

逻辑回归
emmmm.....先来首音乐 Album Soon
线性回归
在统计学中,线性回归(英语:linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归(multivariate linear regression),线性回归是机器学习中最简单的模型了。
线性回归的定义这样:对于一个样本,它的输出值是其特征值的线性组合(这个是假设前提)。那么对数据进行建模得到的模型如下:
通过对抽样得到的数据集进行训练,使得目标函数和真是的函数接近(拟合方程),一般采用的是最小二乘法。(由很多的方法可以用来求解最优解的参数。。。。这是另外的问题。。。)
逻辑回归
逻辑回归是一种非线性的回归函数,它和线性回归一样,是机器学习中最常用的算法,线性回归主要用于预测(建模预测),二逻辑回归主要用与二分类,两者都是有监督的机器学习。(其实分类也是预测的一种特殊的例子)。
逻辑回归给出的是属于一个类的概率(0-1),通过一个非线性函数,将输入映射到[0,1]上, ,这样通过该模型就可以进行分类。一般采用的
函数是
函数:
。通过该函数,将输出数值映射成概率,完成
的作用。
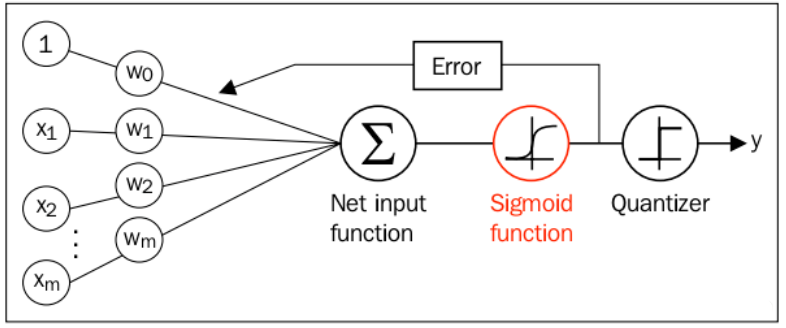
目标函数有了之后,如何构建损失函数来优化该模型?采用 MSE的方式,损失函数如下:
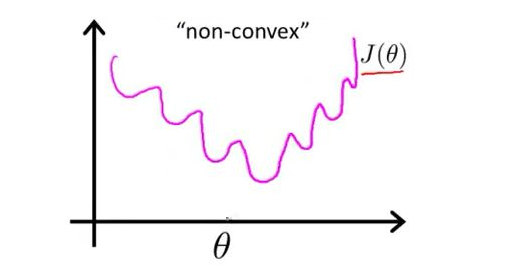
但是其函数如下,可见它是“non-convex”的,这样优化的时候会陷入局部最优解。因此,需要寻求另外的损失函数。
考虑到 sigmod函数本身表示的就是属于某个类的概率,因此有:
因此,可以写成以下的形式:
(
只取值0和1).
这样一来,可以采用数理统计的思维来求解参数。对于训练数据,根据最大似然的原理,需要有
对于batch(m个数据)中的数据则是:
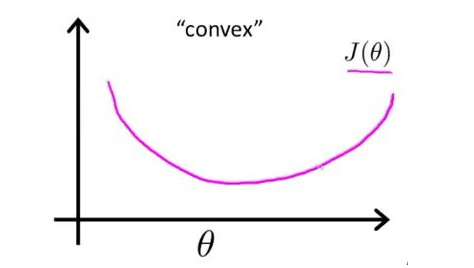
其对应的函是一个凸函数,因此不会陷入局部最优解中。
从这里可以知道,交叉熵(逻辑回归激活)的本质其实是最大似然。
(困惑的地方?)
其实这里的的y表示的是的概率。。这样的话,其他的就可以理解通了。
最大似然和最大后验概率
概率 : 概率研究的是,已经知道了模型和参数后,给出一个事件发生的概率。概率是一种确定性的东西,是一种理想值,当实验次数趋近无穷的时候,频率等于概率。“频率学派”就是认为世界是确定的,建模时候参数是一个确定的值,因此他们的观点是直接的对时间本身进行建模,频率学派认为模型中的参数是一个确定的值,对该数值的估算一般采用的是最大似然方法(MLE,最大似然估计)。
统计 : 统计是根据给出的观测数据,利用这些数据进行建模和参数的预测。通俗的说法就是根据观测的数据,得到对应的模型以及模型的描述参数等(例如推测是一个高斯模型,以及得到该模型的具体的参数,等)。
似然函数与概率函数 : 对于函数,有一下的两种情况:
- 如果
保持不变,
是变量的话,此时的函数称为概率函数,表示的是
- 如果
- 注意区分
是条件概率和似然函数的情况,
和
的关系是,当
;而当
.同时,对于
贝叶斯公式 :
该式子表示的是在事件B已经发生的时候,事件A的置信度。其中的表示的是A的先验概率。。。也就是事件A独立的置信度。贝叶斯学派的思想认为,世界是不确定的,因此先假设有一个预估(先验概率),然后根据观测数据,不断调整之前的预估。通俗的讲就是,对事件进行建模的时候,不认为模型的参数
是一个确定的值,而是认为参数
本身也服从某种潜在分布(因此先验概率的假设和选取很重要!!)。贝叶斯学派的参数估算方法是最大后验概率。 具体的形式如下:
最大化后验概率的时候,由于是已经知道的(这是一个固定的值,观测到的),因此,最大化后验概率其实就是
此时可见,后验概率受到两个部分的影响,和
,前者类似于似然函数,后者是参数的先验分布。当假设先验分布是1的时候,此时的后验概率和似然函数就等价了。
最大后验概率和最大似然函数的区别:
这两者的区别,其实就是对于参数的理解不一样,最大化后验概率的思想是该参数本身就服从某种潜在的分布,是需要考虑的,而似然函数则认为该参数是一个固定的值,不是某种随机变量。后验概率的本质是
,而
可能只是个意外??刚好,可以写成
??很神奇。。。反正最大化后验概率的本质是将
也看成随机变量来考虑,此时是一种带有惩罚项的似然函数。
