

享学特邀作者:老顾
前言
相信小伙伴应该都用到过mysql数据库,在mysql数据库中,为了提升查询效率,都会使用到索引技术。今天老顾就来介绍一下mysql索引的数据结构的演变。
数据查询
我们来看一下有个用户表,存放这基本的用户信息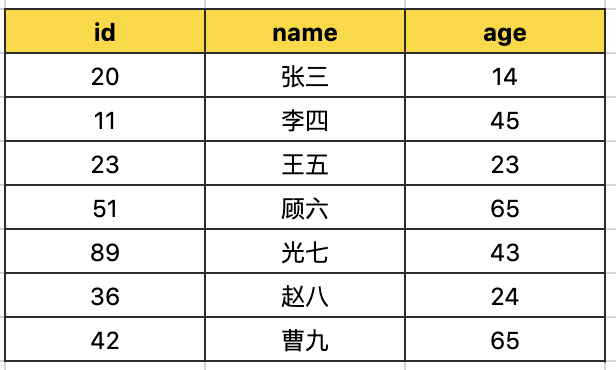
需求要我们找出id为51的用户信息
如果我们是mysql开发工程师的话,怎么设计数据库的查询,最简单做法就是一个个比较id,是否等于51,然后在返回给用户。
这种方式会存在很大的问题:
1、运气好的话 比较1次直接返回
2、运气差的话 比较7次才能返回
这个方案就是全部遍历的方式,从第一条记录开始遍历,一直遍历下去。我们这么才7条记录,如果几百万条,那查询性能太低了。
二叉树
为了解决这个问题,我们引入索引技术,改变一些数据存储结构。首先想到的结构,就是二叉树。
二叉树的特点:
1、一个节点只能有两个子节点,也就是一个节点度不能超过2
2、左子节点 小于 本节点;右子节点大于等于 本节点
我们看一下上面的数据,以id为索引,建立的二叉树的结构是什么?
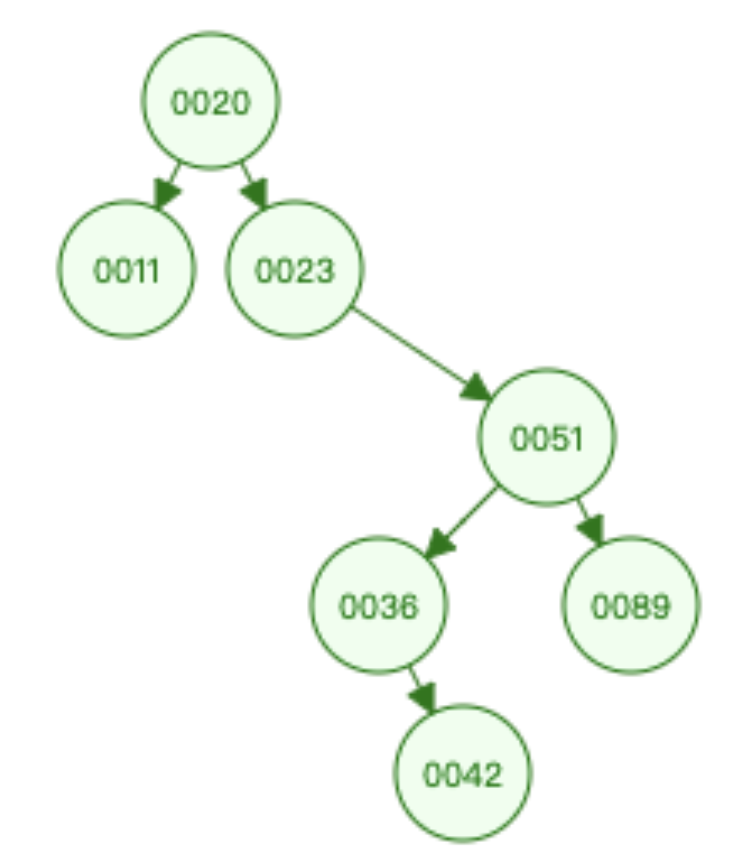
因为二叉数的特点,右边比左边大,这次我们查询id=51,只需要比较3次,因为有一部分数据是不需要比较的,再索引建立的时候就已经排序好了。
这个二叉树比之前的遍历的方案,性能提高了很多。但他也有一个问题,如果id的值是持续递增的话,会是什么样的结构?
