

通常在看一些面试题问到前端有哪些性能优化手段的时候,可能会提到一个叫做gzip压缩的方法。正好最近在学习node文件流操作和zlib模块的时候,对gzip压缩有了一个新的认识。今天就和大家一起分享一下,gzip是什么,从浏览器请求到收到服务端数据发生了什么。
由于之前的题目《你知道前端性能优化gzip的工作原理吗?》有些歧义,我本来想说的工作原理是这个过程中发生了什么,而很多点进来的大佬想看到的是压缩算法实现。所以将标题改为《前端性能优化gzip初探》,可能后续会对gzip压缩实现的一些粗浅的认识补上。小弟不甚惶恐,请大家见谅。
什么是gzip
兄弟你听说winRAR吗?听说过360压缩,快压,好压吗?都听说过,那你听过GNUzip吗?
对,没有错,gzip就是GNUzip的缩写,也是一个文件压缩程序,可以将文件压缩进后缀为.gz的压缩包。而我们前端所讲的gzip压缩优化,就是通过gzip这个压缩程序,对资源进行压缩,从而降低请求资源的文件大小。
gzip压缩优化在业界的应用有多么普遍呢,基本上你打开任何一个网站,看它们的html,js,css文件都是经过gzip压缩的(即使js,css这类文件经过了混淆压缩之后,gzip仍然可以明显的优化文件体积。)。
Tips:通常gzip对纯文本内容可压缩到原大小的40%。但png、gif、jpg、jpeg这类图片文件并不推荐使用gzip压缩(svg是个例外),首先经过压缩后的图片文件gzip能压缩的空间很小。事实上,添加标头,压缩字典,并校验响应体可能会让它更大。
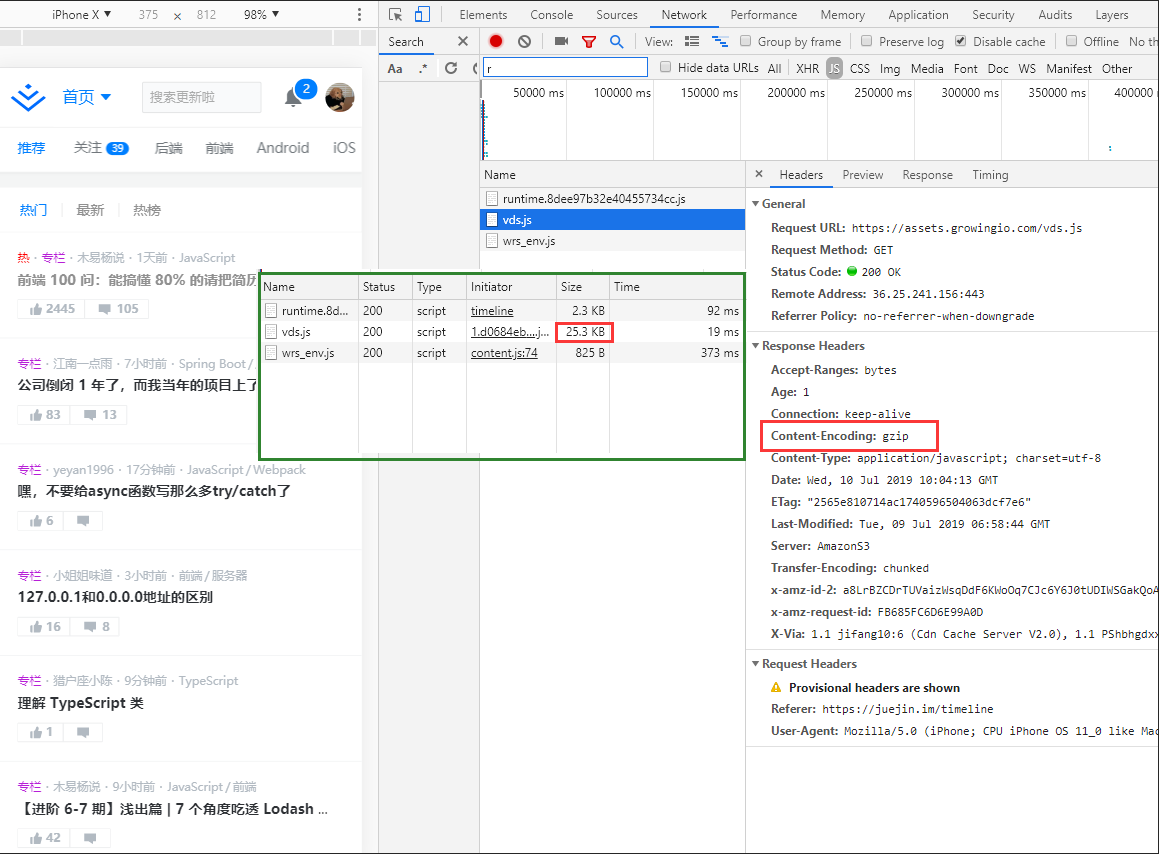
比如现在,你正在访问的掘金,打开调试工具,在网络请求Network中,选择一个js或css,都能在Response Headers中找到 content-encoding: gzip 键值对,这就表示了这个文件是启用了gzip压缩的。
gzip压缩过程
上面我们可以看到,这里是掘金网站引入的一个growingIO数据分析的文件,经过了gzip压缩,大小是25.3K。现在我们把这个文件下载下来,建一个没有开启gzip的本地服务器,看看未开启gzip压缩这个文件是多大(其实下载下来就已经能看到文件大小了,是88.73k)。
此处我们用原生node写一个服务,便于我们学习理解,目录和代码如下:
const http = require("http");
const fs = require("fs");
const server = http.createServer((req, res) => {
const rs = fs.createReadStream(`static${req.url}`); //读取文件流
rs.pipe(res); //将数据以流的形式返回
