


前言
- 对于java常用,相对简单的类做一个深度解析,挖掘其实现亮点
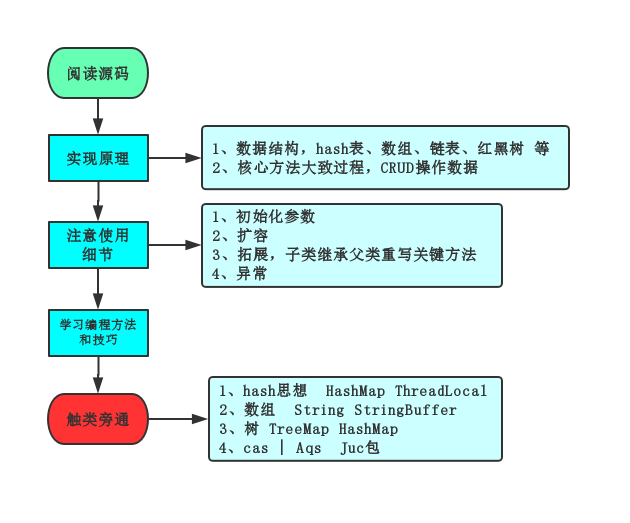
- 阅读源码步骤
数据结构
- 类都是在操作数据,从数据结构入手
transient Object[] elementData; //存放数据
private int size; //记录已存放的元素个数
实现原理&使用细节
初始化
//static 关键字标识,所有对象公用,省内存
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//初始化一个空的数组,在第一次add()时才初始化 elementData
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//预知大数据时指定初始化容量,减少扩容次数
public ArrayList(int initialCapacity) {
...
this.elementData = new Object[initialCapacity];
}
- 延迟初始化的思想,大部分有数组的数据结构,在第一次添加操作时才初始化,分配内存
例:HashMap StringBuffer ThreadLocal - 避免频繁扩容影响性能,知道预期数量则可以指定
//构造函数如下
public ArrayList(int initialCapacity) //LinkedList不是数组就没有
public HashMap(int initialCapacity)
public StringBuffer(int capacity)
扩容数据
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
//1.5倍扩容 10->15->22->33
int newCapacity = oldCapacity + (oldCapacity >> 1);
...
elementData = Arrays.copyOf(elementData, newCapacity);
}
//最终调用 System 类底层方法,浅拷贝数据
public static native void arraycopy(Object src, int srcPos,Object dest, int destPos,int length);
- Arrays.copyOf 性能比for循环逐个赋值高
- 最终调用 System 类 arraycopy() C实现方法,浅拷贝数据
批量删除
private boolean batchRemove(Collection<?> c, boolean complement) {
...
try {
for (; r < size; r++)
//内层循环性能关键点,基于Hash查找的HashSet contains() 方法比 List快
if (c.contains(elementData[r]) == complement)
//核心操作数据,jdk美妙之处
elementData[w++] = elementData[r];
} finally {
...
}
return modified;
}
//1.8 lambda 删除方式
public boolean removeIf(Predicate<? super E> filter) {
final BitSet removeSet = new BitSet(size);
for (int i=0; i < size; i++)
if (filter.test(element)) {
removeSet.set(i);
}
}
- 采用 BitSet 记录需删除索引位,因为采用的long(64 bit位)作为数据结构,最优情况省64倍内存
- 类似于 redis 的 bitmap,和 Guava 包的 BloomFilter 也有关联
序列化
transient Object[] elementData;
- 因为数据可能没有全部填充数组,使用transient关键字,防止自动序列化属性
private void writeObject(java.io.ObjectOutputStream s){
...
//结束位为size,省 内存|磁盘空间|带宽
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
...
}
private void readObject(java.io.ObjectInputStream s){
for (int i=0; i<size; i++) {
//数据还原
elementData[i] = s.readObject();
}
}
}
并发异常
ConcurrentModificationException
* @see Collection
* @see Iterator
* @see Spliterator
* @see ListIterator
* @see Vector
* @see LinkedList
* @see HashSet
* @see Hashtable
* @see TreeMap
* @see AbstractList
* it is not generally permissible for one thread to modify a Collection
* while another thread is iterating over it.
* In general, the results of the iteration are undefined under these circumstances
- 我发现java Doc,有必要翻译着看一眼
- 一个线程在修改Collection,而另一个线程正在迭代它。通常,在这些情况下,迭代的结果是不确定的
- fail-fast 快速失败思想,如果在使用的数据可能不准确,直接抛出异常
//涉及到修改 elementData 的方法执行 modCount++;
public boolean add(E e)
public E remove(int index)
public void replaceAll(UnaryOperator<E> operator)
public void sort(Comparator<? super E> c)
//涉及遍历的方法校验 modCount 值
public void forEach(Consumer<? super E> action) {
//遍历前记录修改次数
final int expectedModCount = modCount;
for (int i=0; modCount == expectedModCount && i < size; i++) {
...
}
//发现和预期值不同则抛出异常
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
public boolean removeIf(Predicate<? super E> filter)
Itr.next()
- 在存在并发的情况下,不需要冒险,采用并发容器
并发 List
Collections#synchronizedList() & Vector
- 优:SynchronizedList有兼容功能,可以将List的子类转成线程安全的类
劣:SynchronizedList,进行遍历时要手动进行同步处理
CopyOnWriteArrayList
- 适合多读少写的场景,读弱一致性,读用volatile无锁方式,写用 ReentrantLock加锁 copy 新的数组
排序 TimSort
public void sort(Comparator<? super E> c) {
...
//最终调用 TimSort.sort() ,组合 + 插入 排序
Arrays.sort((E[]) elementData, 0, size, c);
}
//从小到大排列
ArrayList<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3));
list.sort(Integer::compareTo);
总结
- 技术本质是实现动态数组的 CRUD
- 在实际撸码中,注意初始化指定容量大小提升性能,是线程不安全即可