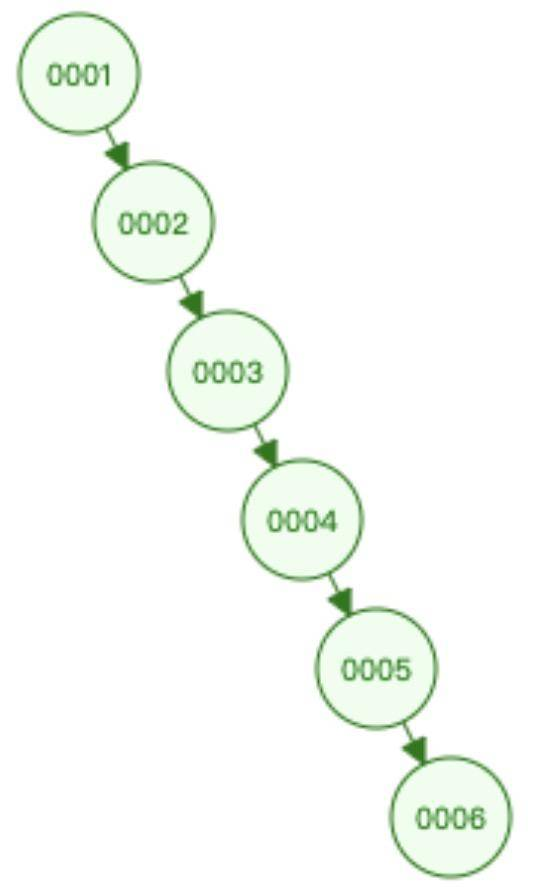
我们发现如果id是持续递增的话,我们的二叉树结构出现了残缺,如果这个时候查找id=5,也是从一直遍历到最后,没有像之前的数据那样,排除掉一部分数据。那怎么解决?
红黑树
红黑树的出现就可以解决这个问题,红黑树的特点会自动平衡树,其他特点(小伙伴们自行度娘)。我们看一下红黑树怎么平衡?
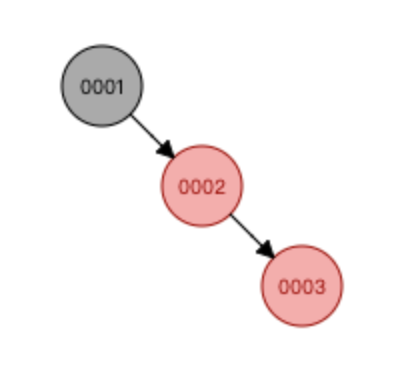
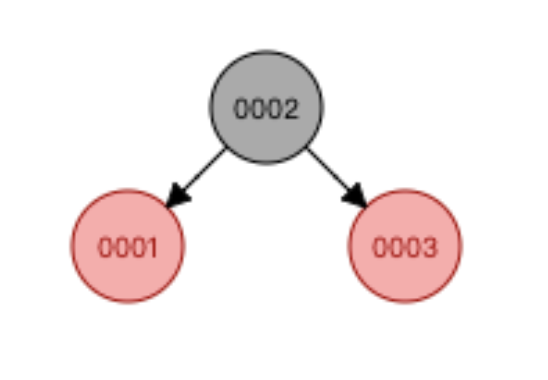
上面两个图,左图在插入数值为3时,红黑树的算法发现有偏向,就会重新调整树结构;调整到右边的图
那我们可以看看,之前的数据1~6持续递增的树,会变成什么样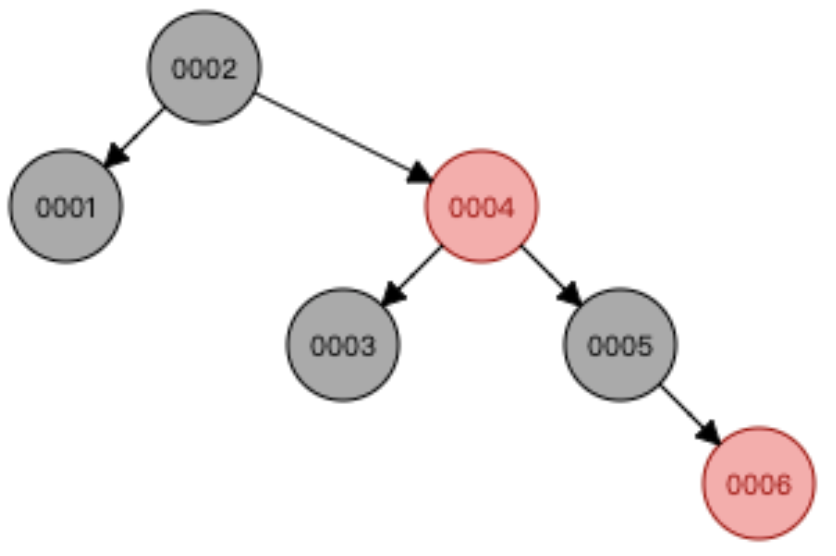
我们看到红黑树的结构,这样我们再次查找数据为5,只需要比较3次,有部分数据被提前排序了。红黑树很好的平衡了树的偏向问题,但红黑树问题也比较大。
1、每次都要检查规则,再把树进行重新平衡,这个是非常消耗时间的
2、数据量大的话,红黑树的深度会比较深,树一旦深就代表着我们读取磁盘次数就会增加
B树
小伙伴们有没有发现,影响数据查询时间的是树的高度,高度越高,我们需要比较的次数越多,那我们是不是可以想办法把树的高度弄低点?那我们的B树数据结构就由此产生。
B树的特点
假如当前有一颗m阶的B树(注意阶的意思是指每个节点的孩子节点的个数),那么其符合
(1)每个节点最多有m个子节点
(2)除了根节点和叶子节点之外,其他的每个节点最少有m/2(向上取整)个孩子节点
(3)根节点至少有两个孩子节点,(除了第一次插入的时候,此时只有一个节点,根节点同时是叶子节点)
