

介绍
这系列的文章如下
垃圾回收器负责追踪堆内存的分配,释放掉不需要的空间,追踪那些还在使用的分配空间。不同编程语言对这个机制的实现都很复杂,但是开发人员开发软件时候并不需要了解垃圾回收太细节的东西就能进行构建。另外,不同发布版本编程语言的VM和runtime也总是在改变和进化。对于应用开发人员来说,重要的是保持一个良好的work模型,了解编程语言里垃圾回收器的行为并且它们是怎么样支持这种行为的。
对于go 1.12版本来说,go语言使用了非分代,并发的三色标记和清扫的回收器。如果想了解如何进行标记和清扫的工作,请参考这篇文章。golang的垃圾回收器的实现每个版本都在更新和进化。因此一旦下个版本发布,讲任何细节的实现都不再准确。
总而言之,这篇文章不会去讲实际的实现细节。我会为你分享回收器的一些行为并且去解释怎样面对这些行为,不考虑实现细节以及未来的改变。这将会使你成为一个更好的golang开发者
堆不是一个容器
我不会把堆看做是一个可以存储或者是释放值的容器。理解这件事情很重要,内存里并没有明确定义了“堆”的一个分界线。任何应用程序预留的内存空间,在堆内存分配上是可用的。给定任何堆内存分配空间,它实际在虚拟内存还是物理内存上的存储位置和我们的模型并没有关联。理解这件事情会帮助你更好的理解垃圾回收模型的工作方式。
回收器行为
当回收开始,回收器会完成三个阶段的工作。这其中两个阶段会产生Stop The World(STW) 延迟,并且另一个阶段也会产生延迟,并且会导致降低应用程序的吞吐量。这三个阶段是:
- Mark Setup - STW
- Marking - Concurrent
- Mark Termination -STW
下面看各个阶段的详细说明。
Mark Setup -STW
当回收开始,首先要做的肯定是开启写屏障(Write Barrier)。写屏障的目的是在collector和应用程序goroutines并发时候,允许回收器去维持数据在堆中的完整性。
为了开启写屏障,每个运行中的应用程序goroutine必须要停下来。这个活动通常非常快,平均在10~30微妙之间。前提是在你的应用程序goroutines行为合理的情况下。
注意:为了更好的理解下面的调度图解,最好先看过之前写的golang调度文章
图1.1
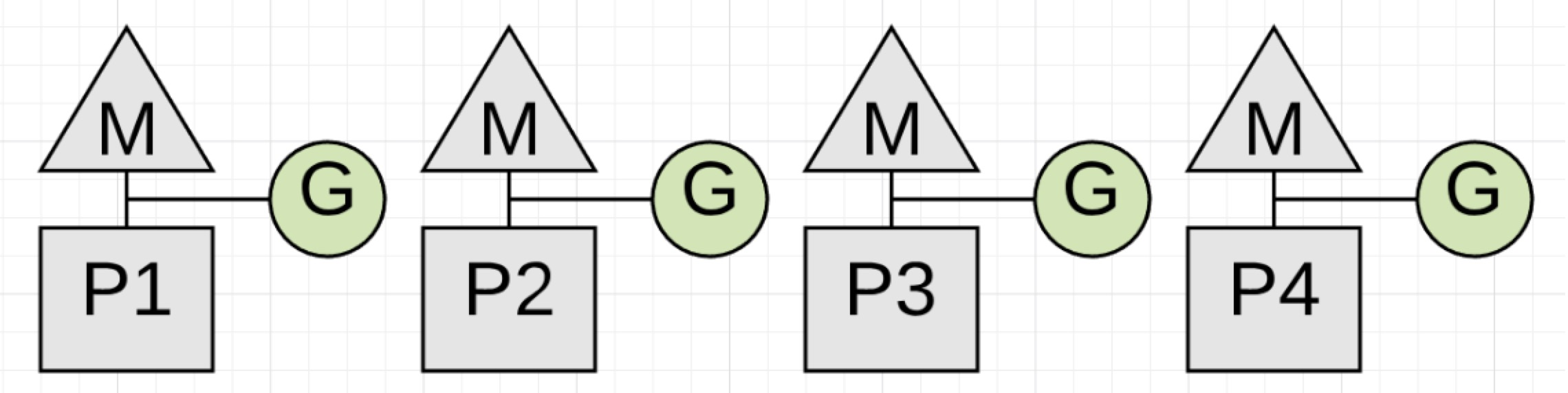
图1给出了4个应用程序goroutines,在开始垃圾回收之前它们都在运行中。为了进行回收,4个goroutines中每一个都必须被停下来,这么做的唯一方式就是让回收器去检查并等待goroutine去做方法调用。方法调用确保了goroutines在安全的点停下来。如果其中一个goroutine没有进行方法调用但是其它的做了方法调用,会发生什么?
