

- 原文地址:medium.com/@genchilu/w…
- 原文作者:Genchi Lu
- 译文地址:github.com/watermelo/d…
- 译者:咔叽咔叽
- 译者水平有限,如有翻译或理解谬误,烦请帮忙指出
在解释缓存 false sharing 之前,有必要简要介绍一下缓存在 CPU 架构中的工作原理。
CPU 中缓存的最小化单位是缓存行(现在来说,CPU 中常见的缓存行大小为 64 字节)。因此,当 CPU 从内存中读取变量时,它将读取该变量附近的所有变量。图 1 是一个简单的例子:
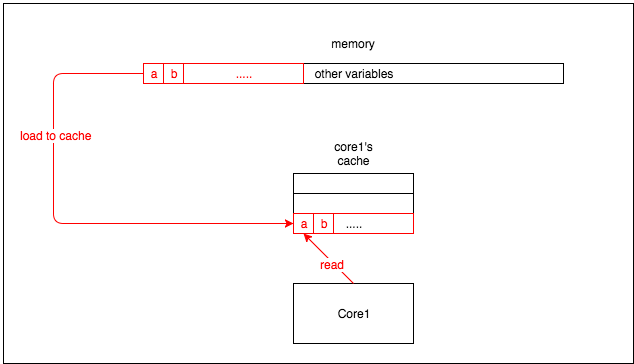
当 core1 从内存中读取变量 a 时,它会同时将变量 b 读入缓存。(顺便说一下,我认为 CPU 从内存中批量读取变量的主要原因是基于空间局部性理论:当 CPU 访问一个变量时,它可能很快就会读取它旁边的变量。)(译者注:关于空间局部性理论可以参考这篇文章)
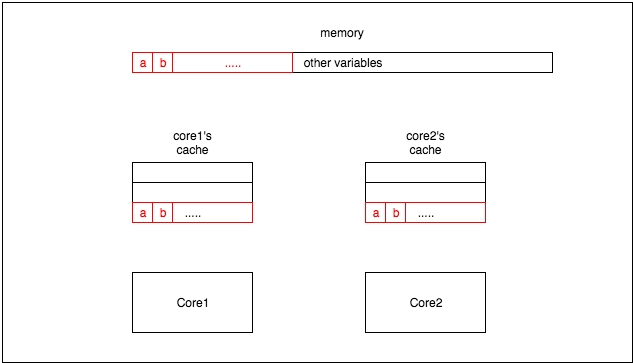
该缓存架构存在一个问题:如果一个变量存在于不同 CPU 核心中的两个缓存行中,如图 2 所示:
当 core1 更新变量 a 时:
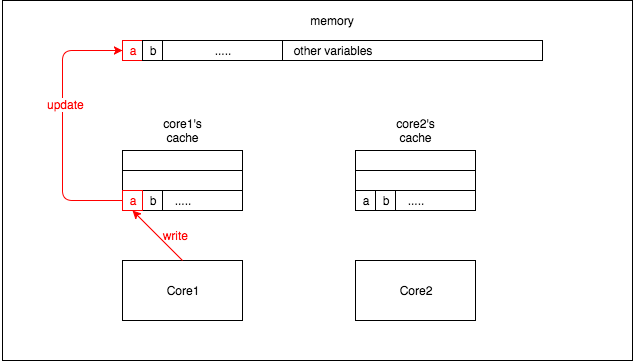
当 core2 读取变量 b 时,即使变量 b 未被修改,它也会使 core2 的缓存未命中。所以 core2 会从内存中重新加载缓存行中的所有变量,如图 4 所示:
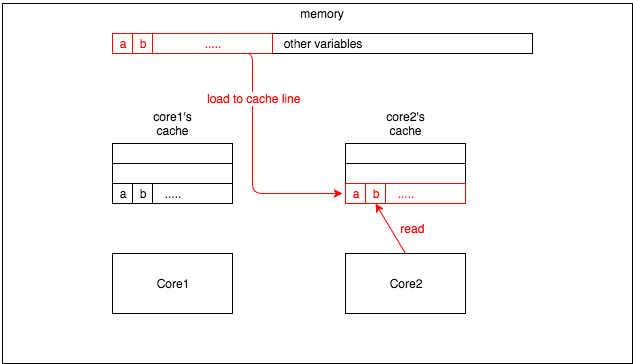
这就是缓存 false sharing:一个 CPU 核更新变量会强制其他 CPU 核更新缓存。而我们都知道从缓存中读取 CPU 的变量比从内存中读取变量要快得多。因此,虽然该变量一直存在于多核中,但这会显著影响性能。
解决该问题的常用方法是缓存填充:在变量之间填充一些无意义的变量。使一个变量单独占用 CPU 核的缓存行,因此当其他核更新时,其他变量不会使该核从内存中重新加载变量。
我们使用如下的 Go 代码来简要介绍缓存 false sharing 的概念。
这是一个带有三个 uint64 变量的结构体,
type NoPad struct {
a uint64
b uint64
c uint64
}
func (myatomic *NoPad) IncreaseAllEles() {
atomic.AddUint64(&myatomic.a, 1)
atomic.AddUint64(&myatomic.b, 1)
atomic.AddUint64(&myatomic.c, 1)
}
这是另一个结构,我使用 [8]uint64 来做缓存填充:
type Pad struct {
a uint64
_p1 [8]uint64
b uint64
_p2 [8]uint64
c uint64
_p3 [8]uint64
}
func (myatomic *Pad) IncreaseAllEles() {
atomic.AddUint64(&myatomic.a, 1)
atomic.AddUint64(&myatomic.b, 1)
atomic.AddUint64(&myatomic.c, 1)
}
然后写一个简单的代码来运行基准测试:
func testAtomicIncrease(myatomic MyAtomic) {
paraNum := 1000
addTimes := 1000
var wg sync.WaitGroup
wg.Add(paraNum)
for i := 0; i < paraNum; i++ {
go func() {
for j := 0; j < addTimes; j++ {
myatomic.IncreaseAllEles()
}
wg.Done()
}()
}
wg.Wait()
}
func BenchmarkNoPad(b *testing.B) {
myatomic := &NoPad{}
b.ResetTimer()
testAtomicIncrease(myatomic)
}
func BenchmarkPad(b *testing.B) {
myatomic := &Pad{}
b.ResetTimer()
testAtomicIncrease(myatomic)
}
使用 2014 年的 MacBook Air 做的基准测试结果如下:
$> go test -bench=.
BenchmarkNoPad-4 2000000000 0.07 ns/op
BenchmarkPad-4 2000000000 0.02 ns/op
PASS
ok 1.777s
基准测试的结果表明它将性能从 0.07 ns/op 提高到了 0.02 ns/op,这是一个很大的提高。
你也可以用其他语言测试这个,比如 Java,我相信你会得到相同的结果。
在将其应用于你的代码之前,应该了解两个要点:
- 确保系统中 CPU 的缓存行大小:这与你使用的缓存填充大小有关。
- 填充更多变量意味着消耗更多内存资源。在你的方案中运行基准测试以确保这些内存消耗是值得的。
我的所有示例代码都在GitHub上。
