

介绍
大多数开发者都或多或少地在SQL数据库当中处理过层级结构数据,并且意识到管理层级数据并不是一个关系型数据库所擅长的。一个关系型数据库中的表不是层级结构的(比如XML),而是一个简单的平铺列表。层级数据拥有一个父-子关系,然而一张关系型数据库表不能自然地表示它。
在我们的这篇主题介绍当中,层级数据是一个这样的集合,每项有一个单一的父亲以及0个或者更多的孩子(根节点是例外。它没有父亲)。层级数据在许多的数据库应用中被广泛使用。包括论坛和邮件列表,商业组织图,内容管理分类和产品分类。我们将使用下面的来自一个虚拟电子商店的产品分类层级结构来介绍我们的主题。
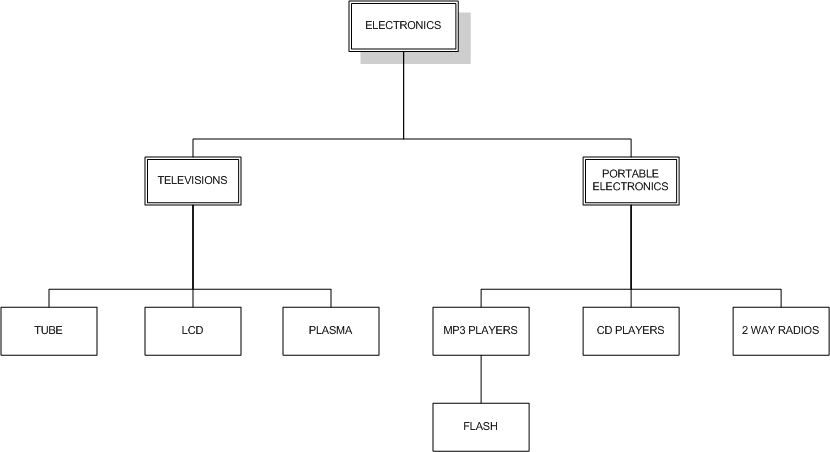
这些分类构成了一个与之前所提及的例子相当类似的层级结构。在本篇文章当中,我们将检查两种在MySQL中用于处理层级数据的模型。首先我们从传统的邻接表模型开始。
邻接列表模型(The Adjacency List Model)
通常上面例子中的分类将会被存储在如下的一张表当中(我会把完整的创建和插入语句包含进去,以便你可以跟着操作)
CREATE TABLE category(
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
parent INT DEFAULT NULL
);
INSERT INTO category VALUES(1,'ELECTRONICS',NULL),(2,'TELEVISIONS',1),(3,'TUBE',2),
(4,'LCD',2),(5,'PLASMA',2),(6,'PORTABLE ELECTRONICS',1),(7,'MP3 PLAYERS',6),(8,'FLASH',7),
(9,'CD PLAYERS',6),(10,'2 WAY RADIOS',6);
SELECT * FROM category ORDER BY category_id;
+-------------+----------------------+--------+
| category_id | name | parent |
+-------------+----------------------+--------+
| 1 | ELECTRONICS | NULL |
| 2 | TELEVISIONS | 1 |
| 3 | TUBE | 2 |
| 4 | LCD | 2 |
| 5 | PLASMA | 2 |
| 6 | PORTABLE ELECTRONICS | 1 |
| 7 | MP3 PLAYERS | 6 |
| 8 | FLASH | 7 |
| 9 | CD PLAYERS | 6 |
| 10 | 2 WAY RADIOS | 6 |
+-------------+----------------------+--------+
10 rows in set (0.00 sec)
在邻接列表模型中,表中的每一项都包含一个指向它父节点的指针。在这个例子当中最顶层的元素electronics父节点的值是NULL。邻接列表模型拥有简单易理解的优点,你可以很容易地看出FLASH是MP3 PLAYERS的孩子,然后MP3 PLAYERS又是PORTABLE ELECTRONICS的孩子,PORTABLE ELECTRONICS又是ELECTRONICS的孩子。尽管邻接列表模型在客户端代码当中可以相当容易地被处理,但是使用纯SQL则会产生许多难题。
获取一棵完整的树
当处理层级数据时,首个常用的任务就是展示一整棵通常带有缩进形式的树。在纯SQl中做这个最常见的方法就是使用自联接(self-join)
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4
FROM category AS t1
LEFT JOIN category AS t2 ON t2.parent = t1.category_id
LEFT JOIN category AS t3 ON t3.parent = t2.category_id
LEFT JOIN category AS t4 ON t4.parent = t3.category_id
WHERE t1.name = 'ELECTRONICS';
+-------------+----------------------+--------------+-------+
| lev1 | lev2 | lev3 | lev4 |
+-------------+----------------------+--------------+-------+
| ELECTRONICS | TELEVISIONS | TUBE | NULL |
| ELECTRONICS | TELEVISIONS | LCD | NULL |
| ELECTRONICS | TELEVISIONS | PLASMA | NULL |
| ELECTRONICS | PORTABLE ELECTRONICS | MP3 PLAYERS | FLASH |
| ELECTRONICS | PORTABLE ELECTRONICS | CD PLAYERS | NULL |
| ELECTRONICS | PORTABLE ELECTRONICS | 2 WAY RADIOS | NULL |
+-------------+----------------------+--------------+-------+
6 rows in set (0.00 sec)
查找所有的叶子节点
我们可以通过左连接(LEFT JOIN)查询找到所有的叶子节点(没有任何孩子的节点)
SELECT t1.name FROM