图1.2
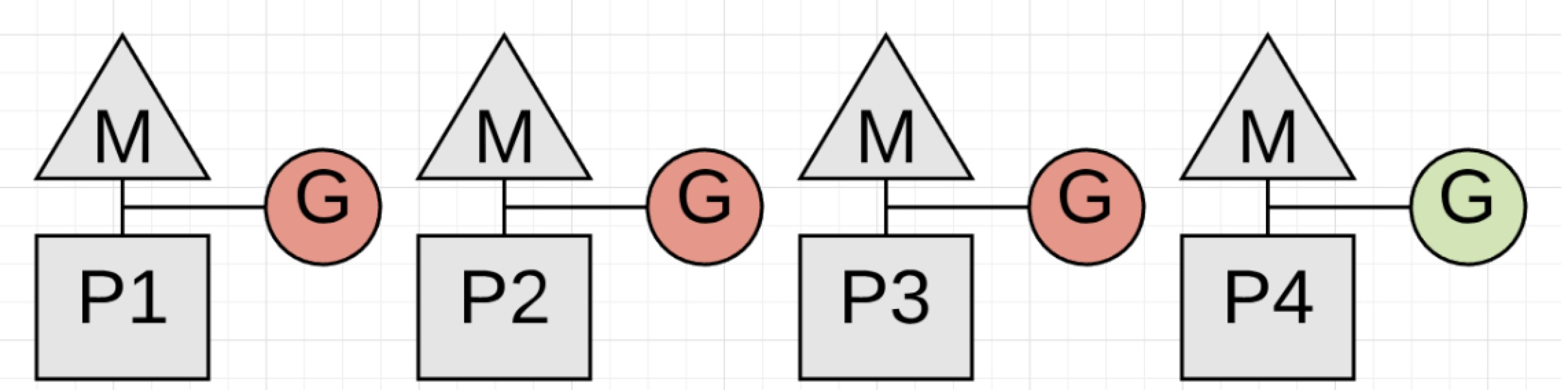
图1.2给出了一个问题的实际案例。如果P4的goroutine不停下来的话,垃圾回收就无法启动。但是P4正在执行一个tight loop去做一些math处理,这导致回收根本无法开始。
L1:
01 func add(numbers []int) int {
02 var v int
03 for _, n := range numbers {
04 v += n
05 }
06 return v
07 }
L1给出了P4 goroutine正在执行的代码。取决于slice的大小,goroutine可能会执行很长很长的时间,导致了根本没有机会停下来。这种代码会阻止垃圾回收开始。更糟糕的是,其他的P无法为其他goroutine服务,因为collector处于等待状态。所以goroutine在合理的实际范围内进行方法调用是至关重要的。
注意:这部分是golang团队将在1.14版本中要改进的内容,通过加入调度器的抢占式调度技术
Marking -Concurrent
一旦写屏障开启,回收器就会开始进入都标记阶段。回收器第一件做的事情就是拿走25%的可用CPU给自己使用。collector使用Goroutines去进行回收工作,也就是它会从应用程序抢过来对应数量的P和M。这意味着,4个线程的go程序里,会有一个P被拿去处理回收工作。
图1.3
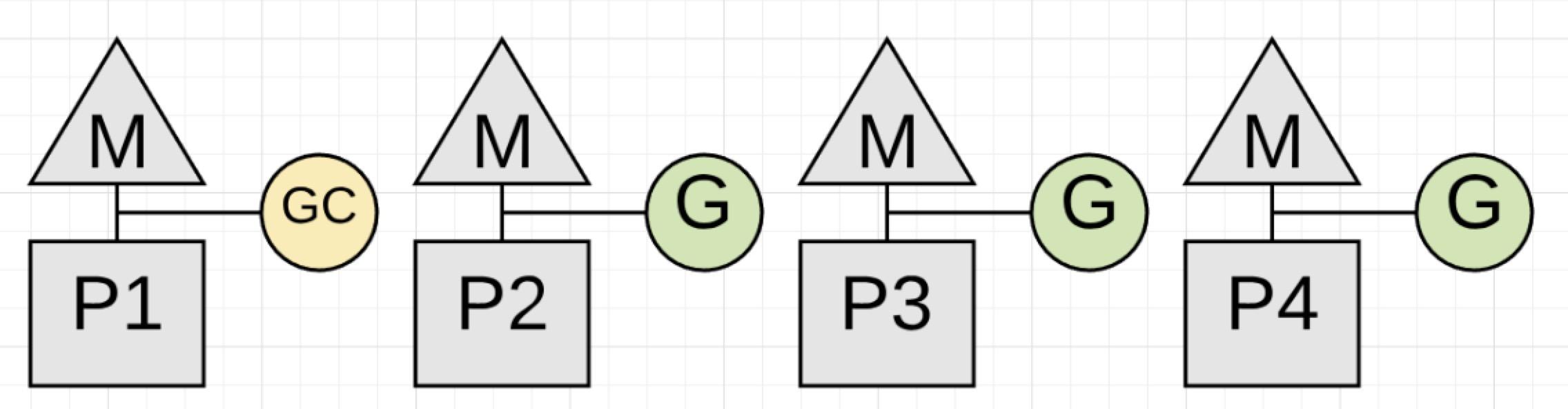
图1.3给出了collector是怎样拿走P1的在进行回收工作的时候。现在回收器可以开始Marking过程了。标记阶段就是标记处理堆内存中的in-use的值。它会去检查栈中所有存在的goroutines,去找到指向堆内存的根指针。之后回收器必须从根指针开始,遍历堆内存的树图。当P1上进行处理Marking工作,应用程序可以在P2、P3和P4上继续并发执行。这意味着回收器减少了当前CPU容量的25%。
我希望事情到此就结束了,但是并不是。如果P1上GC的goroutine在in-use的堆内存达到上限时候没完成Marking会怎么样?如果其他3个应用程序的goroutine导致了collector无法按时完成工作会怎么样?如果发生这种情况,新的内存分配就必须慢下来,尤其是在对应的goroutine上。
如果回收器确定它必须要减慢内存分配速度,它就会招募应用程序的goroutines去协助(Assist)进行标记工作。这叫做Mark Assist。任何应用程序goroutine被置入Mark Assist的时间和它将要在堆内存中加的数据量是成比例的。Mark Assist的一个正面功能就是它帮助提高了回收速度。
