

Python 实用爬虫 - 使用 BeautifulSoup 去水印下载 CSDN 博客图片
其实没太大用,就是方便一些,因为现在各个平台之间的图片都不能共享,比如说在 CSDN 不能用简书的图片,在博客园不能用 CSDN 的图片。 当前想到的方案就是:先把 CSDN 上的图片都下载下来,再手动更新吧。 所以简单写了一个爬虫用来下载 CSDN 平台上的图片,用于在其他平台上更新图片时用
更多内容,请看代码注释
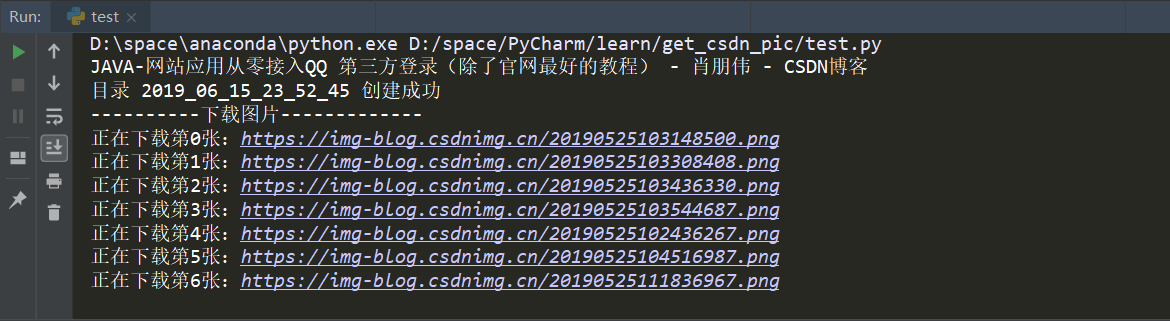
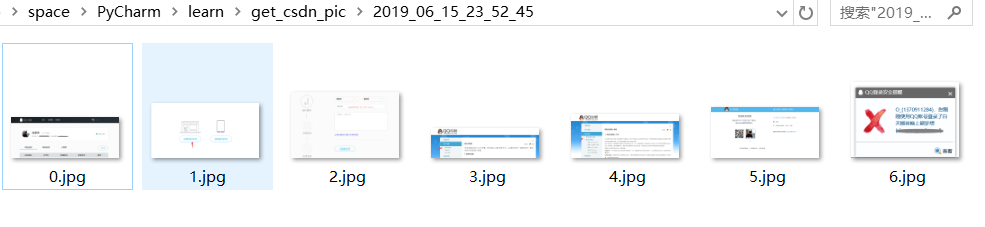
效果演示
Python 源代码
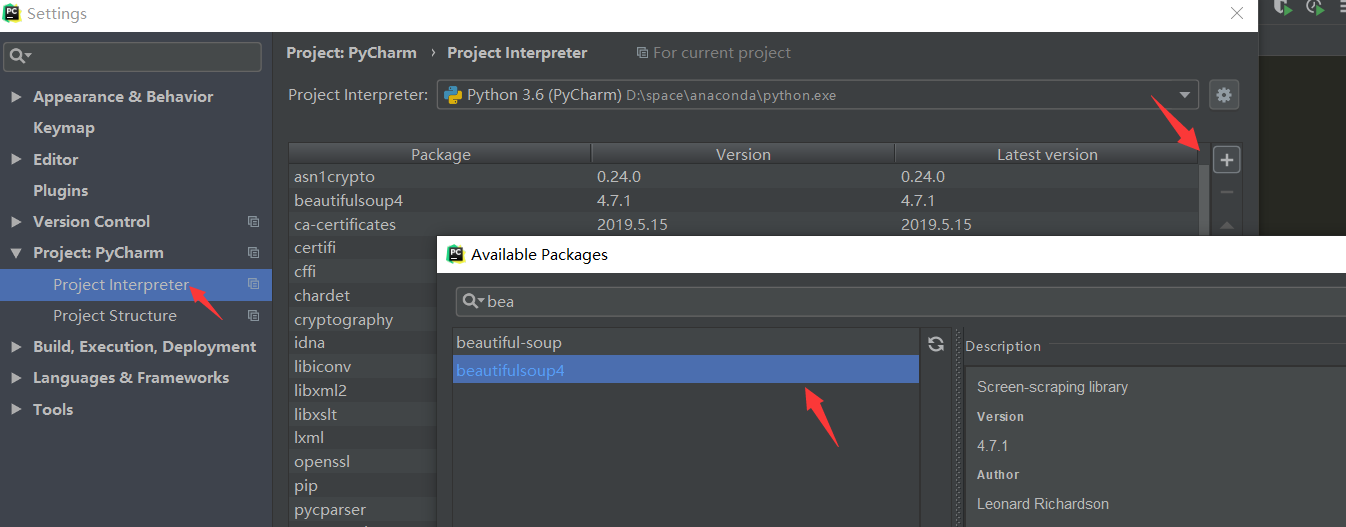
提示: 需要先下载 BeautifulSoup 哦,可以用 pip,也可以直接在 PyCharm 中安装 简单的方法:
# coding:utf-8
'''
使用爬虫下载图片:
1.使用 CSDN 博客
2.获取图片连接,并下载图片
3.可去除水印
作者:java997.com
'''
import re
from urllib import request
from bs4 import BeautifulSoup
import datetime
# 构造无水印纯链接数组
def get_url_array(all_img_href):
img_urls = []
for h in all_img_href:
# 去掉水印
if re.findall("(.*?)\?", h[1]):
h = re.findall("(.*?)\?", h[1])
# 因为这里匹配就只有 src 了, 所以直接用 0
img_urls.append(h[0])
else:
# 因为这里还没有处理有 alt 的情况, 所以直接用 1
img_urls.append(h[1])
return img_urls
# 构建新目录的方法
def mkdir(path):
# 引入模块
import os
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print('目录 ' + path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print('目录 ' + path + ' 已存在')
return False
if __name__ == '__main__':
# url = input("请粘贴博客链接")
url = "https://blog.csdn.net/qq_40147863/article/details/90484190"
# 获取页面 html
rsp = request.urlopen(url)
all_html = rsp.read()
# 一锅清汤
soup = BeautifulSoup(all_html, 'lxml')
# bs 自动解码
content = soup.prettify()
# 获取标题
tags = soup.find_all(name='title')
for i in tags:
# .string 是去掉标签, 只打印内容
print(i.string)
# 获取正文部分
article = soup.find_all(name='article')
# print(article[0])
# 获取图片的链接
all_img_href = re.findall('<img(.*?)src="(.*?)"', str(article))
# 调用函数, 获取去掉水印后的链接数组
img_urls = get_url_array(all_img_href);
# 用当前之间为目录名, 创建新目录
now_time = datetime.datetime.now()
now_time_str = datetime.datetime.strftime(now_time, '%Y_%m_%d_%H_%M_%S')
mkdir(now_time_str)
print("----------下载图片-------------")
i = 0
for m in img_urls:
# 由于没有精确匹配,并不是所有连接都是我们要的课程的连接,排出第一张图片
print('正在下载第' + str(i) + '张:' + m)
# 爬取每个网页图片的连接
img_url = request.urlopen(m).read()
# img 目录【必须手动创建好】
fp = open(now_time_str+'\\' + str(i) + '.jpg', 'wb')
# 写入本地文件
fp.write(img_url)
# 目前没有想到更好的方式,暂时只能写一次,关闭一次,如果有更好的欢迎讨论
fp.close()
i += 1
