

- 原文地址:Using What-If Tool to investigate Machine Learning models.
- 原文作者:Parul Pandey
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:Starrier
- 校对者:lsvih,TrWestdoor
使用 What-If 工具来研究机器学习模型
Google 开源了一个在无需编码的情况下,即可轻松分析 ML 模型的工具。
 from [Pexels](https://www.pexels.com/photo/ask-blackboard-chalk-board-chalkboard-356079/?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels)](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/6/27/16b97077c7d4f358~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
好的试验可以帮助我们更好地理解它们的模型¹
在这个可解释机器学习的时代,人们不能仅仅满足于简单地训练模型并从中获得预测。为了能够真正产生影响和取得良好的效果,我们还应该能够探索和研究我们的模型。除此之外,在进行该模型之前,还应该清楚地记住算法的公平性约束和偏差。
研究一个模型需要探索很多问题,当事者需要有侦探般的智慧去探索和寻找模型中的问题和不一致性。而且,这样的任务通常都很复杂,需要编写大量的自定义代码。幸运的是,What-If Tool 为我们解决了这个问题,它使用户更容易、更准确地检查、评估和调试机器学习系统。
What-If 工具(WIT)
](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/6/27/16b9707780881df4~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
What-If 工具 是一种用于研究机器学习模型的交互式视觉工具。缩写为 WIT,它使人们能够通过检查、评估和比较机器学习模型来理解分类或回归模型。由于它的用户友好界面和对复杂编码的依赖程度较低,开发者、产品经理、研究人员或者学生都可以通过使用它来达到目的。
WIT 是由 Google 的 PAIR(人 + AI 搜索) 团队发布的一个开源可视化工具 。PAIR 通过 Google 将研究人员聚齐,研究并重新设计了人与 AI 系统的交互方式。