图1.4
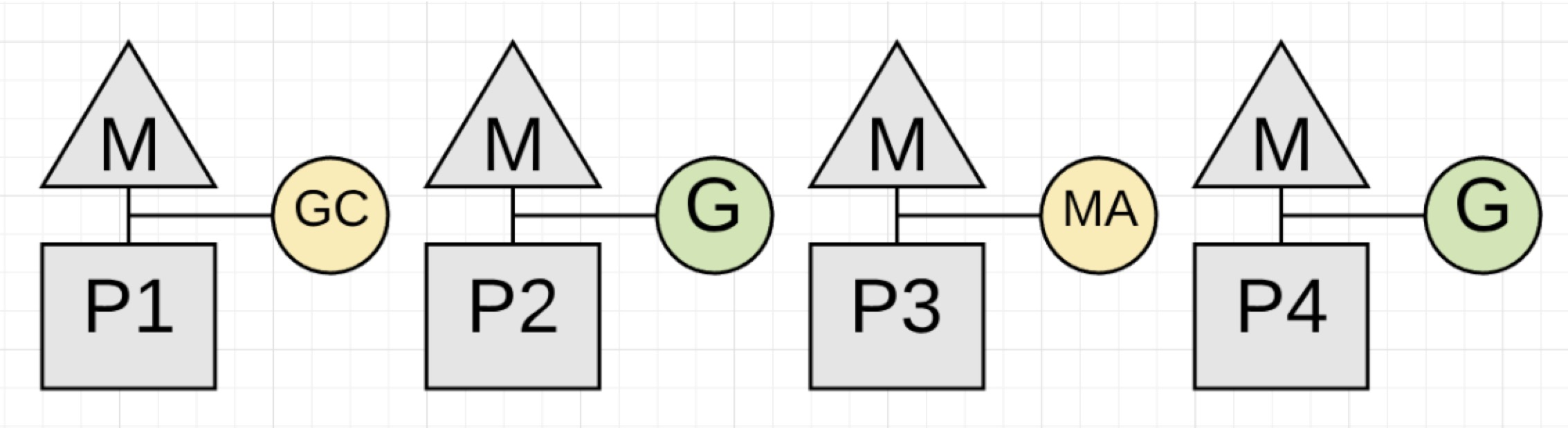
图1.4展示了,之前P3上应用程序运行的goroutine,现在正在进行Mark Assist来帮助进行回收工作。希望其他goroutines不要参与其中。应用程序有分配内存压力的时候会看到大部分正在运行的goroutines在垃圾回收的时候去处理小量的Mark Assist工作。
Mark Termination -STW
一旦标记工作完成,下一个过程就是Mark Termination。这个时候写屏障关闭,各种清理工作会进行,并且计算出下一次的回收目标。在标记过程中那些发现自己处理tight loop的goroutines也会导致Mark Termination STW的延时增加。
图1.5
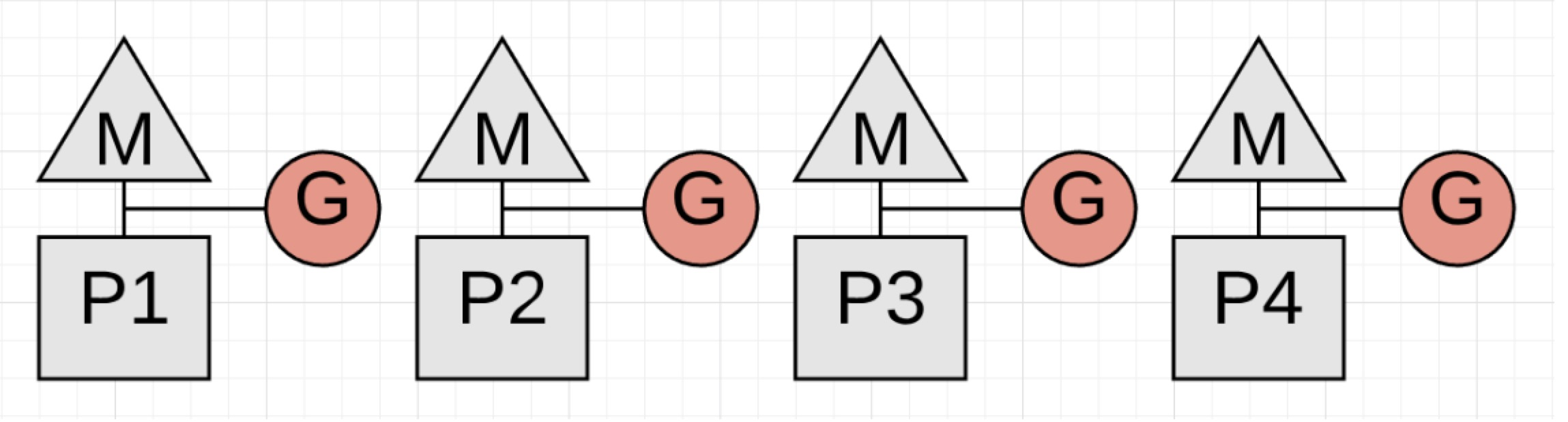
一旦回收完成了,每个P可以再次被应用程序goroutines去使用,程序又回到了全力运行的状态。
图1.6
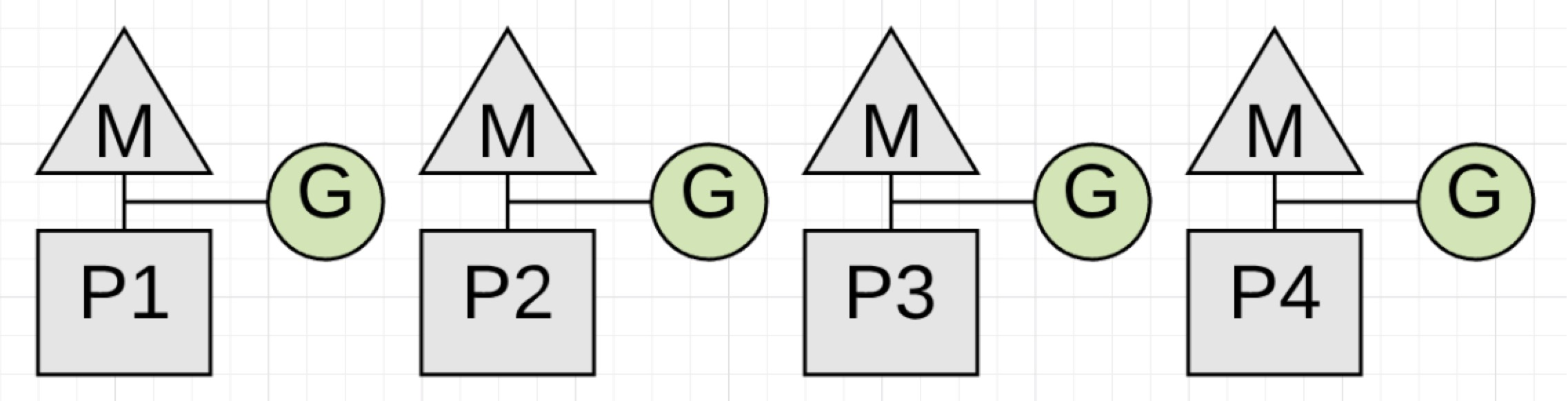
图1.6展示了回收完成后,全部可用的P现在正在处理应用程序的工作。
Sweeping - Concurrent
在回收完成之后,会有另外一个活动,叫做清扫(Sweeping)。Sweeping就是清理内存中有值但是没有被标记为in-use的堆内存。这个活动发生在当应用程序goroutines尝试去在堆中分配新的值的时候。Sweeping延迟增加到了堆内存分配的开销中,并且和任何垃圾回收的延迟都没有关联。
下面是在我的机器上进行trace的样本,我的机器上有12个hardware thread去执行goroutines。
图1.7
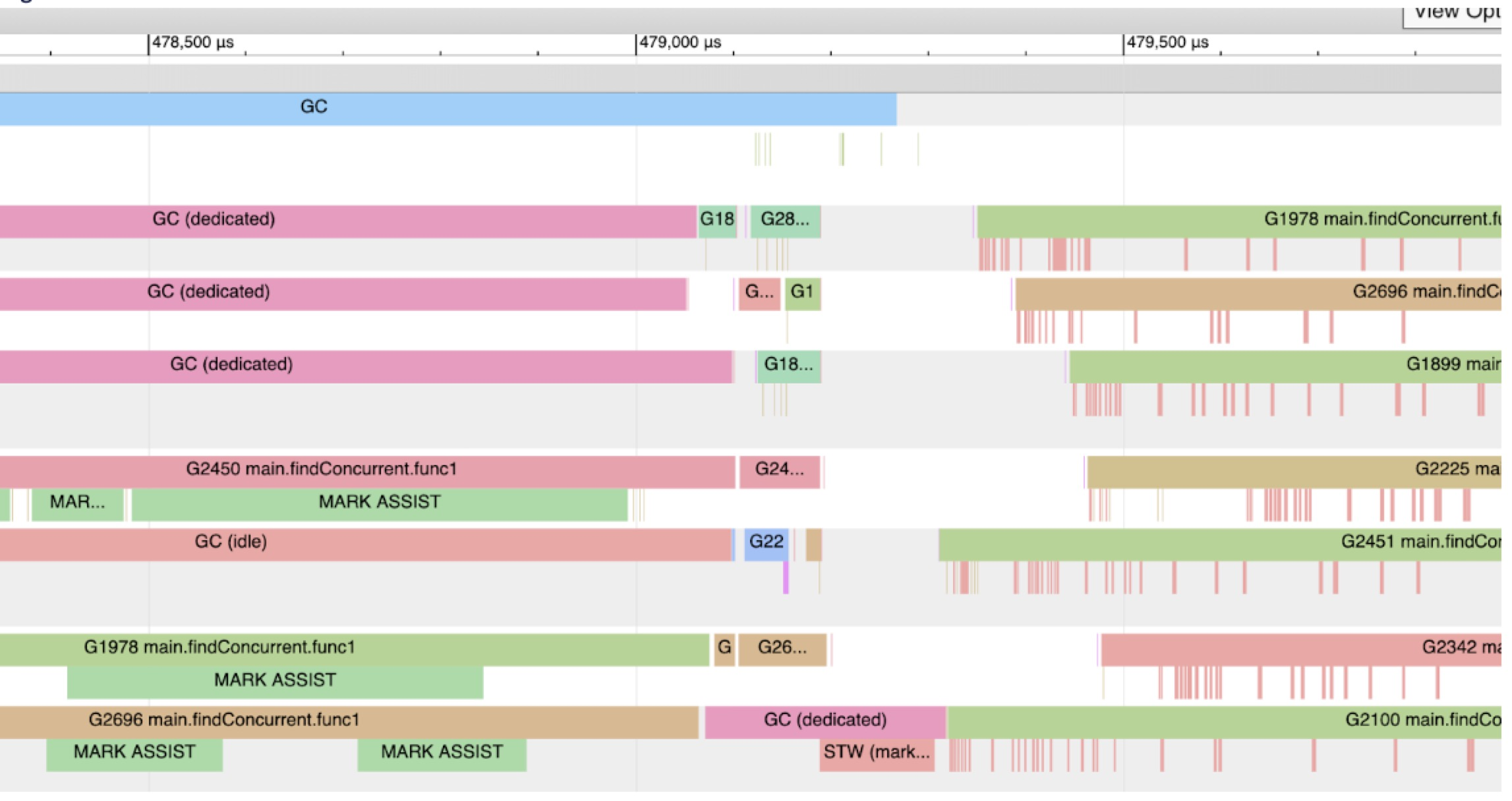
在回收完成后,程序又回到了全力运行的状态。你可以看到在这些goroutine下面的许多玫瑰色的竖线。
图1.8
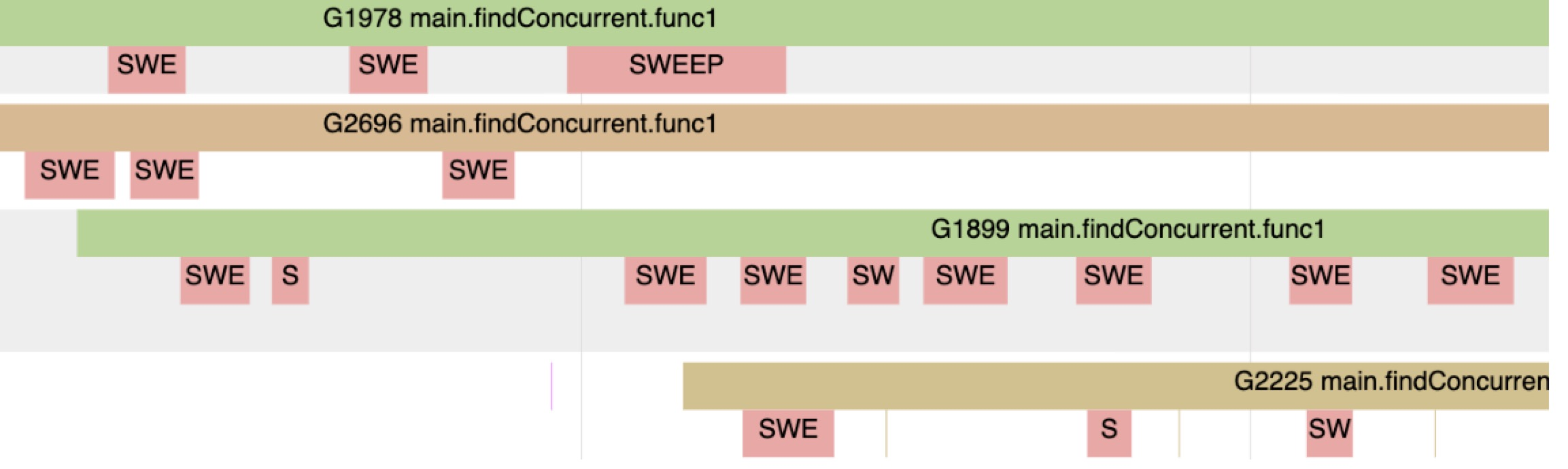
图1.9
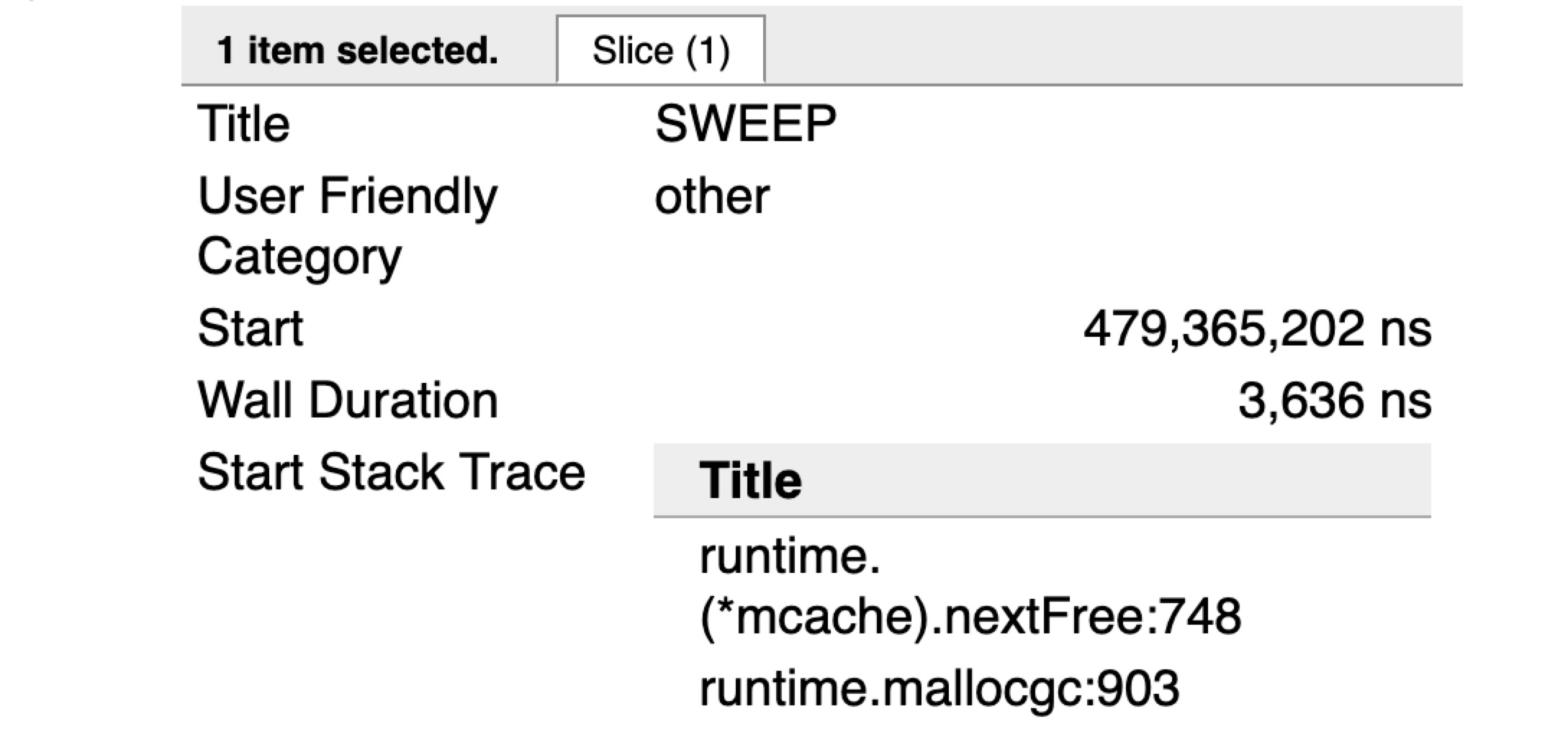
runtime.mallocgc的调用会去在堆中分配新的值。runtime.(*mcache).nextFree调用会导致Sweeping。一旦堆中不再有分配的内存需要回收,nextFree就不会再看见。
上面描述的回收行为仅仅发生在当回收已经启动并正在处理的过程中。在确定什么时候开始回收中,GC配置选项扮演了重要的角色。