category AS t1 LEFT JOIN category as t2
ON t1.category_id = t2.parent
WHERE t2.category_id IS NULL;
+--------------+
| name |
+--------------+
| TUBE |
| LCD |
| PLASMA |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+--------------+
获取一条路径
自联接同样也可以让我们看到层级结构中的完整路径:
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4
FROM category AS t1
LEFT JOIN category AS t2 ON t2.parent = t1.category_id
LEFT JOIN category AS t3 ON t3.parent = t2.category_id
LEFT JOIN category AS t4 ON t4.parent = t3.category_id
WHERE t1.name = 'ELECTRONICS' AND t4.name = 'FLASH';
+-------------+----------------------+-------------+-------+
| lev1 | lev2 | lev3 | lev4 |
+-------------+----------------------+-------------+-------+
| ELECTRONICS | PORTABLE ELECTRONICS | MP3 PLAYERS | FLASH |
+-------------+----------------------+-------------+-------+
1 row in set (0.01 sec)
这样一种方法主要的缺陷在于你需要对层级结构中的每一级做自联接,这样将会导致当层级增多,自联接变得复杂时,查询性能会自然地降低。
邻接列表模型的缺陷
在纯SQL中使用邻接列表模型可能是比较困难的。在查看一个分类的完整路径之前,我们需要知道它在哪一层级。除此之外,我们需要注意删除节点。因为有可能在处理过程当中一整课子树会成为孤儿(删除portable electronics分类,它的孩子将会成为孤儿)。这其中的一些缺陷可以通过使用客户端代码或者存储过程解决。通过使用程序语言,我们可以从一棵树的底部向上遍历来返回完整的树或者一条单一路径。我们也可以通过提升一个孩子元素,然后重新安置剩下的孩子指向新的父亲,来删除节点而不会导致孤儿的产生。
嵌套集模型(The Nested Set Model)
我在这篇文章想着重介绍的是一种另外的方法,通常它被称之为嵌套集模型(The Nested Set Model)。在嵌套集模型当中,我们以一种新的视角来看待我们的层级结构。不是以节点和线的方式,而是以嵌套容器的方式。试着用这种方法描述电子产品分类:
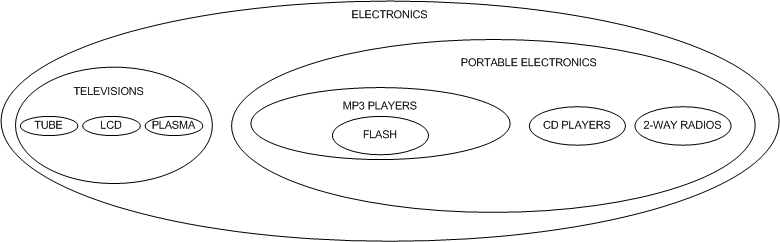
请注意我们的层级结构是如何被继续维持住的,因为父分类包含了他们的孩子。我们通过使用left和right值来表示节点的嵌套,以此在一张表里面表示这种形式的层级结构:
CREATE TABLE nested_category (
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
lft INT NOT NULL,
rgt INT NOT NULL
);
INSERT INTO nested_category VALUES(1,'ELECTRONICS',1,20),(2,'TELEVISIONS',2,9),(3,'TUBE',3,4),
(4,'LCD',5,6),(5,'PLASMA',7,8),(6,'PORTABLE ELECTRONICS',10,19),(7,'MP3 PLAYERS',11,14),(8,'FLASH',12,13),
(9,'CD PLAYERS',15,16),(10,'2 WAY RADIOS',17,18);
SELECT * FROM nested_category ORDER BY category_id;
+-------------+----------------------+-----+-----+
| category_id | name | lft | rgt |
+-------------+----------------------+-----+-----+
| 1 | ELECTRONICS | 1 | 20 |
| 2 | TELEVISIONS | 2 | 9 |
| 3 | TUBE | 3 | 4 |
| 4 | LCD | 5 | 6 |
| 5 | PLASMA | 7 | 8 |
| 6 | PORTABLE ELECTRONICS | 10 | 19 |
| 7 | MP3 PLAYERS | 11 | 14 |
| 8 | FLASH | 12 | 13 |
| 9 | CD PLAYERS | 15 | 16 |
| 10 | 2 WAY RADIOS | 17 | 18 |
+-------------+----------------------+-----+-----+
由于left和right是MySQL里面的保留字,因此我们使用lft和rgt。请在dev.mysql.com/doc/mysql/e…查看完整的保留字列表。
那么我们如何决定left和right的值呢?我们从外部节点最左侧开始,然后一直向右编号。
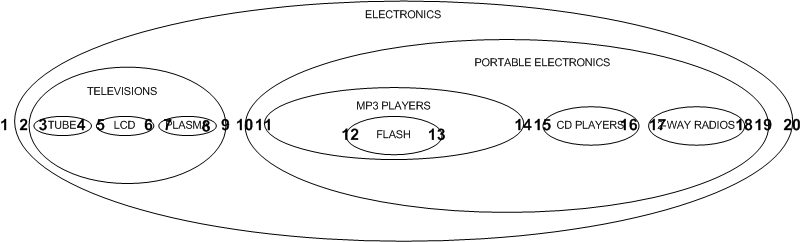