(4)所有的叶子节点都在同一层
(5)有k个子节点的父节点包含k-1个关键码
(6)所有的叶节点都在同一层
(7)每个节点中的子节点都是从左到右排序的
小伙伴们是不是看到这个比较晕,这么多的特点(其实还有更多性质,老顾也记不住);其实我们不需要记住这么多的特点,只要记住几个核心点,先看图
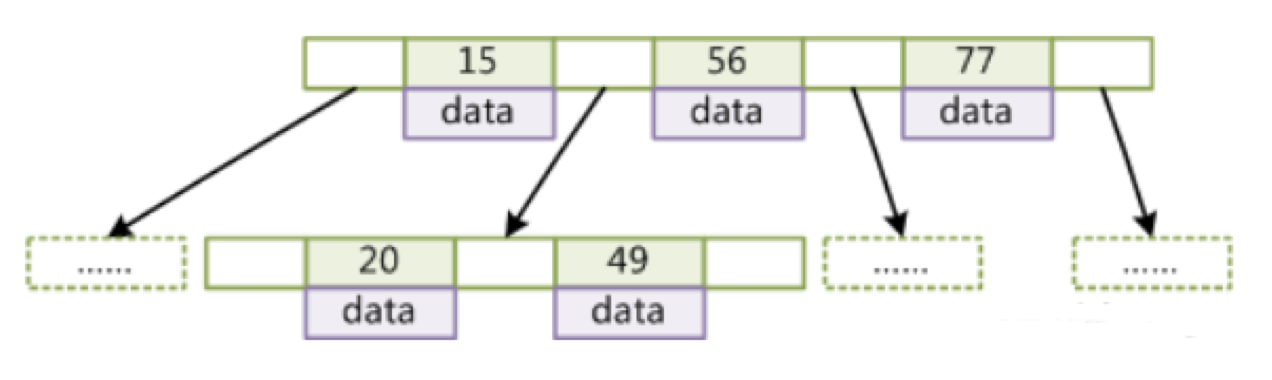
我们的主要目标就是把树的高度弄低,上图中,我们可以看到之前的一个节点里面多了几个子节点(即几阶树)【核心点一】,这样的设计就是把之前节点只存储1个数值,现在可以存储多个数值。
多个子节点数值都是从左到右排序【核心点二】,有便于快速查找。而且叶节点具有相同的深度,保证了每个数值查询效率一致【核心点三】。
图中每个节点里面都包含具体信息data【核心点四】,再查询的时候找到对应的索引后,直接取出这个节点中的信息。
B树的核心思想就是把树高度弄低,用了树节点包含多个子节点的设计思想,上图中一个树节点包含3个子节点。
小伙伴有没有过这个想法,那我们可以把树节点包含更多子节点,10个、100个、甚至1万个,这样就让树高度越来越小,甚至就只有一个树根节点,这样不是更好吗?往下看
硬盘原理
这里就涉及到计算机原理的知识了,用通俗的图表示一下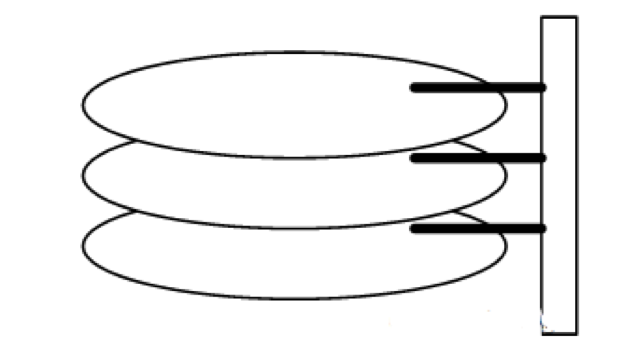
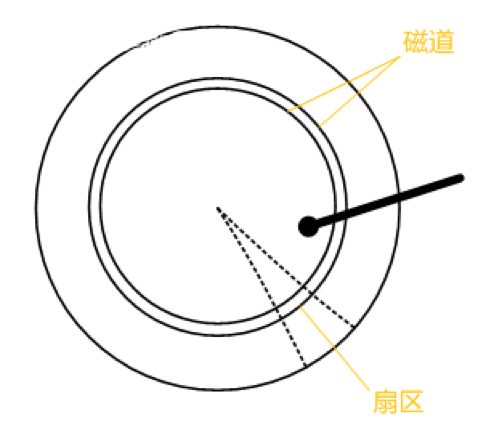
读取数据流程主要交给磁头和磁盘,我们的数据存放在每个扇区中,要读取一个扇区数据,需要把磁头移动到相应的磁道上面,然后磁盘快速旋转,从而读取到里面值。(详细知识自行度娘)
整个过程磁头寻道是比较慢的,我们与硬盘的交互尽量减少寻道这个动作