GC percentage
runtime中有一个配置选项叫做 GC Percentage,默认值是100。这个值代表了下一次回收开始之前,有多少新的堆内存可以分配。GC Percentage设置为100意味着,基于回收完成之后被标记为生存的堆内存数量,下一次回收的开始必须在有100%以上的新内存分配到堆内存时启动。
作为例子,想象回收完成了并标记了2MB的in-use堆内存。
注意:图表中的堆内存不代表实际情况。go中的堆内存通常都是凌乱的碎片化的,你不会有图表中那种清晰的区分。这些图表提供了一个方便的可视化的堆内存模型来方便理解。
图1.10

图1.11

L2
GODEBUG=gctrace=1 ./app
gc 1405 @6.068s 11%: 0.058+1.2+0.083 ms clock, 0.70+2.5/1.5/0+0.99 ms cpu, 7->11->6 MB, 10 MB goal, 12 P
gc 1406 @6.070s 11%: 0.051+1.8+0.076 ms clock, 0.61+2.0/2.5/0+0.91 ms cpu, 8->11->6 MB, 13 MB goal, 12 P
gc 1407 @6.073s 11%: 0.052+1.8+0.20 ms clock, 0.62+1.5/2.2/0+2.4 ms cpu, 8->14->8 MB, 13 MB goal, 12 P
L2展示了如何使用GODEBUG变量去生成GC trace。下面的L3展示了程序生成的gc traces。
L3
gc 1405 @6.068s 11%: 0.058+1.2+0.083 ms clock, 0.70+2.5/1.5/0+0.99 ms cpu, 7->11->6 MB, 10 MB goal, 12 P
// General
gc 1404 : The 1404 GC run since the program started
@6.068s : Six seconds since the program started
11% : Eleven percent of the available CPU so far has been spent in GC
// Wall-Clock
0.058ms : STW : Mark Start - Write Barrier on
1.2ms : Concurrent : Marking
0.083ms : STW : Mark Termination - Write Barrier off and clean up
// CPU Time