rs.on("error", err => {
//找不到返回404
console.log(err);
res.writeHead(404);
res.write("Not Found");
});
});
//监听8080
server.listen(8080, () => {
console.log("listen prot:8080");
});
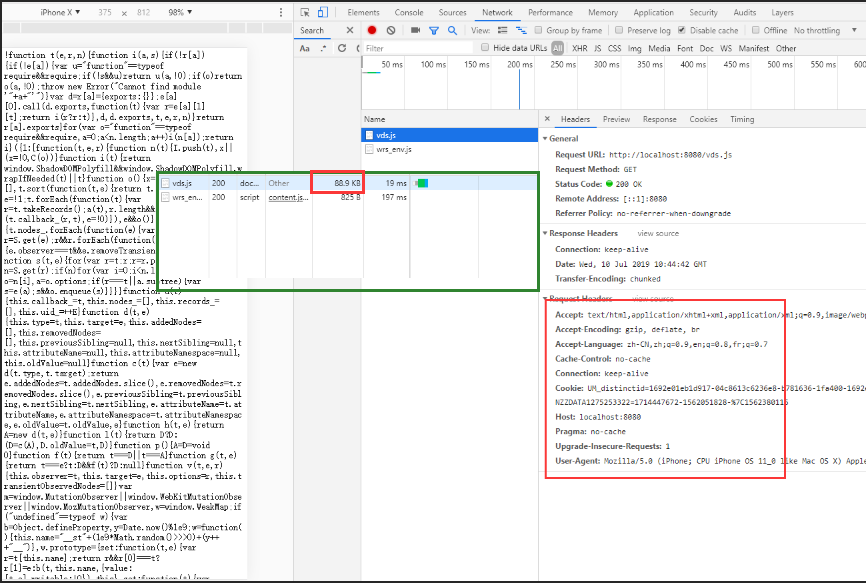
用node server.js启动服务,此时我们访问http://localhost:8080/vds.js,网页会显示vds.js文件的内容,查看Network面版,会发现vds.js请求大小是88.73k,和原始资源文件大小一致,Response Headers中也没有 content-encoding: gzip ,说明这是未经过gzip压缩的。
如何开启gzip呢,很简单,node为我们提供了zlib模块,直接使用就行,上面的代码简单修改一下就可以。
const http = require("http");
const fs = require("fs");
const zlib = require("zlib"); // <-- 引入zlib块
const server = http.createServer((req, res) => {
const rs = fs.createReadStream(`static${req.url}`);
const gz = zlib.createGzip(); // <-- 创建gzip压缩
rs.pipe(gz).pipe(res); // <-- 返回数据前经过gzip压缩
rs.on("error", err => {
console.log(err);
res.writeHead(404);
res.write("Not Found");
});
});
server.listen(8080, () => {
console.log("listen prot:8080");
});
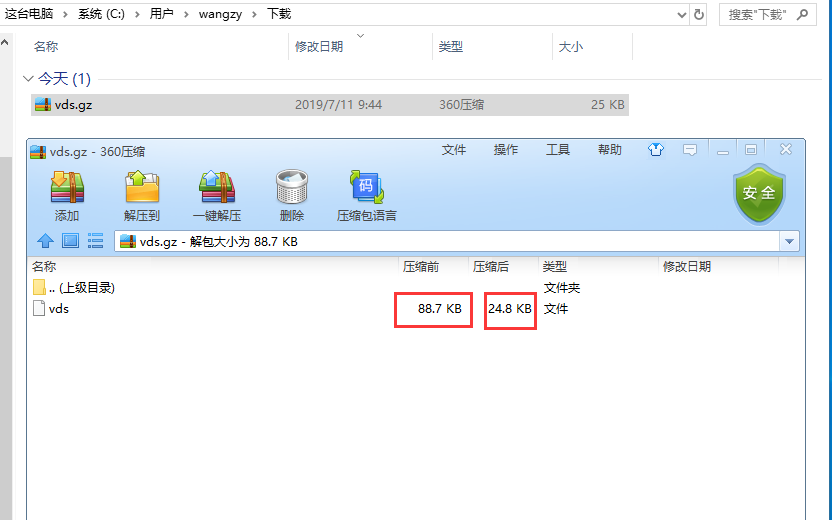
运行这段代码,访问http://localhost:8080/vds.js,会发现网页没有显示vds.js内容,而是直接下载了一个vds.js文件,大小是25k,大小好像是经过了压缩的。但是如果你尝试用编辑器打开这个文件,会发现打开失败或者提示这是一个二进制文件而不是文本。这个时候如果反应快的朋友可能会和我第一次的想法一样,试试把js后缀改成gz。因为前面说了,其实gzip就是一个压缩程序,将文件压缩进一个.gz压缩包。这个地方会不会其实是一个gz压缩包?
