

背景
在我们做社区的时候,经常会出现发水帖的同学。对于这种恶意刷帖的,我们的运营同学很是头疼,而且这种还不能在网关进行ip之类的过滤,只能基于单个单个用户进行处理,我们经常策略就是:每分钟发帖次数不能超过2个,超过后就关小黑屋10分钟。
出现场景
- 上面讲的发帖的防刷机制。
- 广告流量的防刷。
- 接口请求失败进行熔断机制处理。
- ......
解决方案
对于这种“黑恶”请求,我们必须要做到是关小黑屋,当然有的系统架构比较大的,在网关层面就已经进行关了,我们这里是会在业务层来做,因为咱业务不是很大,当然同学们也可以把这个移植到网关层,这样不用穿透到我们业务侧,最少能够减少我们机房内部网络流量。
流程图
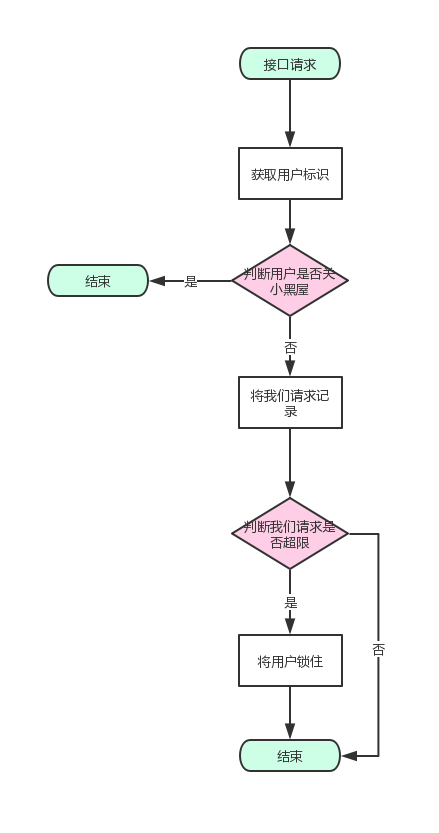
流程说明
- 接口发起请求,服务端获取这个接口用户唯一标识(用户id,电话号码...).
- 判断该用户是否被锁住,如果锁住就直接返回错误码。
- 未锁住就将该请求标记,亦或者叠加(叠加有坑,往下面看)。
- 进行计算当前用户在一定时间内是否超过我们设置的阈值。如果未超过直接返回。
- 如果超过,那么就进行锁定,再返回,下次请求的时候再进行判断。
具体方案
以我们场景为例子,使用Redis来做分布式锁和原子计数器
时间内叠加,判断叠加值是否超过阈值
这个方案,在很多人设计的时候,都会考虑,看起来也没有太大问题,主要流程是:
- 假设我们使用Redis来进行原子计数,每次进来我们进行incr操作,并且将我们的key设置为一个阈值过期时间.
//将我们用户请求量叠加1
$request_nums = Redis::incr('user:1:request:nums',1);
//第一次叠加,设置key的过期时间
if ($request_nums == 1){
Redis::expire('user:1:request:nums',300);
}
if($request_nums > 10){
//加入小黑屋,下次再进来就要锁定判断
}
...
- 每次请求会优先进行叠加,然后在这个有效区间内,计算我们的请求次数,如果请求次数超过阈值,那么关小黑屋,要是没有就继续走下去。
问题:咋一看是没有问题,每次计算都在我的区间内,能够保证一个区间内的请求量是没问题的,而且还是要我们Redis的原子计数器,但是这里有一个问题是,一个用户两个时间段内都没有问题,但是跨时间段这个点是没有考虑的。
那么有办法解决这个时间推移问题造成时间段计算量不精准的问题吗?
答案是肯定有,我接下来是使用了Redis的有序集合来做。
请求不进行时间段区分,直接写入有序集合
大致流程:
- 每次请求就写入有序集合里面,集合的sorce值是当前毫秒时间戳(防止秒出现重复),可以认为每一次请求就一个时间戳在里面。
- 从集合里面去掉10分钟以前所有的集合数据。然后计算出当前的集合里面数量
- 根据这个数量来与我们阈值做大小判断,如果超过就锁住,否则继续走下去
//将我们时间戳写入我们redis的有序集合里面
Redis::zadd('user:1:request:nums',1561456435,'1561456435.122');
//设置key的过期时间为10分钟
Redis::expire('user:1:request:nums',300);
//删除我们10分钟以前的数据
Redis::ZREMRANGEBYSCORE('user:1:request:nums',0,1561456135);
//获取里面剩下请求个数
$request_nums=(int)Redis::zcard(self::TIMELINE_ELEVEL_KEY);
if($request_nums >= 10){
//加入小黑屋,下次再进来就要锁定判断
}
...
因为我们不是单纯记录数值,而是会将请求时间记录下来,那么随着时间推移,我们的请求数统计是不会断代的。
总结
- 在开始的时候,我一直在想第一个方案的问题所在,后来在讨论方案时候,总是发现时间移动,数值应该是会更改,可在第一个方案内,我们的请求量是不会更改,我们时间段已经固化成数值了。
- 整体的方案设计我们使用到的Redis的有序集合来做,当然有更好的方案欢迎大家来推荐哈,这个对于redis的读写压力很大的,但是作为临时的数据存储,这个场景还是比较符合。
- 我们redis的所有操作建议使用原子化来进行,这个可以使用官方提供的lua脚本来将多个语句合并成一个语句,并且lua执行速率也是很高。
谢谢大家阅读!!!