0.70ms : STW : Mark Start
2.5ms : Concurrent : Mark - Assist Time (GC performed in line with allocation)
1.5ms : Concurrent : Mark - Background GC time
0ms : Concurrent : Mark - Idle GC time
0.99ms : STW : Mark Term
// Memory
7MB : Heap memory in-use before the Marking started
11MB : Heap memory in-use after the Marking finished
6MB : Heap memory marked as live after the Marking finished
10MB : Collection goal for heap memory in-use after Marking finished
// Threads
12P : Number of logical processors or threads used to run Goroutines
L3展示了GC中的实际数值和它的含义。我最后会讲到这些值,但是现在注意1405 GC trace的内存片段。
图1.12
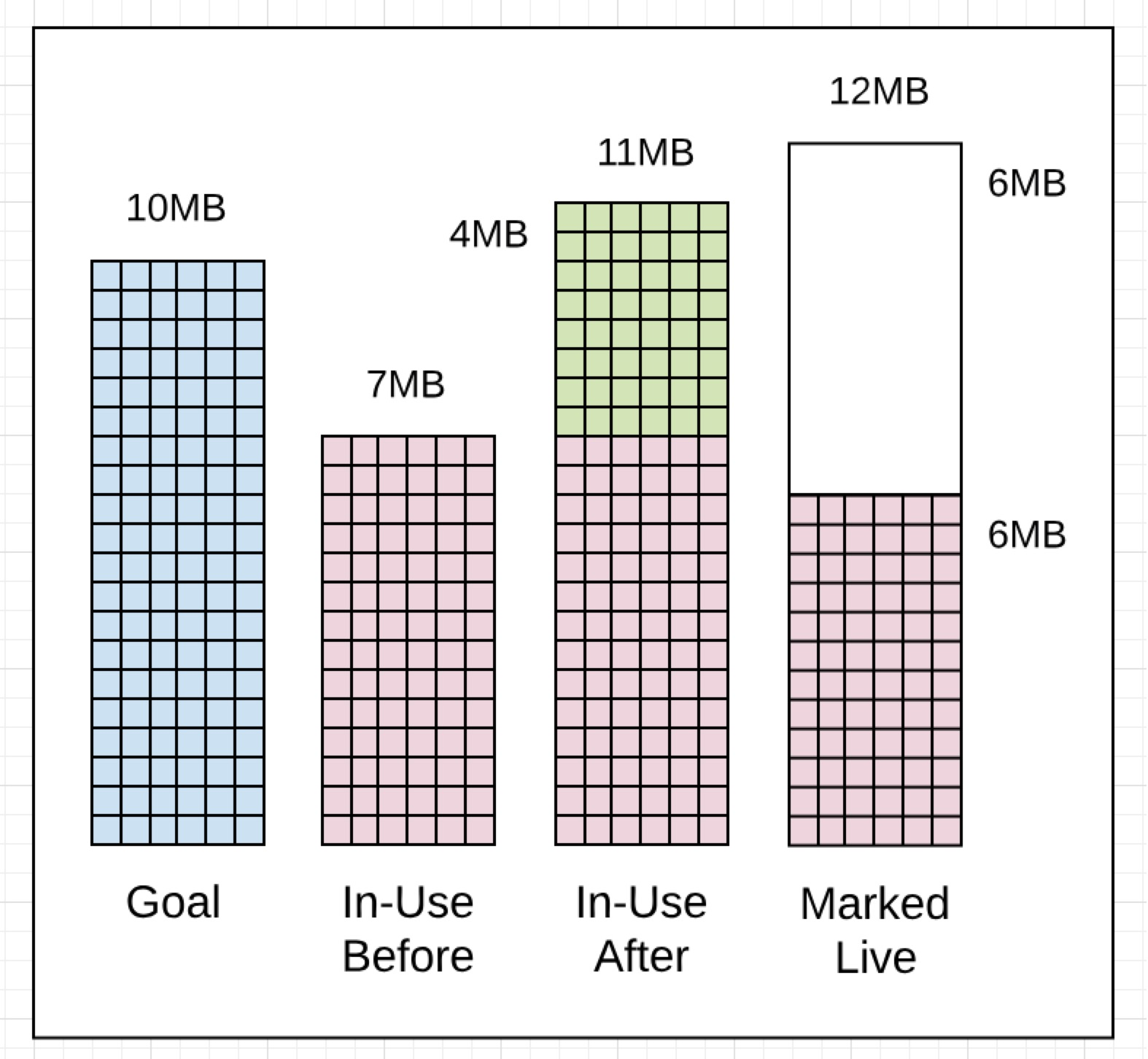
L4
// Memory
7MB : Heap memory in-use before the Marking started
11MB : Heap memory in-use after the Marking finished
6MB : Heap memory marked as live after the Marking finished
10MB : Collection goal for heap memory in-use after Marking finished
GC trace行给出了如下的信息:Marking Work开始之前堆内存中in-use大小是7MB。当Marking Work完成后,堆内存中in-use的大小是11MB。这意味着回收中额外增加了4MB的内存分配。Marking Work完成之后堆内存中存活空间的大小是6MB。这意味着下次回收开始之前,in-use堆内存可以增加到12MB(100%*生存堆内存大小=6MB)