可以通过 TensorBoard 使用该工具,也可以将其作为 Jupyter 或 Colab notebook 的拓展使用。
优势
该工具的目的是为人们提供一种简单、直观和强大的方法,仅通过可视化界面就可以在一组数据上使用经过训练的机器学习模型。以下是 WIT 的主要优势。

在使用该工具的示例中,我们会涵盖上述的所有要点。
示例
为了说明 What-If 工具的功能,PAIR 团队已经使用预先训练过的模型发布了一组示例。你可以在 notebook 中运行演示程序或者直接在网页运行它。

用例
WIT 可以在 Jupyter 或 Colab notebook 中使用,也可以在 TensorBoard 网站应用程序中使用。在文档中已经对此进行了细致了的说明,我强烈建议你通过这篇短文来解释整个过程。
核心思想是,先训练一个模型,然后在测试集上使用 what-if 工具对训练的分类器的结果可视化。
结合 Tensorboard 使用 WIT
你需要通过 TensorFlow 模型服务器 部署你的模型,才能在 TensorBoard 中使用 WIT,而要分析的数据必须作为 TFRecords 文件。在 TensorBoard 使用 WIT 的更多细节,可以参阅文档。
在 notbook 上使用 WIT
为了能在 notebook 中访问 WIT,你需要一个 WitConfigBuilder 对象,该对象指定要分析的数据和模型。这个文档为在 notebook 中使用 WIT,提供了一个慢慢学习的教程。

为了确保工作的进行,你可以使用 notbook 示例,来编辑代码以此来容纳数据集。
完整示例
我们用一个示例来讨论 WIT 的功能。这个示例样本来自名为 Income Classification 的网站,我们需要根据一个人的人口普查来预测他一年的收入是否超过 5 万美元。数据集来源于 UCI Census dataset,由年龄、婚姻状况、教育程度等属性组成。
概览
我们首先对数据集进行研究。这里有一个用于后续演示的链接。
What-if 工具有两个主面板。右面板包含你加载的数据集中各个数据点的可视化内容。
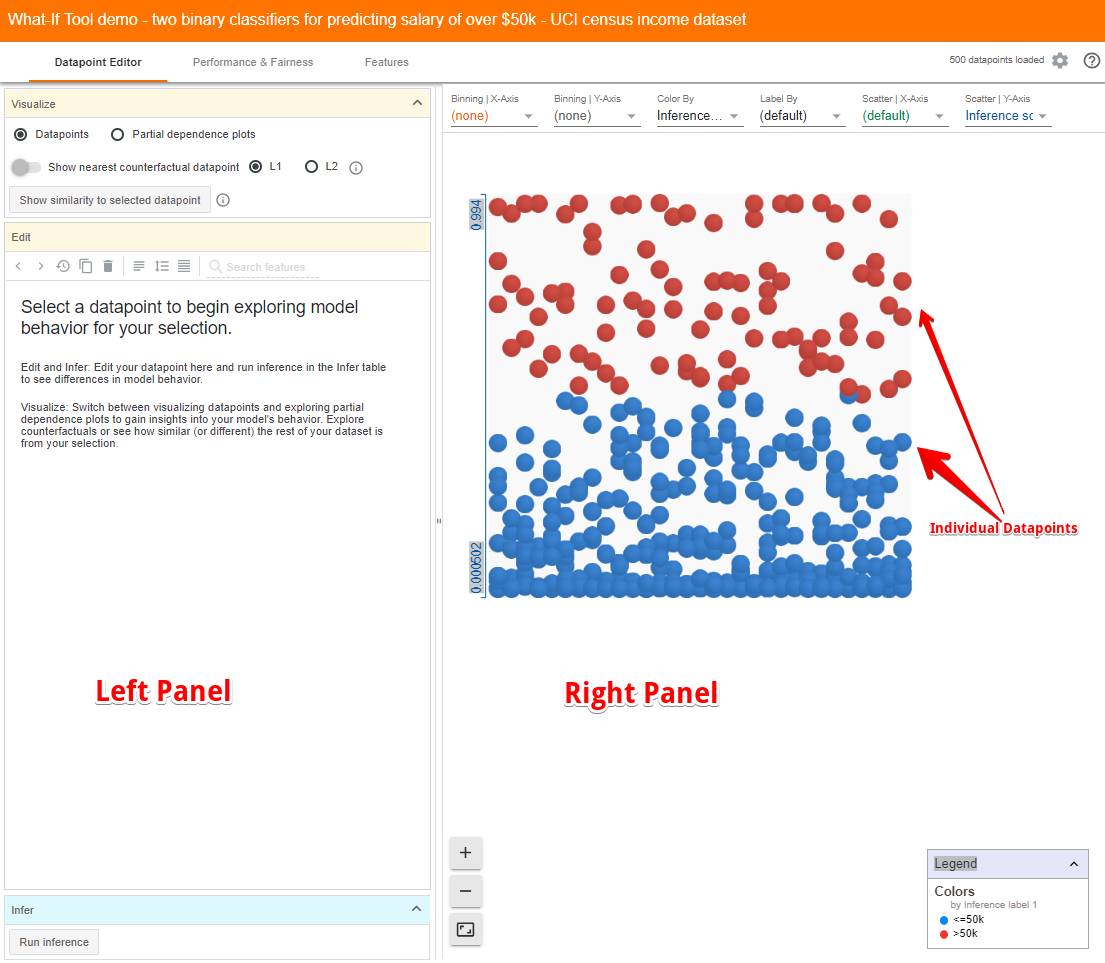
在这种情况下,蓝点是模型推断收入小于 50k 的人,红点是模型推断出收入超过 50k 的人。默认情况下,WIT 使用值为 0.5 的正分类阀值。这意味着,如果模型推断分数为 0.5 或以上,该数据点就会被视为在正类(即高收入)中。
这里值得注意的是,数据集是在 Facets Dive 中进行可视化的。Facets Dive 是 PAIR 团队重新开发的 FACETS 工具的一部分,它帮助我们理解数据的各种特性并探索它们。如果不熟悉该工具,你可以参考这篇关于 FACETS 功能的文章,它是我不就之前编写的。
