


简介
第一次接触正则表达式是在2016年,那会对这种火星文很是抵触,只是草草的记住了一些常用规则,大部分时候大家遇到需要使用的正则表达式,都会上网进行查询,基本上都能找到自己满意的答案,我曾经过无数次产生要学好正则表达式的念头,但每次都是无从下手,这次沉下心在经过两周的整理,决定分享一下我所理解的正则表达式。本文只是入门,想要学好正则表达式,必须得反复练习,才能更深入的学好。
声明: 由于正则表达式在各个语言中的规则不太一致,本文会偏向于JavaScript
入门
为什么要学习和使用正则表达式
我们都知道几乎所有的语言,包括ant等构建脚本,都内置了正则表达式引擎,学好正则表达式真的是一劳永逸。
而至于使用表达式的场景,我想大家应该都遇到过批量处理字符串,尤其是前端在批量处理HTML标签时候,都必须借助强大的正则表达式,如果你的目标特别具象,比如你很清楚自己所要匹配的字符串位置或者内容,那么你或许不需要借助正则表达式,否则正则表达式就是你的利器,前端主流框架Vue、React中的词法分析都借助到了正则表达式,再往前seajs等无一不是利用正则去处理路径等问题,正则表达式其实离我们很近。
元字符
开始行(^)和结束行($)
开始行和结束行应该是元字符中最常见的两个,用来匹配以特定字符开头或者结束,在检查一个字符串的时候,^对应的是字符串开头,$美元符对应的是字符串结束。
单词边界分隔符(\b)和非单词边界分隔符(\B)
单词边界分隔符常用在我们需要匹配某些指定单词,而非包含单词,例如
'attention tent had better'.match(/tent/)
/*["tent", index: 2, input: "attention tent had better", groups: undefined]*/上述例子匹配到的就是第一个attention中的字符,这时候可以借助单词分界符
'attention tent had better'.match(/\btent\b/)
/*["tent", index: 10, input: "attention tent had better", groups: undefined]*/任意字符(.)
任意字符是指除换行符(如\n)和 unicode终止符之外所以字符,在ES6中我们可以使用 s 修饰符来开始doAll模式,可以匹配任意字符
多选结构(|)
多选结构,类似于我们在写代码时候的if else分支,匹配任意一个分支的子表达式,例如
'dog cat'.match(/(dog)|(cat)/)字符组([])
字符组用来匹配一部分集合,类似于上面的多选分支,只要在字符组内任意的一个元素匹配都代表着这个表达式匹配成功,但是还是与多选结构有几点不同
1、正则引擎中会对字符组进行查询优化,而不是使用回溯,所以性能高于多选结构
2、字符组内部的部分元字符(. ? &)代表着普通意义上的字符,不是元字符概念
排除型字符组([^])
与上面的字符组正好相反,意味着不在这个组内的即为匹配成功
空格符(\s)和非空格符(\S)
\s代表着任意Unicode空白字符
\S正好与之相反
单词符(\w)和非单词符(\W)
\w代表着任意Ascii码的组成的单词,和[a-zA-Z0-9]等价
\W正好与之相反,等价于[^a-zA-Z0-9]
分组捕获(())和忽略分组捕获((:))
分组可以实现最小单元的子表达式,并对分组内的内容进行引用,例如
'javascript is very good'.replace(/\b(good)\b/, '$1 and regexp')环视((?=)、(?!)、(?<=)、(?!<=))
(?=)正向环视
(?!)正向否定环视
(?<=)逆向环视
(?!<=)逆向否定环视
在javascript中,我们更喜欢称之为零宽断言,这部分内容我会放到后面讲解,这里先给大家普及一下概念,有些语言未实现部分功能,比如javascript中的逆向环视只有chrome支持
固化分组(?>)
这里先给大家普及一下概念,有些语言未实现,比如javascript
量词
优先量词(+、*、{n,}、{n,m})
这几个量词,我们更喜欢称之为贪婪匹配量词,他们会在允许的范内,尽可能多的进行匹配。
忽略优先量词(?)
单纯的?号并不足以构成忽略优先,它需要和上面的优先量词进行组合使用。单一的?代表着匹配0次或者1次。
流派和特性
起源
本节内容引自(美)佛瑞德关于正则起源内容
正则表达式的引擎基本分为两大类,一种是DFA(确定的有穷自动机),一种是NFA(不确定的有穷自动机),DFA和NFA反映了正则表达式在应用算法上的差异,我们把NFA成为表达式主导(稍后会讲解区别),DFA(文本主导)
特性
DFA(文本主导)
DFA在扫描文本字符串的时候会记录当前有效匹配的所有可能,我们看下面的例子
let reg = /to(nite|day|night)/
let str = `after tonight`表达式引擎在移动字符串到o的位置后,会继续向前移动获取n这个字符,去和正则表达式引擎对比,这时候会把day分组去除,继续下移到g字符,会把nite去除,最后只剩下nighht分支,表达式匹配成功,具体看下图
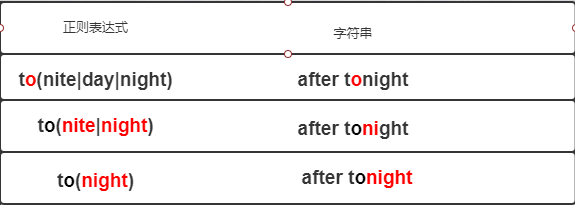
我称这种方式为文本主导,在扫描的过程中,文本主动去修改了表达式引擎的匹配规则,主动去除不符合规则的分支判断,这个在正则引擎匹配中性能还是相当高的,通过上述,我们可以看到,在DFA中不存在回溯
NFA(表达式主导)
let reg = /to(nite|day|night)/
let str = `after tonight`我们还是从上述例子来了解,NFA的工作机制,正则表达式从t处开始匹配真个字符串的每一个字符,如果满足匹配条件,引擎则移动到正则表达式下一位和字符串的下一位进行匹配,继续表达式匹配。
从o开始,NFA将面临三个分支,nite、day、night,引擎会依次从n、i、t、e查看是否匹配,分支失败,则会回溯到之前存储的最近的备用状态,关于回溯,后面会着重讲解,然后从其他分支,继续匹配,看下图
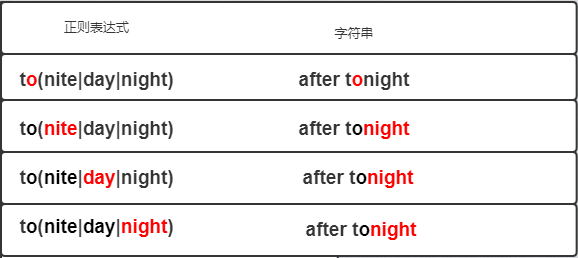
表达式的控制权在不同元素之间来回切换,我们称之为表达式主导
区别
1、DFA没有回溯,性能更高
2、NFA是表达式主导,开发人员能很明确自己想要达到的目标,能更灵活的控制表达式
3、两种引擎都会进行预编译阶段,DFA在预编译阶段更耗费时间,也更加耗费内存,NFA更快,因为更多是在运行时做判断
4、NFA提供一些DFA不支持的功能,例如分组捕获、环视、占有优先量词、固话分组等
下集预告
工作原理
1、回溯
2、NFA引擎匹配原理
3、如何优雅的使用环视
4、如何使用环视模拟固化分组
性能优化
1、如何规避循环匹配
2、如何更快匹配失败
3、如何正确使用正则表达式