你可以看到回收器超过了它设定的目标1MB,Marking Work完成之后的in-use堆内存是11MB而不是10MB。但是没关系,因为目标是根据当前in-use的堆内存计算得到的,也就是堆内存中标记为生存的空间,当回收进行的时候会有额外随时间计算增加的内存分配。在这个案例里,应用程序做了一些事情,导致在Marking之后,需要比预期更多去使用的堆内存。
如果你看下一个GC Trace 行(1406),你开会看到在2ms内事情是如何改变的。
图1.13
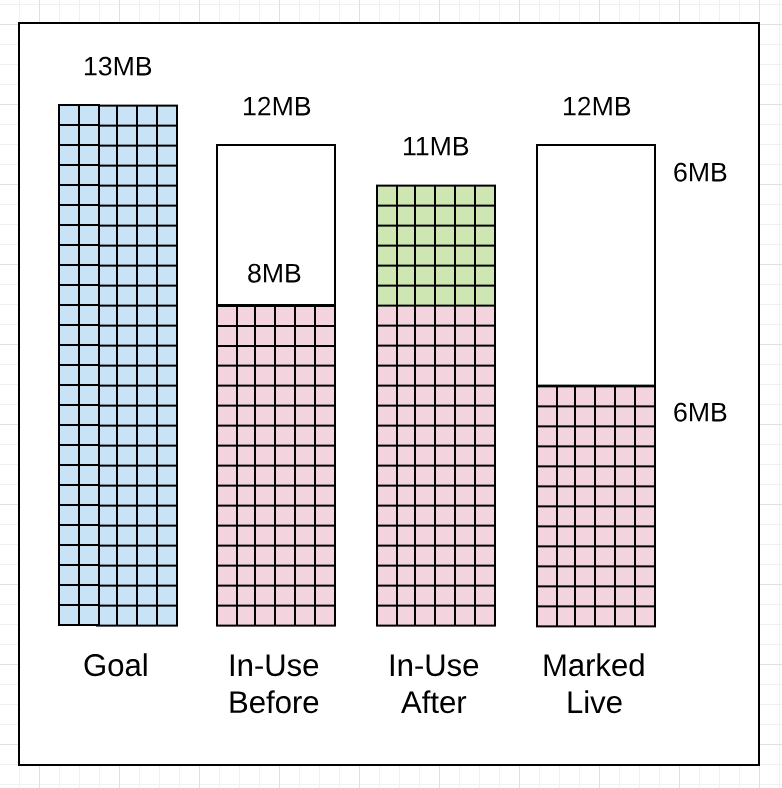
gc 1406 @6.070s 11%: 0.051+1.8+0.076 ms clock, 0.61+2.0/2.5/0+0.91 ms cpu, 8->11->6 MB, 13 MB goal, 12 P
// Memory
8MB : Heap memory in-use before the Marking started
11MB : Heap memory in-use after the Marking finished
6MB : Heap memory marked as live after the Marking finished
13MB : Collection goal for heap memory in-use after Marking finished
L5展示了在之前的回收工作开始之后(6.068s vs 6.070s)这个回收工作开始了2ms的状态,尽管in-use的堆内存在允许的12MB中仅仅达到8MB。需要注意到,如果回收器决定最好要早一点开始进行回收的话,它就会那么做。这个案例下,它可能提前开始回收了,因为应用程序的分配压力很大并且collector想要降低在这次回收工作中Mark Assist的延迟。
还有两个事情要注意,回收器在它设定的目标内完成了。在Marking 完成之后in-use的堆内存空间是11MB而不是13MB,少了2MB。在Marking完成之后堆内存中标记为存活的空间同样是6MB。
另外,你可以获得更多GC的细节通过增加gcpacertrace=1的标记。这会让回收器打印concurrent pacer的内部状态。
L6
$ export GODEBUG=gctrace=1,gcpacertrace=1 ./app
Sample output:
gc 5 @0.071s 0%: 0.018+0.46+0.071 ms clock, 0.14+0/0.38/0.14+0.56 ms cpu, 29->29->29 MB, 30 MB goal, 8 P
