

1. 定义
正则表达式通俗的讲就是按照某种规则去匹配符合条件的字符串。
在前端开发中经常能够遇到它,比如说表单验证,字符处理等。虽然功能及其强大,在几乎所有语言中都可以使用,但是其繁杂的语法使其成了许多前端同学包括我的一个痛点。
所以今天做一个总结,理解最常用的正则语法。这样下次遇到正则表达式问题时就可以自己独立解决了。
先放上核心总结:
正则表达式是匹配模式,要么匹配字符,要么匹配位置
2. 工具
正则表达式可视化工具
https://jex.im/regulex/#!flags=&re=%5E(a%7Cb)*%3F%24
我们可以利用这个工具辅助理解正则表达式
3. 字符匹配
3.1 字符组
最简单的正则表达式可以由数字或字母组成。比如说如果想在 monky 这个单词里找到 o 这个字符,就直接用 /o/ 这个正则就可以了。
var regex = /o/;
console.log( regex.test("monkey") );
// => true
在正则表达式里,范围表示法使用中括号 []。例 [123] 表示匹配一个字符,它可以是 1、2、3 之一。
如果需要匹配所有的数字,可以使用 [0123456789],还可以简写成[0-9]。同理,匹配任意小写字母可以写成 [a-z]。
如果想匹配不以数字开头的字符呢,可以用排除字符组 [^]。例如[^0-9] 表示是一个除数字之外的任意一个字符。
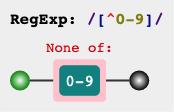
下面是一些常用的字符组:
| 字符组 | 含义 | 记忆方法 |
|---|---|---|
\d |
匹配一个数字字符,等价于 [0-9] |
digit |
\D |
匹配一个非数字字符,等价于 [^0-9] |
|
\w |
匹配字母、数字、下划线,等价于 [A-Za-z0-9_] |
word |
\W |
匹配非字母、数字、下划线。等价于 [^A-Za-z0-9_] |
|
\s |
匹配任何空白字符,包括空格、制表符、换页符,回车符等等,等价于 [ \f\n\r\t\v] (注意正则前面有个空格) |
space |
\S |
匹配任何非空白字符,等价于 [^ \f\n\r\t\v] |
|
. |
通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符 除外,等价于 [^\n\r\u2028\u2029] |
注意:如果你想查找元字符本身的话,需要使用 \ 来转义,比如说查找. 和 \,就得使用 \. 和 \\。
3.2 重复
比如说 \d{3} 表示 数字 必须重复三次。
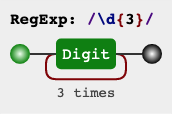
下面是一些常用的重复限定符:
| 限定符 | 含义 |
|---|---|
* |
重复零次或更多次 |
+ |
重复一次或更多次 |
? |
重复零次或一次 |
{n} |
重复n次 |
{n,} |
重复n次或更多次 |
{n,m} |
重复n到m次 |
3.3 贪婪匹配与惰性匹配
正则表达式在匹配时,默认行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。
var regex = /a.*b/g;
var string = "aabab";
console.log(string.match(regex) );
// ["aabab"]
以这个表达式为例:它会匹配整个字符串 aabab 。这被称为贪婪匹配。
有时我们需要惰性匹配,也就是匹配尽可能少的字符。