人们还可以通过从下拉菜单中选择字段,以各种不同的方式来组织数据点,包括混淆矩阵、散点图、直方图和小倍数。以下是列举的几个例子。
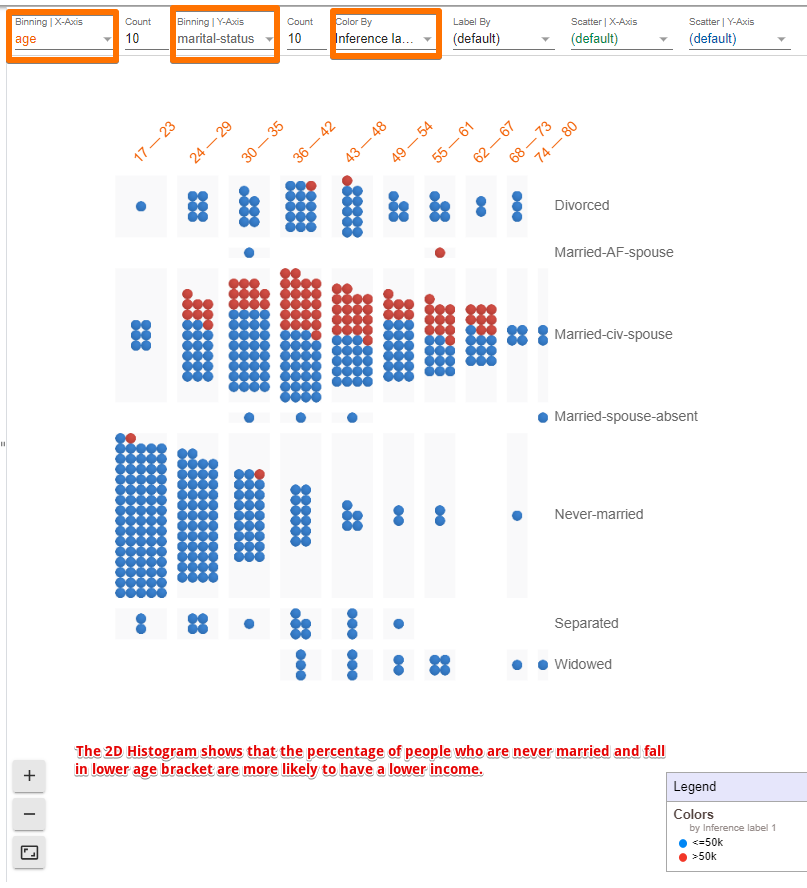
左面板包含三个选项卡 数据点编辑、性能和公平性 和 特征。
1. 数据点编辑面板
数据点编辑通过以下方式来完成数据分析:
- 查看和编辑数据点的详细信息
它允许进入在右侧面板中以黄色高亮的数据点。我们可以尝试将年龄从 53 改为 58,点击“运行”来观察它对模型性能的影响。
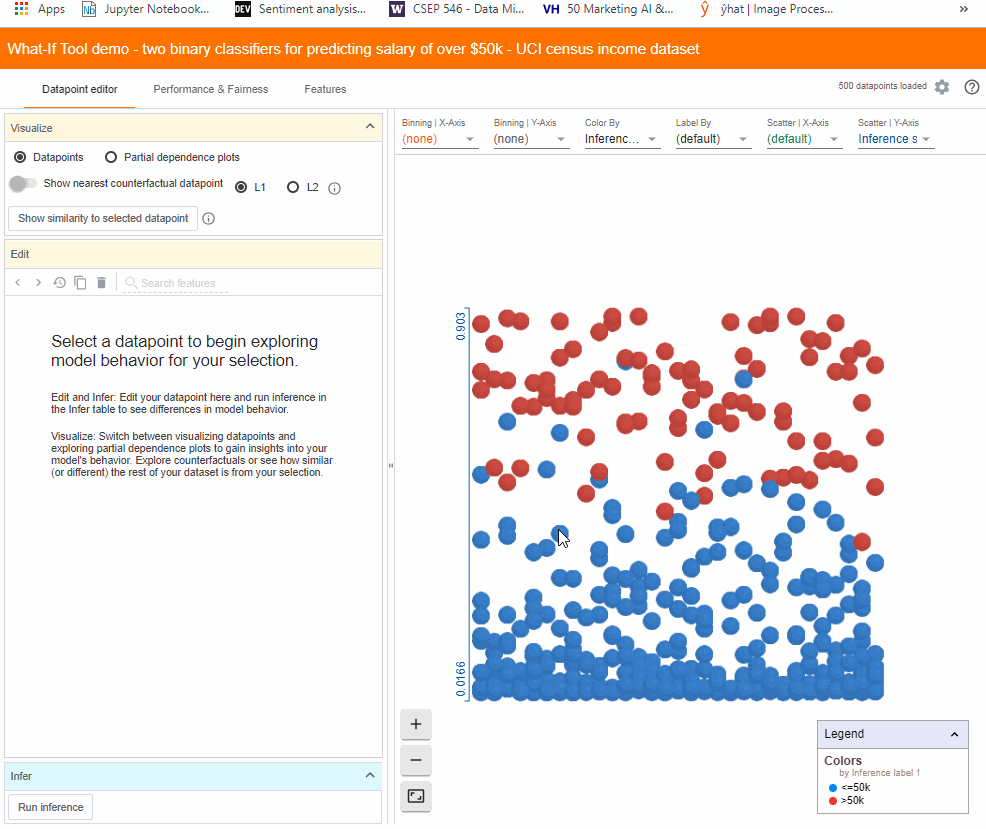
通过简单改变年龄,模型现在将预测这个人属于高收入类别。对于此数据点来说,早期的正类得分为 0.473,负类得分为 0.529。然而通过改变年龄,正得分达到了 0.503。
- 寻找最近的反事实
理解模型的另一种方式是,看看什么样的小范围更改会导致模型翻转其决策,即所谓的反事实。只要点击一下,我们就可以看到与我们所选定的数据点最相似的反事实(用绿色高亮)。在数据点编辑器选项卡中,我们还看到了与原始数据点的特征值相反的特征值。绿色文本表示两个数据点不同的特征。WIT 使用 L1 和 L2 距离来计算数据点之间的相似。