pacer: sweep done at heap size 29MB; allocated 0MB of spans; swept 3752 pages at +6.183550e-004 pages/byte
pacer: assist ratio=+1.232155e+000 (scan 1 MB in 70->71 MB) workers=2+0
pacer: H_m_prev=30488736 h_t=+2.334071e-001 H_T=37605024 h_a=+1.409842e+000 H_a=73473040 h_g=+1.000000e+000 H_g=60977472 u_a=+2.500000e-001 u_g=+2.500000e-001 W_a=308200 goalΔ=+7.665929e-001 actualΔ=+1.176435e+000 u_a/u_g=+1.000000e+000
运行GC trace可以告诉你很多应用程序的健康状态以及回收器的速度。
Pacing
回收器有一个pacing算法,它会去确定什么时候回收去开始。算法依靠一个反馈循环,回收器会使用这种算法收集应用程序运行时候的信息,以及应用程序给堆造成的压力。压力可以定义为在给定的时间内应用程序在堆上的分配有多快。压力确定了回收器运行的速度。
在回收器开始回收之前,它会计算它认为完成回收所需的时间。 一旦回收运行,会造成正在运行的应用程序上的延迟,这将减慢应用程序的工作。 每次回收都会增加应用程序的整体延迟。
有一个错误观念就是认为降低回收器的速度是一种提高性能的方式。如果你可以推迟下一次的回收,你就会推迟它产生的延时。 但其实提升性能并不在于降低回收器的速度。
你可以决定改变GC Percentage的值,设置大于100。这会增加下次回收开始之前可以分配的内存大小。这会降低回收器的速度。但是不要考虑这么做。
图1.14

尝试直接影响回收速度并不能提升回收器性能。重要的事情是在于在每次回收的之间或者是回收的时候做更多事情,这个你可以通过减少work的堆内存的分配量来进行影响。
注意:也可以尽量使用最小的堆来实现所需要的吞吐量。记住,在云环境中,最小化堆内存的使用很重要。
图1.15

看一下两个版本的平均回收速度(2.08ms vs 1.96ms)。它们几乎差不太多,大概是2ms。不同的地方在于两个版本在每一次回收之间的work的量。应用程序每次回收之间,处理requests次数从3.98次变为 7.13次。可以看几乎相同的时间内有79.1%的工作量提升。可以看到,回收工作没有随着分配内存的减少而降速,而是保持了原来速度。成功点在于每次回收之间做了更多的事情。