这种设计也可以应用到一棵典型的树:
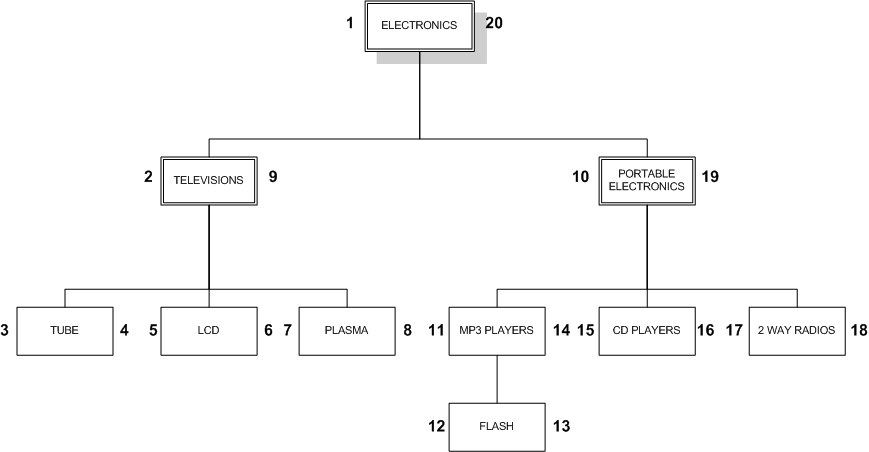
当我们处理一棵树时,我们从左往右,一层一层地进行。在给节点分配一个右手边数字和向右移动之前,我们先下降到它的孩子节点。这种方法被称之为先序遍历算法。
获取一棵完整的树
我们可以通过使用将父节点与子节点链接起来的自联接来检索完整的树。它的原理基于一个节点的lft值一定在它父亲lft和rgt值之间。
SELECT node.name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND parent.name = 'ELECTRONICS'
ORDER BY node.lft;
+----------------------+
| name |
+----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+----------------------+
不同于之前邻接列表模型的例子,这个查询将不需要关心树的层级。我们同样不需要在BETWEEN子句注意节点的rgt值,因为它和lft值一样也一定会落在同一个父亲内。
查找所有的叶子节点
相比在邻接列表模型当中使用左联结方法,在嵌套集模型当中查找所有的叶子节点是更加简单的。如果你仔细观察nested_category表,你可能会注意到叶子节点的lft和rgt值是连续的数字。所以为了找出叶子节点,我们查找那些rgt = lft + 1的节点。
SELECT name
FROM nested_category
WHERE rgt = lft + 1;
+--------------+
| name |
+--------------+
| TUBE |
| LCD |
| PLASMA |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+--------------+
获取一条路径
通过使用嵌套集模型,我们可以在不使用多条自联结的情况下获取一条路径:
SELECT parent.name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = 'FLASH'
ORDER BY parent.lft;
+----------------------+
| name |
+----------------------+
| ELECTRONICS |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
+----------------------+
查找节点的深度
我们已经知道了如何展示一整课树,但是如果我们想获取树中每个节点的深度以更好地确定节点的层级结构,我们该怎么做呢?这可以通过给已经存在的展示整棵树的查询语句添加COUNT函数和一个GROUP BY子句来完成。
SELECT node.name, (COUNT(parent.name) - 1) AS depth
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+----------------------+-------+
| name | depth |
+----------------------+-------+
| ELECTRONICS | 0 |
| TELEVISIONS | 1 |
| TUBE | 2 |
| LCD | 2 |
| PLASMA | 2 |
| PORTABLE ELECTRONICS | 1 |
| MP3 PLAYERS | 2 |
| FLASH | 3 |
| CD PLAYERS | 2 |
| 2 WAY RADIOS | 2 |
+----------------------+-------+
我们也可以使用深度值配合CONCAT和REPEAT字符串函数来缩进分类名称:
SELECT CONCAT( REPEAT(' ', COUNT(parent.name) - 1), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+-----------------------+
| name |
+-----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+-----------------------+
当然了,在客户端应用当中,你可能会更倾向于使用深度值来直接展示层级结构。Web开发者可以循环整棵树,然后随着深度值的增加和减少添加相应的<li></li>和<ul></ul>标签。
一棵子树的深度
当我们需要子树的深度信息时,我们不能限制自连接中的节点或父表,因为它会破坏我们的结果。相反,我们添加第三个自连接以及一个子查询来确定将成为子树的新起点的深度:
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) AS depth
FROM nested_category AS node,
nested_category AS parent,
nested_category AS sub_parent,
(
SELECT node.name, (COUNT(parent.name) - 1) AS depth
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = 'PORTABLE ELECTRONICS'
GROUP BY node.name
ORDER BY node.lft
)AS sub_tree
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt
AND sub_parent.name = sub_tree.name
GROUP BY node.name
ORDER BY node.lft;
+----------------------+-------+
| name | depth |
+----------------------+-------+
| PORTABLE ELECTRONICS | 0 |
| MP3 PLAYERS | 1 |
| FLASH | 2 |
| CD PLAYERS | 1 |
| 2 WAY RADIOS | 1 |
+----------------------+-------+
任何节点包括根节点都可以通过名称使用这个功能。深度值将总是与命名的节点有关。
查找一个节点的直接子节点
请想象一下你正在一个零售商网站展示一个电子产品的分类。当一个用户点击一个分类时,你希望展示那个分类的产品以及它的直接子分类,而不是它下面的整棵分类树。为此,我们需要显示节点及其直接子节点,而不要再向下深入。举个例子,当展示PORTABLE ELECTRONICS分类,我们想要展示MP3 PLAYERS, CD PLAYERS, 和2 WAY RADIOS, 但不要FLASH。
这可以通过给之前的查询添加HAVING子句轻松地完成。
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) AS depth
FROM nested_category AS node,
nested_category AS parent,
nested_category AS sub_parent,
(
SELECT node.name, (COUNT(parent.name) - 1) AS depth
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = 'PORTABLE ELECTRONICS'
GROUP BY node.name
ORDER BY node.lft
)AS sub_tree
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt
AND sub_parent.name = sub_tree.name
GROUP BY node.name
HAVING depth <= 1
ORDER BY node.lft;
+----------------------+-------+
| name | depth |
+----------------------+-------+
| PORTABLE ELECTRONICS | 0 |
| MP3 PLAYERS | 1 |
| CD PLAYERS | 1 |
| 2 WAY RADIOS | 1 |
+----------------------+-------+
如果你不希望展示父节点,那就将HAVING depth <= 1改成HAVING depth = 1。
嵌套集中的聚合函数
让我们添加一个产品以用来演示聚合函数:
CREATE TABLE product
(
product_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(40),
category_id INT NOT NULL
);
INSERT INTO product(name, category_id) VALUES('20" TV',3),('36" TV',3),
('Super-LCD 42"',4),('Ultra-Plasma 62"',5),('Value Plasma 38"',5),
('Power-MP3 5gb',7),('Super-Player 1gb',8),('Porta CD',9),('CD To go!',9),
('Family Talk 360',10);
SELECT * FROM product;
+------------+-------------------+-------------+
| product_id | name | category_id |
+------------+-------------------+-------------+
| 1 | 20" TV | 3 |
| 2 | 36" TV | 3 |
| 3 | Super-LCD 42" | 4 |
| 4 | Ultra-Plasma 62" | 5 |
| 5 | Value Plasma 38" | 5 |
| 6 | Power-MP3 128mb | 7 |
| 7 | Super-Shuffle 1gb | 8 |
| 8 | Porta CD | 9 |
| 9 | CD To go! | 9 |
| 10 | Family Talk 360 | 10 |
+------------+-------------------+-------------+
现在我们来写一条可以获取分类树以及对应的产品数量的查询语句:
SELECT parent.name, COUNT(product.name)
FROM nested_category AS node ,
nested_category AS parent,
product
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.category_id = product.category_id
GROUP BY parent.name
ORDER BY node.lft;
+----------------------+---------------------+
| name | COUNT(product.name) |
+----------------------+---------------------+