上面小伙伴有个疑问,我们能否扩大树节点中的子节点数,甚至只有一个根节点就行了。这个是不行的,因为小伙伴们不要忘了,内存也是有限的,所有数据存储在一个根节点中,数据量一旦上亿就吃不消了。
其实本质还有一个基本知识就是【磁盘有预读机制,每次读的时候都是加载一个磁盘页到内存里面】,这话的理解就是一次磁盘I/o读取只能读一个磁盘页大小(4kb)的数据到内存中,也就是8kb的数据,要磁盘i/o的2次操作。
就是因为这个磁盘预读机制,也就是不可能树的节点随便我们设置,应该树节点的数据量正好是一个磁盘页的大小,这样效率最高,一次IO读取一个树节点。
B+树
有了上面的知识铺垫,终于到了这里。我们来看一下上面的B树,一个树节点我们应该尽可能的包含更多的子节点,但又不能超过一个磁盘页(4kb)的大小。
我们小伙伴们是不是想到进一步的优化点,我们发现B树的节点中还包含了一些关键字信息data,这个data也占据着一定的数据量,我们是不是可以把data去掉,这样就又能多加几个子节点了。这也就是B+树的核心思想,看图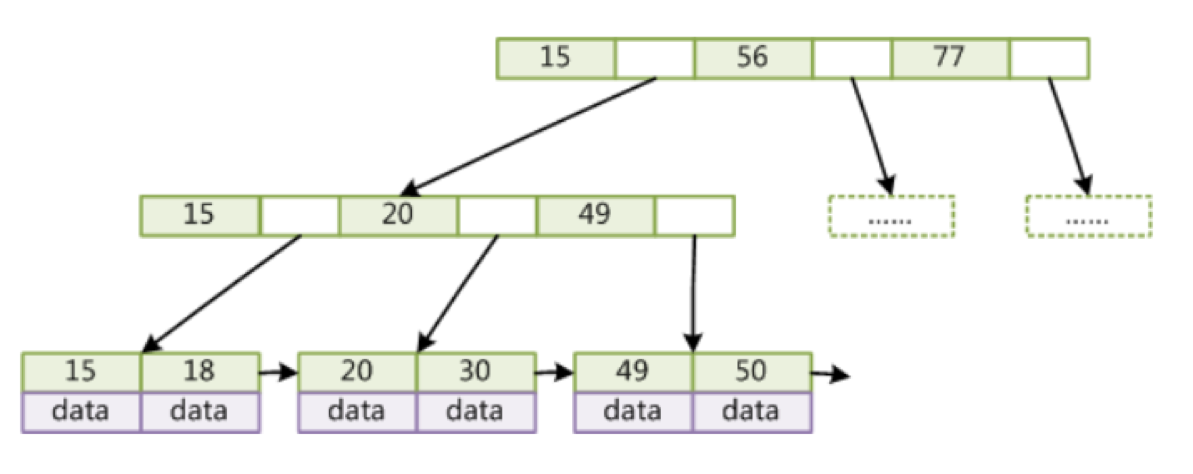
图中可以看出所有data信息都移动了子节点中,而且子节点和子节点之间会有个指针指向,这个也是B+树的核心点,这样可以大大提升范围查询效率,也方便遍历整个树。
这样的设计又大大的减少了树的高度,一般B+树的阶数(树节点包含的子节点数)不会超过100,这样一般保证树的高度在3~5层而已,查询速度大大的提升。
总结
到了这里应该知道为什么Mysql的索引结构采用了B+树了吧,算法和数据结构一直在演变中。老顾这里再留一个面试题,为什么InnoDB表必须有主键,并且推荐使用整型的自增主键,为什么不推荐用UUID?小伙伴结合上面知识想想,谢谢!