这时候前面给出的重复限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号 ? 。
var regex = /a.*?b/g;
var string = "aabab";
console.log(string.match(regex) );
// ["aab", "ab"]
下面是一些常用的惰性重复限定符:
| 限定符 | 含义 |
|---|---|
*? |
重复零次或更多次,但尽可能少重复 |
+? |
重复一次或更多次,但尽可能少重复 |
?? |
重复零次或一次,但尽可能少重复 |
{n,}? |
重复n次或更多次,但尽可能少重复 |
{n,m}? |
重复n到m次,但尽可能少重复 |
3.4 分支
正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用 | 把不同的规则分隔开。
比如说:(apple|banana|watermelon) 表示匹配 apple 或 banana 或watermelon`。
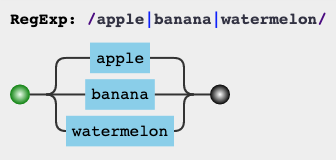
var regex = /apple|banana|watermelon/g;
var string = "would you like apple or banana?";
console.log(string.match(regex));
// => ["apple", "banana"]
4. 位置匹配
如图,位置(锚)是相邻字符之间的位置。
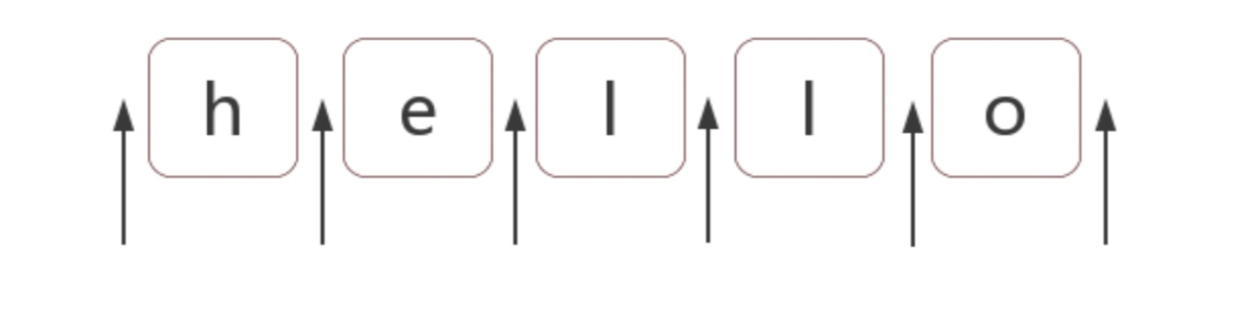
常见的位置锚有:
| 位置锚 | 含义 |
|---|---|
^ |
匹配开头,在多行匹配中匹配行开头 |
$ |
匹配结尾,在多行匹配中匹配行结尾 |
\b |
boundary,单词边界,具体就是 \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置 |
\B |
非单词边界,与 \b 相反,是 \w 与 \w、 \W 与 \W、\W 与 ^,\W 与 $ 之间的位置 |
(?=p) |
p 是一个子模式,即 p 前面的位置,或者说,该位置后面的字符要匹配 p(匹配的是位置) |
(?!p) |
p 是一个子模式,即 非p字符 前面的位置,或者说,该位置后面的字符不能有 p(匹配的是位置) |
其可视化形式见下图:

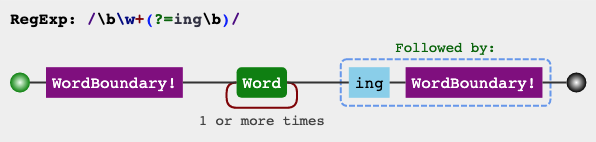
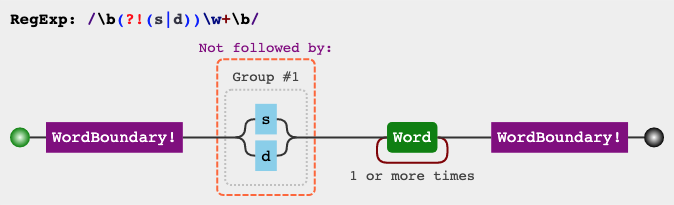
下面两个例子,第一个是匹配以 ing 结尾的单词的前面部分(除了ing以外的部分),第二个是匹配不以 s 和 d 开头的单词。
var regex = /\b\w+(?=ing\b)/g;
var string = "I'm singing while you're dancing.";
console.log(string.match(regex));
// ["sing", "danc"]
var regex = /\b(?!(s|d))\w+\b/g;
var string = "I'm singing while you're dancing.";
console.log(string.match(regex));
// ["I", "m", "while", "you", "re"]
两个例子的可视化形式见下图:
5. 分组