不卖关子了,将后缀名改为gz,解压成功后会出来一个88.73k的vds.js。
相信到了这里大家都应该豁然开朗,原来gzip就是将资源文件压缩进一个压缩包里啊,但是唯一的问题是这压缩包我怎么用,我请求一个文件,服务器你却给我一个压缩包,我识别不了啊。
解决这个问题更简单,服务端返回压缩包的时候告诉浏览器一声,这其实是一个gz压缩包,浏览器你使用前先解压一下。而这个通知就是我们之前判断是否开启gzip压缩的请求头字段,Response Headers里的 content-encoding: gzip。
我们最后修改一下代码,加一个请求头:
const http = require("http");
const fs = require("fs");
const zlib = require("zlib");
const server = http.createServer((req, res) => {
const rs = fs.createReadStream(`static${req.url}`);
const gz = zlib.createGzip();
res.setHeader("content-encoding", "gzip"); //添加content-encoding: gzip请求头。
rs.pipe(gz).pipe(res);
rs.on("error", err => {
console.log(err);
res.writeHead(404);
res.write("Not Found");
});
});
server.listen(8080, () => {
console.log("listen prot:8080");
此时浏览器再请求到gzip压缩后的文件,会先解压处理一下再使用,这对于我们用户来说是无感知的,工作浏览器都在背后默默做了,我们只是看到网络请求文件的大小,比服务器上实际资源的大小小了很多。
这一段花了很长的篇幅来讲gzip的工作原理,明白之后其实真的很简单,而且以后问到前端性能优化这一点,相信gzip这条应该是不会忘了的。
gzip的注意点
前面说的哪些文件适合开启gzip压缩,哪些不适合是一个注意点。
还有一个注意点是,谁来做这个gzip压缩,我们的例子是在接到请求时,由node服务器进行压缩处理。这和express中使用compression中间件,koa中使用koa-compress中间件,nginx和tomcat进行配置都是一样的,这也是比较普遍的一种做法,由服务端进行压缩处理。
服务器了解到我们这边有一个 gzip 压缩的需求,它会启动自己的 CPU 去为我们完成这个任务。而压缩文件这个过程本身是需要耗费时间的,大家可以理解为我们以服务器压缩的时间开销和 CPU 开销(以及浏览器解析压缩文件的开销)为代价,省下了一些传输过程中的时间开销。
如果我们在构建的时候,直接将资源文件打包成gz压缩包,其实也是可以的,这样可以省去服务器压缩的时间,减少一些服务端的消耗。
比如我们在使用webpack打包工具的时候可以使用compression-webpack-plugin插件,在构建项目的时候进行gzip打包,详细的配置使用可以去看插件的文档,非常简单。
补充内容:gzip文件分析
开头曾经提到过gzip是一个压缩程序而并不是一个算法,经过gzip压缩后文件格式为.gz,我们对.gz文件进行分析。
使用node的fs模块去读取一个gz压缩包可以看到如下一段Buffer内容:
const fs = require("fs");
fs.readFile("vds.gz", (err, data) => {
console.log(data); // <Buffer 1f 8b 08 00 00 00 00 00 00 0a ... >
});
通常gz压缩包有文件头,文件体和文件尾三个部分。头尾专门用来存储一些文件相关信息,比如我们看到上面的Buffer数据,第一二个字节为1f 8b(16进制),通常第一二字节为1f 8b就可以初步判断这是一个gz压缩包,但是具体还是要看是否完全符合gz文件格式,第三个字节取值范围是0到8,目前只用8,表示使用的是Deflate压缩算法。还有一些比如修改时间,压缩执行的文件系统等信息也会在文件头。
而文件尾会标识出一些原始数据大小的相关信息,被压缩的数据则是放在中间的文件体。
前面所说的,对于已经压缩过的图片,开启了gzip压缩反而可能会使其变得更大,就是因为中间实际压缩体没怎么减小,但是却添加了头尾的压缩相关信息。
补充内容:gzip的压缩算法
gzip中间的文件体,使用的是Deflate算法,这是一种无损压缩解压算法。Deflate是zip压缩文件的默认算法,7z,xz等其他的压缩文件中都有用到,实际上deflate只是一种压缩数据流的算法. 任何需要流式压缩的地方都可以用。
Deflate算法进行压缩时,一般先用Lz77算法压缩,再使用Huffman编码。
Lz77算法的原理是,如果文件中有两块内容相同的话,我们可以用两者之间的距离,相同内容的长度这样一对信息,来替换后一块内容。由于两者之间的距离,相同内容的长度这一对信息的大小,小于被替换内容的大小,所以文件得到了压缩。
举个例子:
http://www.baidu.comhttps://www.taobao.com
上面一段文本可以看到,前后有部分内容是相同的,我们可以用前文相同内容的距离和相同字符长度替换后文的内容。
http://www.baidu.com(21,12)taobao(23,4)
Deflate采用的Lz77算法是经过改进的版本,首先三个字节以上的重复串才进行偏码,否则不进行编码。其次匹配查找的时候用了哈希表,一个head数组记录最近匹配的位置和prev链表来记录哈希值冲突的之前的匹配位置。
而Huffman编码,因为理解的不是很清楚,这里就不便多说了,只大概了解是通过字符出现概率,将高频字符用较短字节进行表示从而达到字符串的压缩。
其实简单的看一下这些算法,我们大概能明白,为什么js,css这些文件即使经过了工具的混淆压缩,通过gzip依然能得到可观的压缩优化。
更多的gzip算法内容可以阅读下面的文章:
补充内容:brotli压缩
感谢wangyjx1的评论,特别去了解了一下brotli压缩,这里将了解到的一些内容分享出来。
Brotli由google在2015年推出,用于网络字体的离线压缩,后发布包含通用无损数据压缩的Brotli增强版本,Brotli基于LZ77算法的一个现代变体、Huffman编码和二阶上下文建模。
与常见的通用压缩算法不同,Brotli使用一个预定义的120千字节字典。该字典包含超过13000个常用单词、短语和其他子字符串,这些来自一个文本和HTML文档的大型语料库。预定义的算法可以提升较小文件的压缩密度。使用brotli取代deflate来对文本文件压缩通常可以增加20%的压缩密度,而压缩与解压缩速度则大致不变。
目前该压缩方式大部分浏览器(包括移动端)新版本支持良好,详细的支持情况可在caniuse查询到。
支持Brotli压缩算法的浏览器使用的内容编码类型为br,例如以下是Chrome浏览器请求头里Accept-Encoding的值:
Accept-Encoding: gzip, deflate, sdch, br
如果服务端支持Brotli算法,则会返回以下的响应头:
Content-Encoding: br
Tips:brotli 压缩只能在 https 中生效,因为 在 http 请求中 request header 里的 Accept-Encoding: gzip, deflate 是没有 br 的。
目前该压缩方案的使用情况,去查看了几大网站的网络请求,国外的google,facebook,bing都已用上了Brotli压缩。国内的话淘宝,百度,腾讯,京东,b站几个大站基本都没有使用,唯一我发现使用了brotli压缩你们猜是哪个网站?是知乎,果然有逼格,掘金可以考虑跟上了。好在腾讯云,阿里云,又拍云这类的cdn加速服务商都支持了brotli压缩。
node中没有原生模块支持brotli压缩,可以使用第三方库来支持,比如iltorb,感兴趣的朋友可以自己尝试一下(反正新了解的东西,我肯定是要亲自动手搞一下才行)。
最后
十分抱歉之前的标题和内容让大家产生误解,掘金的大佬们真的很严格。这文的写作缘由只是因为学习node中理解了gzip的工作过程,想分享给大家。没敢讲压缩算法这块,是因为这地方本身还要学习,而且对于前端来说不是必须掌握的知识点,面试应该不会问这么深,当然感兴趣的可以自己了解。但是既然大家希望能提到这些,我就献丑简单分享一下我知道的东西,有不足之处欢迎大家批评指正。