| ELECTRONICS | 10 |
| TELEVISIONS | 5 |
| TUBE | 2 |
| LCD | 1 |
| PLASMA | 2 |
| PORTABLE ELECTRONICS | 5 |
| MP3 PLAYERS | 2 |
| FLASH | 1 |
| CD PLAYERS | 2 |
| 2 WAY RADIOS | 1 |
+----------------------+---------------------+
这是我们添加COUNT和GROUP BY的典型整树查询,以及对产品表的引用以及WHERE子句中节点和产品表之间的联结。 正如你所看到的那样,每一个分类都有对应的数量,同时子分类的数量被反映到了父分类当中。
添加新节点
既然我们已经学习了如何查询树,我们现在应该看看如何通过添加一个新节点来更新树。让我们再来看看嵌套集图:
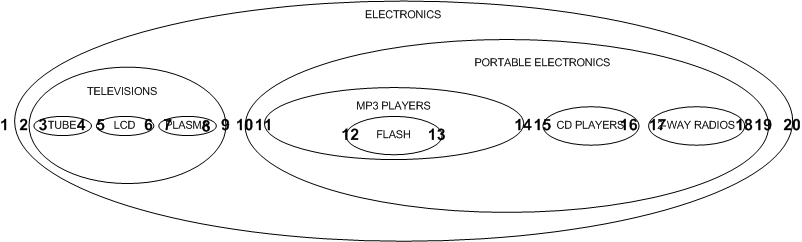
如果我们想要在TELEVISIONS和PORTABLE ELECTRONICS节点之间添加新节点,它的lft和rgt值应该分别是10和11,并且它的所有右边的节点的lft和rgt值都需要增加2。然后,我们将使用适当的lft和rgt值添加新节点。尽管在MYSQL 5中可以使用存储过程完成这些,但我还是假设大多数的读者正在使用4.1版本,因为它是最新稳定版。于是我将使用LOCK TABLES声明来隔离查询语句:
LOCK TABLE nested_category WRITE;
SELECT @myRight := rgt FROM nested_category
WHERE name = 'TELEVISIONS';
UPDATE nested_category SET rgt = rgt + 2 WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft + 2 WHERE lft > @myRight;
INSERT INTO nested_category(name, lft, rgt) VALUES('GAME CONSOLES', @myRight + 1, @myRight + 2);
UNLOCK TABLES;
我们可以使用我们的缩进的树查询来检查嵌套结果:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+-----------------------+
| name |
+-----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| GAME CONSOLES |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+-----------------------+
如果仅仅想给一个节点添加一个没有任何孩子的节点,我们需要稍微修改存储过程。让我们给2 WAY RADIOS节点添加一个新的FRS节点:
LOCK TABLE nested_category WRITE;
SELECT @myLeft := lft FROM nested_category
WHERE name = '2 WAY RADIOS';
UPDATE nested_category SET rgt = rgt + 2 WHERE rgt > @myLeft;
UPDATE nested_category SET lft = lft + 2 WHERE lft > @myLeft;
INSERT INTO nested_category(name, lft, rgt) VALUES('FRS', @myLeft + 1, @myLeft + 2);
UNLOCK TABLES;
在这一例中,我们扩展了新的父节点右边的节点数值,然后把节点。正如你所见,我们的新节点现在被嵌套住了:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+-----------------------+
| name |
+-----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| GAME CONSOLES |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
| FRS |
+-----------------------+
删除节点
嵌套集模型当中最后一项基础任务是节点移除。删除节点时采取的操作过程取决于节点在层次结构中的位置;删除叶子节点比删除有孩子的节点更容易,因为我们需要处理孤儿节点。
当删除一个叶子节点时,处理过程其实刚好和增加一个节点相反。我们删除这个节点以及减少它右边节点的宽度:
LOCK TABLE nested_category WRITE;
SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1
FROM nested_category
WHERE name = 'GAME CONSOLES';
DELETE FROM nested_category WHERE lft BETWEEN @myLeft AND @myRight;
UPDATE nested_category SET rgt = rgt - @myWidth WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft - @myWidth WHERE lft > @myRight;
UNLOCK TABLES;
我们执行缩进的树查询语句来确认节点被删除了且没有破坏层级结构。