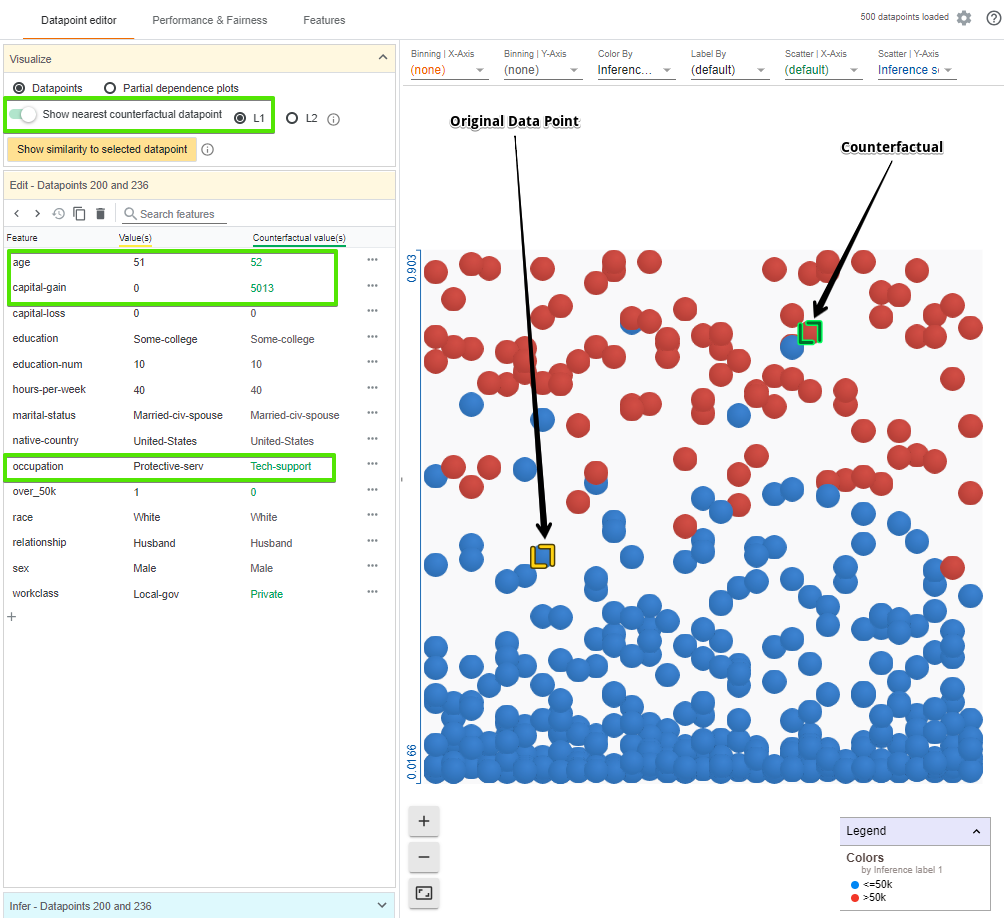
在这种情况下,最近的反事实是年龄稍大,有一个不同的职业和资本收益,但在其它方面是相同的数据点。
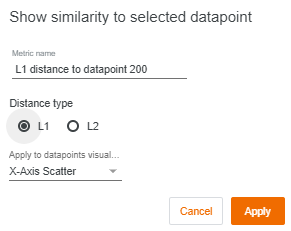
我们还可以使用显示与所选数据点相似的按钮来查看所选点与其它点之间的相似性。WIT 测量从选定的点到其他每一个数据点的距离。让我们改变我们的 X 轴跨度,来显示到选定数据点的 L1 距离。
- 分析部分依赖图
部分依赖图(简写为 PDP 或 PD 图)显示了一个或两个特征对机器学习模型预测结果的边缘效应(J. H. Friedman 2001)。
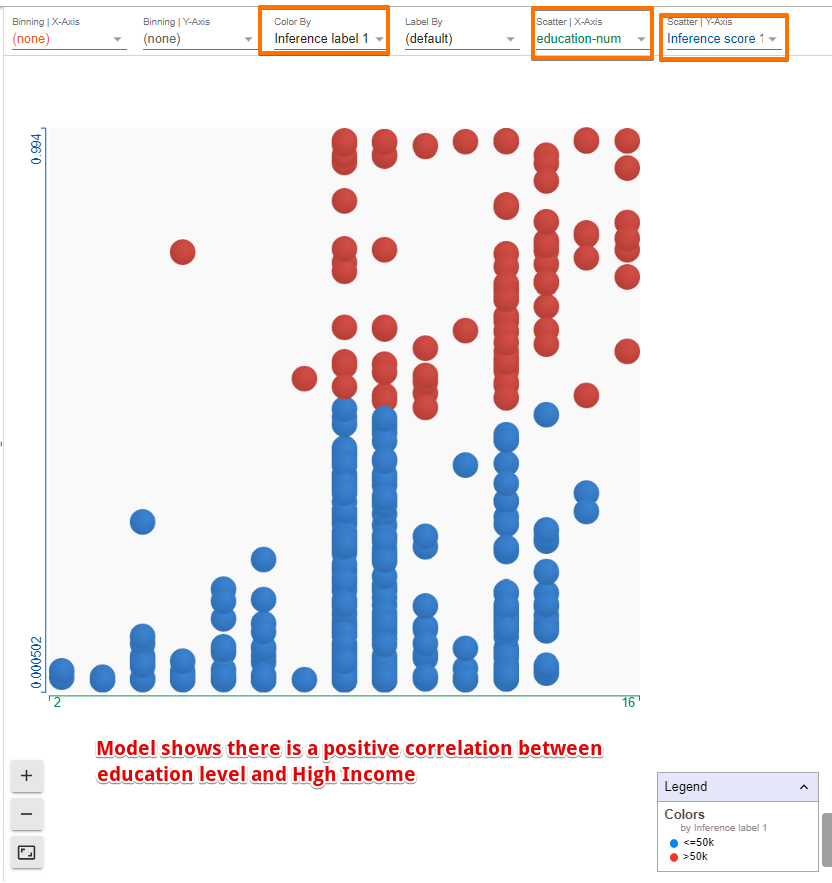
有关年龄和教育程度的数据点的 PDP 如下:
上图表明:
- 该模型学习到了年龄和收入之间的正相关
- 更高的学位会让模型更有信心判定此人为高收入
- 高资本收益是高收入的一个非常有力的指标,比任何其他单一特征都要强得多。
2. 性能和公平选项卡
这个选项卡允许我们使用混淆矩阵和 ROC 曲线来查看整个模型的性能。
- 模型性能分析
为了衡量模型的性能,我们需要告诉工具什么是真实特征,即模型视图预测的特征在这种情况下是“超过 —— 50k”。