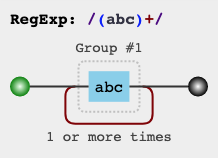
正则中用小括号来指定分组(也叫做子表达式)。比如说 (abc)+ ,就是一个分组,小括号使 abc 成了一个整体。
5.1 分组引用
对字符串使用带 () 的正则操作后,可以通过 $1, $2, ... 或者全局的 RegExp.$1, RegExp.$2, ... 来对分组数据进行引用。
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var date = "2019-06-18";
var result = date.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/18/2019"
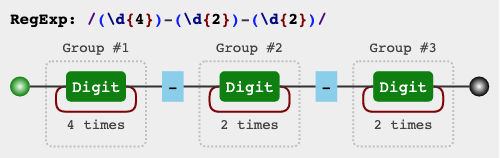
等价于:
var regex2 = /(\d{4})-(\d{2})-(\d{2})/;
var date2 = "2019-06-19";
var result2 = date2.replace(regex2, function () {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result2);
// => "06/19/2019"
5.2 反向引用
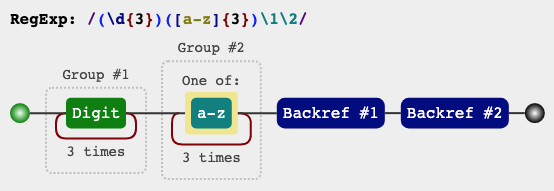
反向引用指的是模式的后面部分引用前面已经匹配到的子字符串。语法是 \1,\2,.... ,其中 \1 表示引用的第一个子表达式,\2 表示引用的第二个子表达式,以此类推。而 \0 则表示整个表达式。
var regex = /(\d{3})([a-z]{3})\1\2/;
var string = '123abc123abc';
console.log(regex.test(string));
console.log(RegExp.$1);
console.log(RegExp.$2);
// => true
// => 123
// => abc
上例中,\1 表示第一个分组内容,即 123,
\2 表示第二个分组内容,即 abc。
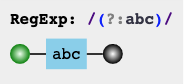
5.3 非捕获括号
普通的括号都会捕获匹配数据,以便后续引用。如果我们不需要引用,为了节约内存,可以使用非捕获括号 (?:regex)
例如 (?:abc),下图已经没有了 Group #1 的标识
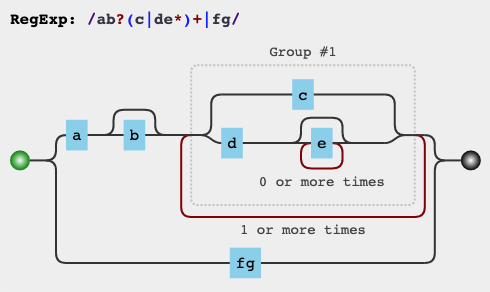
6. 符号优先级
当各种运算符号混杂在一起时,确定其优先级成为了一件至关重要的事。下表是常用操作符的运算优先级,优先级从高到底:
| 操作符描述 | 操作符 | 优先级 |
|---|---|---|
| 转义符 | \ |
1 |
| 括号和方括号 | (...)、(?:...)、(?=...)、(?!...)、[...] |
2 |
| 量词限定符 | {m}、{m,n}、{m,}、?、*、+ |
3 |
| 位置和序列 | ^、$、\元字符、一般字符 |
4 |
| 管道符(竖杠) | | |
5 |
例 /ab?(c|de*)+|fg/,其可视化形式为:
到这里为止,正则的基本语法就讲完了。还记得开头的核心总结吗:
正则表达式是匹配模式,要么匹配字符,要么匹配位置
是不是对这句话有了较为深入的理解。
接下来的文章会介绍 Js 里一些正则的 API,并结合实例来说明一些常用正则的使用。
主要参考来源:
