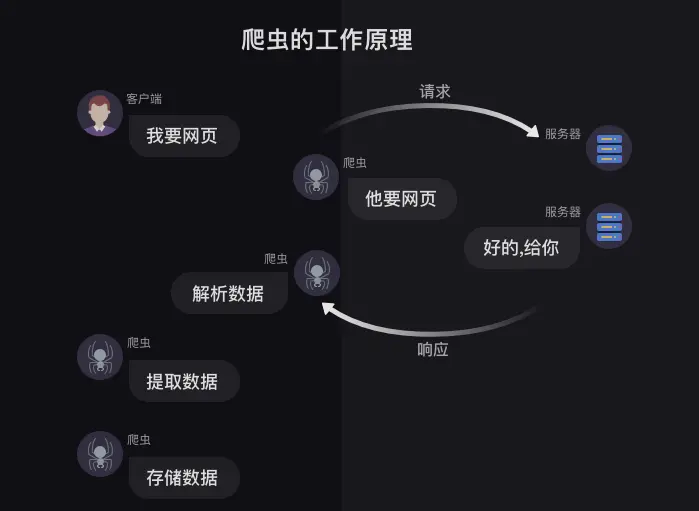
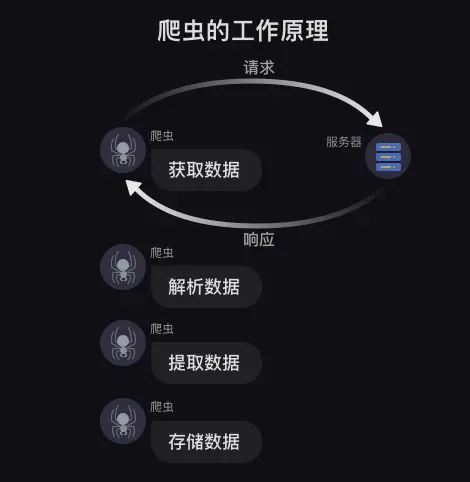
爬虫的工作原理

状态码
- 不是每一次请求就一定能成功, 我们需要判断请求的结果
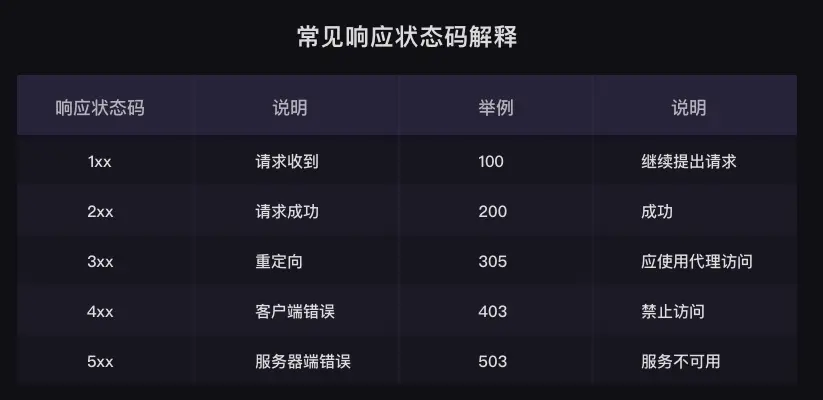
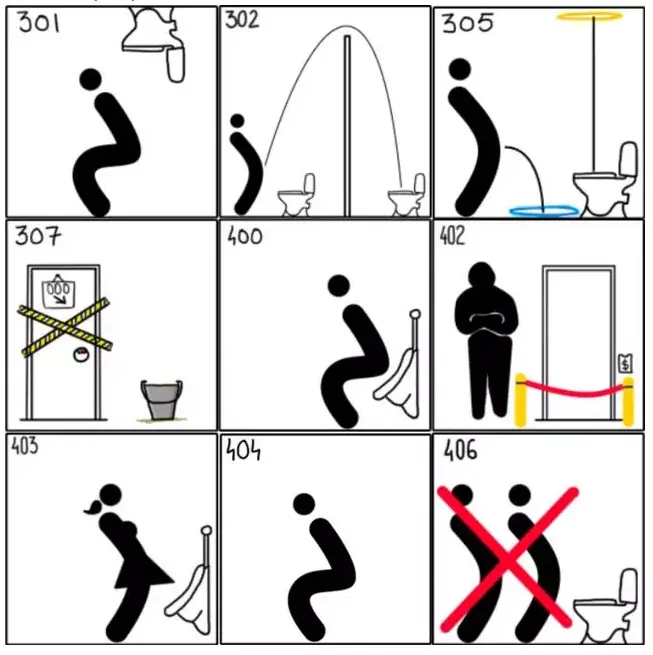
- 301—永久移动。被请求的资源已被永久移动位置;
- 302—请求的资源现在临时从不同的 URI 响应请求;
- 305—使用代理。被请求的资源必须通过指定的代理才能被访问;
- 307—临时跳转。被请求的资源在临时从不同的URL响应请求;
- 400—错误请求;
- 402—需要付款。该状态码是为了将来可能的需求而预留的,用于一些数字货币或者是微支付;
- 403—禁止访问。服务器已经理解请求,但是拒绝执行它;
- 404—找不到对象。请求失败,资源不存在;
- 406—不可接受的。请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体;
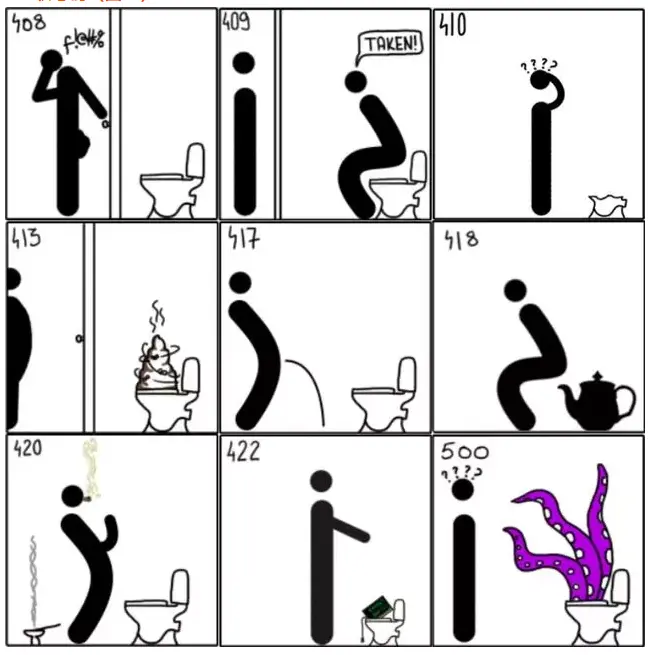
- 408—请求超时;
- 409—冲突。由于和被请求的资源的当前状态之间存在冲突,请求无法完成;
- 410—遗失的。被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址;
- 413—响应实体太大。服务器拒绝处理当前请求,请求超过服务器所能处理和允许的最大值。
- 417—期望失败。在请求头 Expect 中指定的预期内容无法被服务器满足;
- 418—我是一个茶壶。超文本咖啡罐控制协议,但是并没有被实际的HTTP服务器实现;
- 420—方法失效。
- 422—不可处理的实体。请求格式正确,但是由于含有语义错误,无法响应;
- 500—服务器内部错误。服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理;
下一节