调整回收器的回收速度,推迟延迟代价不是你提升应用程序的性能的方法,它只是减少了回收器需要运行的时间,这反过来会减少造成的延迟成本。回收器产生的延迟代价已经解释过了,但是这里再进行一个简单的总结说明。
Collector 延迟代价
每次回收工作,会带来两种类型的延迟。第一种是窃取CPU,在回收的时候这种窃取CPU的行为意味着你的应用程序没有以满CPU的状态运行。应用程序goroutines现在和回收器goroutine共享P,或者是进行Mark Assist。
图1.16
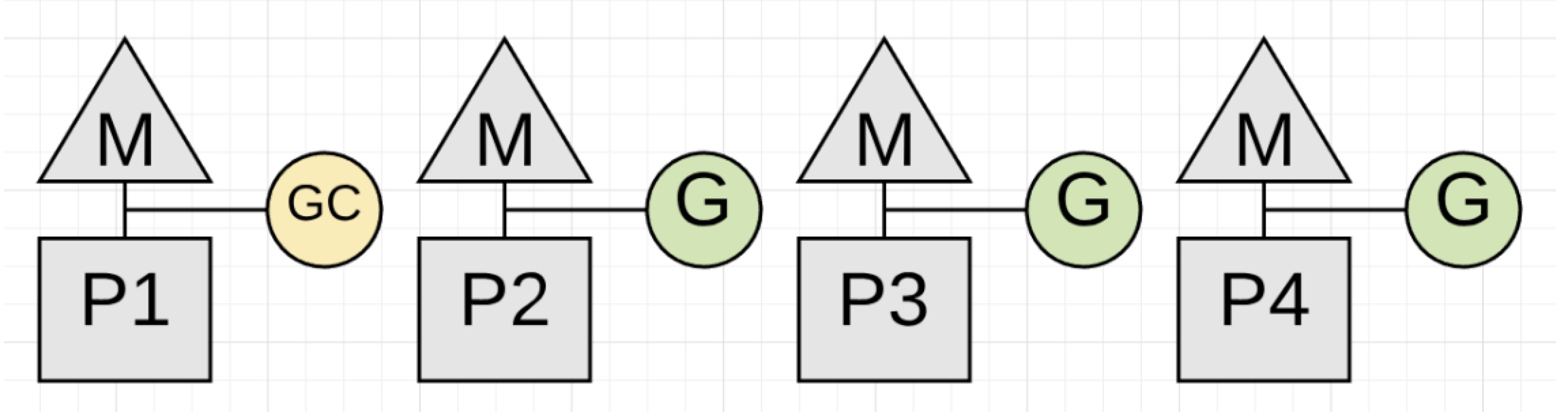
图1.17
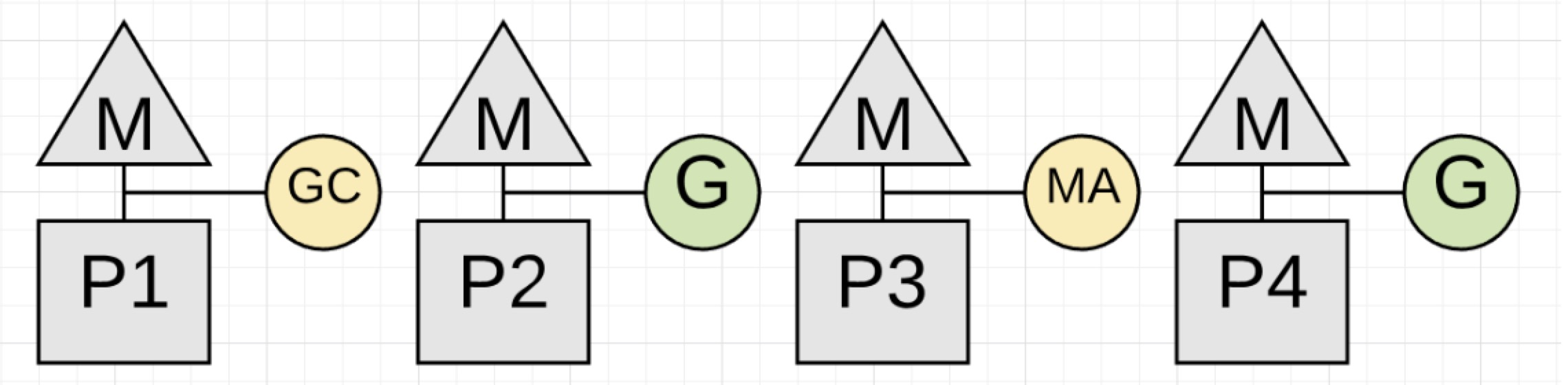
注意:Marking通常需要4 CPU-millsecondes/MB 的生存堆(举例,为了评估Marking阶段运行多少millseconds,这个值会设置为生存堆MB大小去除以0.25*CPU数目的值)。Marking实际运行大概是1MB/ms,但是只有1/4的CPU去处理。
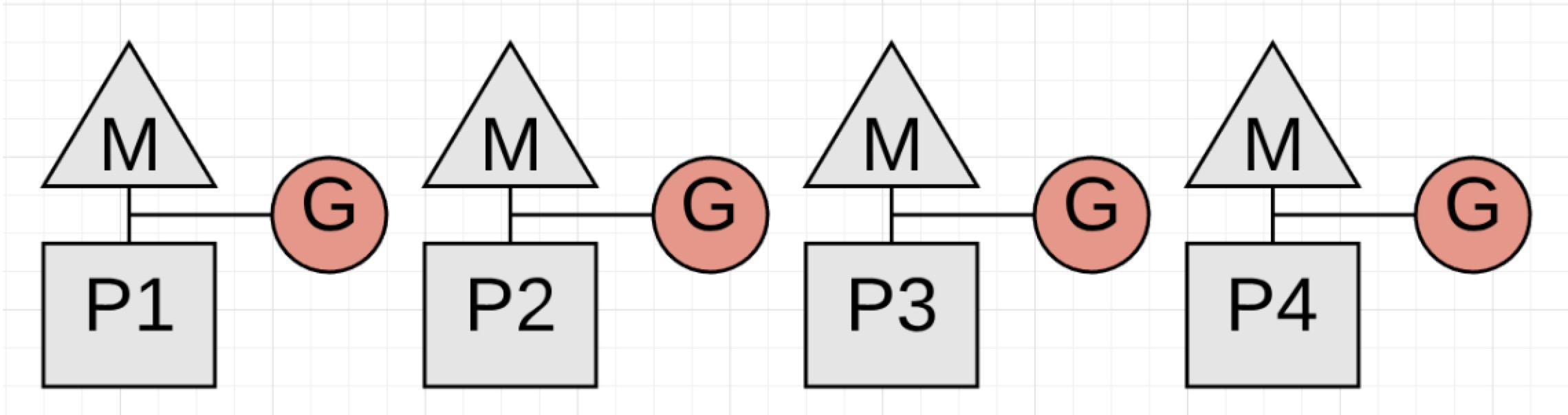
第二种类型的延迟就是在回收中产生的STW。STW就是没有任何goroutine进行工作的情况。整个应用程序本质上是停止状态。
图1.18
降低GC延迟
减少GC延迟的方式是识别哪些是应用程序中不必要的内存分配并移除它们,这会在几个方面帮助提高collector。
帮助回收器:
- 维持了最小堆
- 找到最优的一致速度
- 每次回收保持在目标(goal)之内
- 最小化回收的时间,STW和Mark Assist
这些事情都会帮助减少回收器产生的延迟,从而增加应用程序的吞吐量和性能。改变回收速度并没有什么用。你可以通过做出正确的工程方面决策,降低堆内存的分配压力来提升性能。
理解应用程序正在运行的workload
关于性能,还需要清楚你的workload的类型。理解你的workload意味着,确定你使用合理数量的goroutines来处理你的工作。CPU vs IO bound 的workloads是不同的,需要做出不同抉择。相关内容可以参考这里
结论
如果你花时间去专注于减少内存分配,你会得到性能上的提升。但是你不可能写出0分配的程序来,所以了解和确认productive(对程序有帮助的)的内存分配和not productive(损害性能)的分配是很重要的。之后你就可以信任垃圾回收器帮你维持好内存的健康和稳定,然后让你的程序持续的运行下去。
垃圾回收器是一个很好的折衷方式。花一点代价去进行垃圾回收,这样就不需要考虑内存管理的问题。Go 垃圾回收器能够让程序员更加高效和多产,可以让你写出足够快的程序。