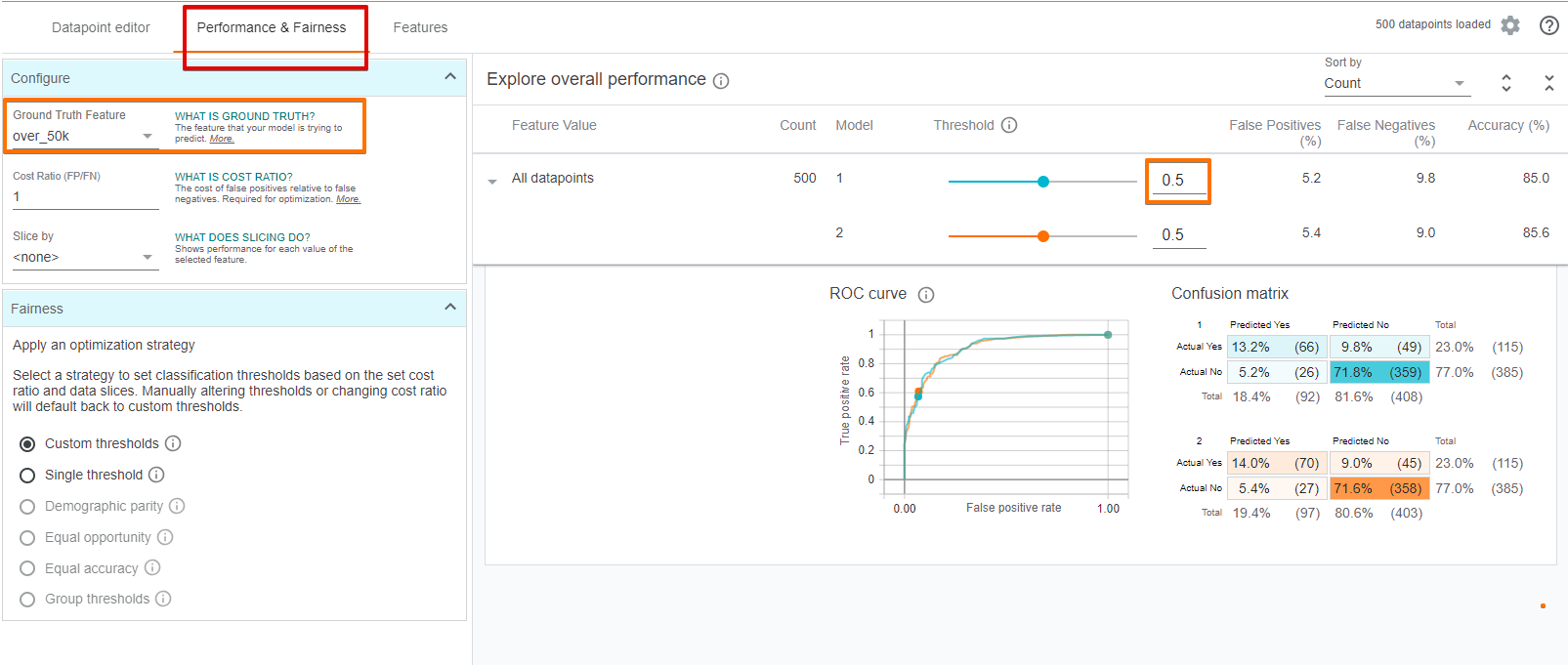
我们可以看到,在默认的阀值水平 0.5 时,大约有 15% 的情况,我们的模型是不正确的,大约 5% 的情况是假阳性,大约有 10% 的情况是假阴性。更改阀值来查看其对模型精度的影响。
可以进行调整的还有设置“成本比率”和“优化阀值”的按钮。
- 机器学习公平性
机器学习中的公平性与建模和预测结果一样重要。训练数据中的任何偏差都会反映在训练出来的模型中,如果部署了这样的模型,那得到的结果也会有偏差。WIT 可以通过考虑各种不同的方式来帮助调查公平问题。我们可以设置一个输入特征(或一组特征)来对数据进行切片。例如,让我们看看性别对模型性能的影响。
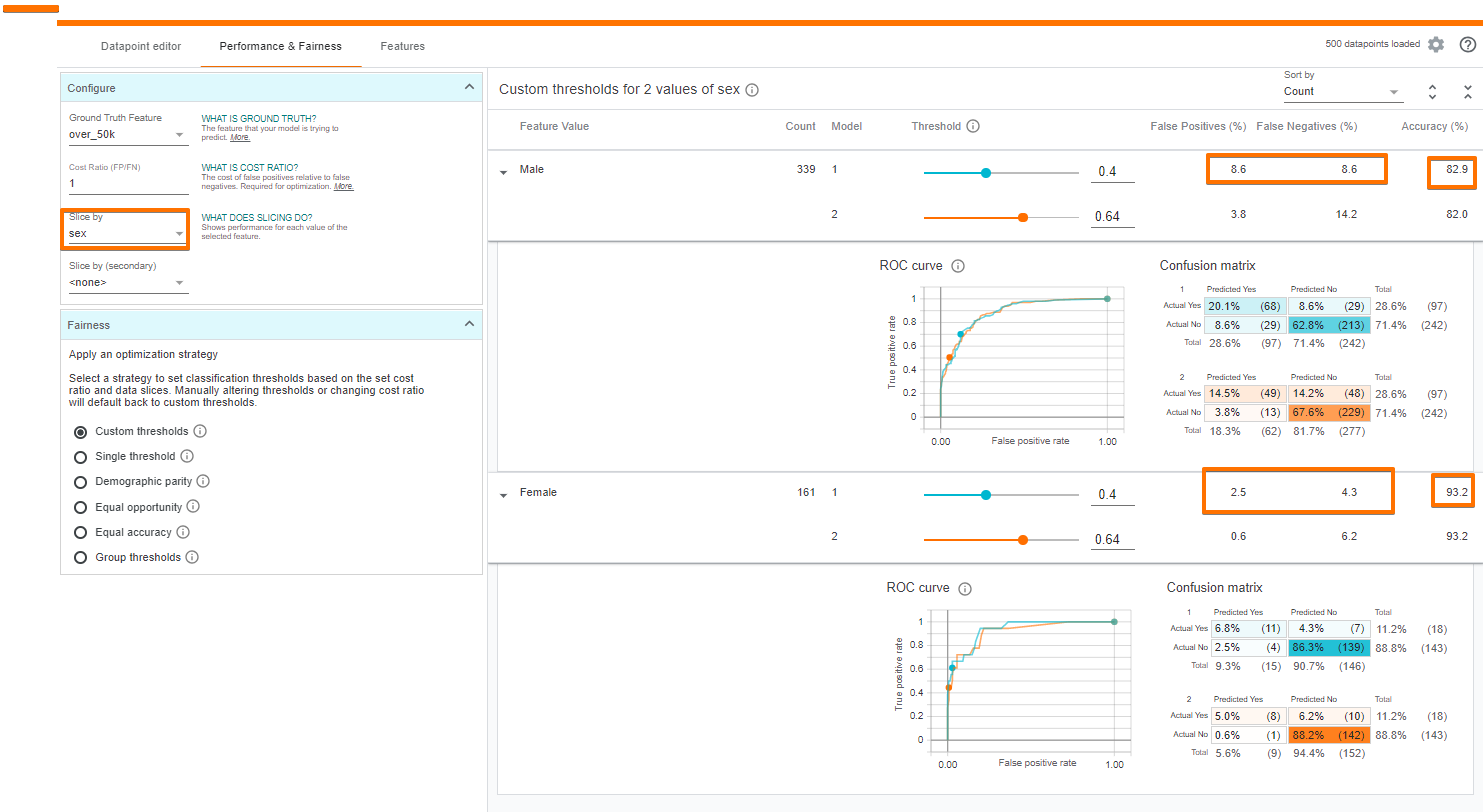
可以看到该模型对女性的预测比对男性更准确。此外,该模型预测,女性的高收入远低于男性(女性为 9.3%,男性为 28.6%)。一个可能的原因是由于女性在数据集中的代表性不足,我们会在下一节中继续深究这个问题。
此外,此工具可以最优化两个子集间设置的决策阀值,同时考虑与算法公平性相关的诸多约束中的任何一个比如人口统计或机会均等。
3. 特征选项卡
特征选项卡,提供了数据集中每个特征的汇总统计信息,包括直方图、分位数图、条形图等。该选项卡还允许查看数据集中每个特征的值分布。例如,它可以帮助我们探讨性别、资本收益和种族特征