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+-----------------------+
| name |
+-----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
| FRS |
+-----------------------+
下面的方法适用于删除一个节点和它的所有孩子:
LOCK TABLE nested_category WRITE;
SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1
FROM nested_category
WHERE name = 'MP3 PLAYERS';
DELETE FROM nested_category WHERE lft BETWEEN @myLeft AND @myRight;
UPDATE nested_category SET rgt = rgt - @myWidth WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft - @myWidth WHERE lft > @myRight;
UNLOCK TABLES;
再一次,我们查询是否已成功删除整个子树:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+-----------------------+
| name |
+-----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| PORTABLE ELECTRONICS |
| CD PLAYERS |
| 2 WAY RADIOS |
| FRS |
+-----------------------+
在其它场景当中,我们必须只删除父节点而不包括孩子。在某些情况下,孩子节点应该被提升到被删除的父节点的同一层级:
LOCK TABLE nested_category WRITE;
SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1
FROM nested_category
WHERE name = 'PORTABLE ELECTRONICS';
DELETE FROM nested_category WHERE lft = @myLeft;
UPDATE nested_category SET rgt = rgt - 1, lft = lft - 1 WHERE lft BETWEEN @myLeft AND @myRight;
UPDATE nested_category SET rgt = rgt - 2 WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft - 2 WHERE lft > @myRight;
UNLOCK TABLES;
在这个例子中,我们将该节点右边的所有元素减2(因为如果没有孩子,它的宽度将时2)以及对它所有的孩子减1(为了填补父亲lft值减少所造成的差距)。现在让我们再一次确认元素已经被提升了:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+---------------+
| name |
+---------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| CD PLAYERS |
| 2 WAY RADIOS |
| FRS |
+---------------+
删除节点时的其他场景包括将一个子节点提升到其父节点并在父节点的兄弟节点下移动子节点,但限于文章篇幅,本文将不会介绍这些方案。
最后一些想法
尽管我希望这篇文章中提供的信息可以对你有所帮助,但是SQL嵌套集的概念已经出现超过10年了,所以网上有许多书中包含许多额外可用的信息。个人认为管理层级结构最全面详尽的介绍是一本叫做Joe Celko’s Trees and Hierarchies in SQL for Smarties的书。它是由一位在高级SQL领域非常值得尊敬的作者Joe Celko编写。嵌套集模型经常被归功于Joe Celko,并且他是至今为止在这个主题上产量最高的作者。我发现Celko的书是在我的研究当中无价的资源,因此我强烈推荐它。这本书涵盖了许多我在本篇文章我没有涉及的高级主题,同时它提供了许多包括邻接列表模型和嵌套集模型的管理层级结构的方法。
在接下来的引用/资源部分,我列出一些可能对你研究管理层级结构数据有用的网络资源,它包括一对PHP相关的资源以及在MySQL中处理嵌套集的PHP预构建库。那些目前使用邻接列表模型并想要试验嵌套集模型的人可以在下面列出的资源中的Storing Hierarchical Data in a Database 找到用于在两者之间进行转换的示例代码。
引用 / 资源
- Joe Celko’s Trees and Hierarchies in SQL for Smarties – ISBN 1-55860-920-2
- Storing Hierarchical Data in a Database
- A Look at SQL Trees
- SQL Lessons
- Nontraditional Databases
- Trees in SQL
- Trees in SQL (2)
- Converting an adjacency list model to a nested set model Nested Sets in PHP Demonstration (German) A Nested Set Library in PHP