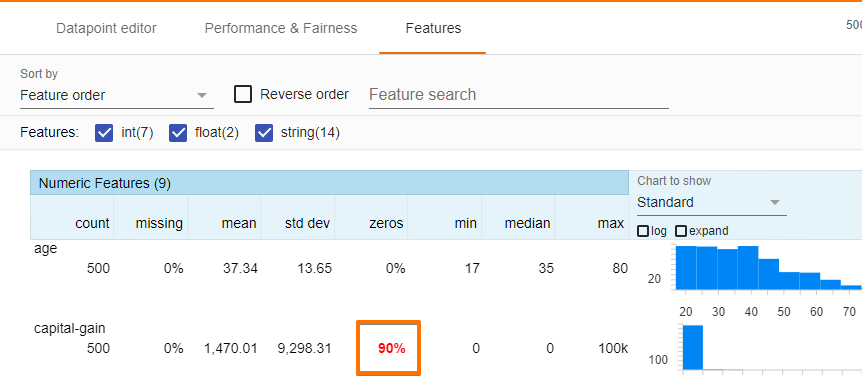
我们推断 资本收益 是极不一致的,大多数数据点都被设置为 0。


同样,大部分数据点来源于美国,而女性在数据集中没有很好的表现。因为数据有偏差,其预测只针对一个群体是很自然的。毕竟,模型从所提供的数据中学习,如果数据源存在偏差,那么结果一定也会有同样的偏差。机器学习已经在许多应用和领域证明了它的价值。然而,机器学习模型工业应用的一个关键障碍是确定用于训练模型的原始输入数据是否含有歧视性的偏差。
结论
这只是对一些 what-if 工具特性的简单预览。WIT 是一个非常方便的工具,它为决策者提供了探索模型的能力。简单的创建和训练模型并不是机器学习的目的,理解为何以及如何创建一个模型才是真正意义上的“机器学习”。
参考文献:
- The What-If Tool: Code-Free Probing of Machine Learning Models
- pair-code.github.io/what-if-too…
- github.com/tensorflow/…
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
