

对于数据库的CRUD操作而言,当并发量较大时会出现读或者写的瓶颈。对于大多数场景而言,都是读多写少,因此读更容易成为数据库的瓶颈。而缓存就是为了解决读的问题而出现的。缓存的数据存储在内存中,因此性能很高。
缓存更新方案
缓存的更新方式从大的方向分可以分为同步更新缓存和异步更新缓存
同步更新缓存
同步更新缓存就是写数据或者读数据的时候同步更新缓存。
读的时候更新缓存
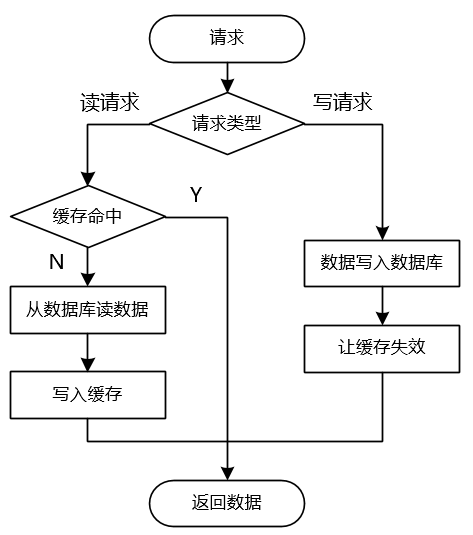
读的时候更新缓存策略很简单,如上图所示,主要有以下几个步骤:
- 读请求时,如果缓存数据存在则直接返回该数据;
- 读请求时,如果缓存数据不存在则从数据库中读入数据并写入缓存,然后返回数据;
- 写请求时,写入数据库成功后,删除缓存
写的时候更新缓存
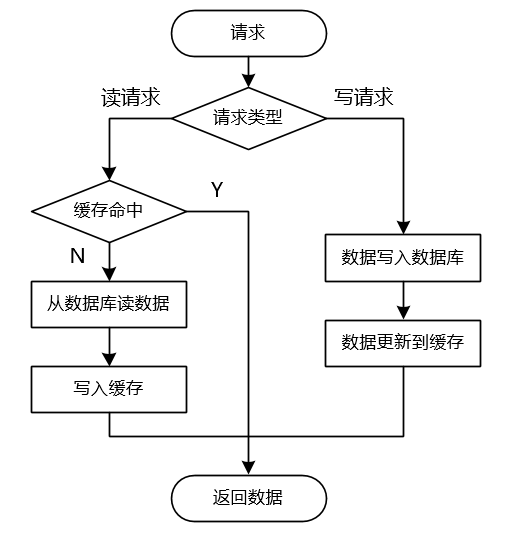
写的时候更新缓存与读的时候更新缓存原理类似,只是在写数据时候会先写数据库,然后写缓存,而不是删除缓存。
接下来我们对比一下这两种方式的优缺点。
读的时候更新缓存在数据写入数据库后只需要删除缓存即可,操作比较简单,因此逻辑上会简单一些,这种方式是最常见的缓存更新方式。但是读请求的时候要先读数据库然后写入缓存,如果是一个影响很大的更新,那么缓存失效后的第一次读请求可能会比较慢。比如常见的好友列表,如果缓存失效,需要从数据库先从关系链表查好友的关系链,然后去用户表查每个好友的头像和昵称,最后将数据还要写入缓存,这个过程可能会比较耗时。
而写的时候更新缓存,只需要将同样的更新数据先写入数据库,然后写一遍缓存,不用从数据库中取出来然后写入缓存。不过使用这种方式的时候,读请求的时查询缓存没有命中,然后查数据库的逻辑不能省,因为缓存还会因为过期而失效。
这两种方式都有一个问题,写请求时写入数据库成功,然后同步写入缓存或者删除缓存这两个动作都可能失败,如果失败就会导致数据库中的数据与缓存中的数据不一致。首先,可以采取重试的策略来尽可能减小出现的概率,而且尽量要给缓存设置一个过期时间,这样可以使缓存中的数据与数据库中的数据达到最终一致性。
异步更新缓存
同步更新缓存需要在业务逻辑里单独处理这一段逻辑,而其本身与业务逻辑是不相关的,我们只能为了提升性能而引入了缓存系统。因此可以考虑通过异步的方式更新缓存,将缓存更新的服务与业务服务进行解耦。而且异步更新的方式,将缓存更新的操作单独用一个服务来实现,因此读写请求减少了缓存更新的逻辑,性能会得到提升。
先写DB,异步MQ更新缓存
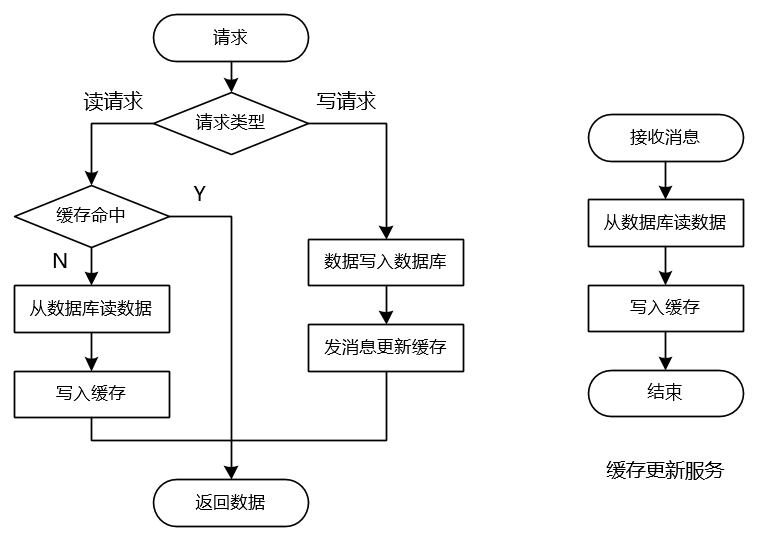
一个简单的异步缓存更新方案入上图所示,写请求写完数据库后会抛一个MQ消息,然后有一个独立的缓存更新服务区接受这个消息,然后从数据库读数据并写入缓存。采用异步的方案以后,数据无需同步写入,减轻了业务服务的逻辑任务,在业务场景下可能很多个地方都需要更新缓存,采用异步更新发消息很方便。不过这里需要依赖中间件消息队列,需要消息队列能保证不丢消息。缓存更新服务中也会存在缓存更新失败的情况,不过我们可以采用不断重试的方案来避免这样的问题。
但是上面这个设计会有一些问题,主要是在并发情况下。
问题1:如果先有一个写请求更新了数据库的数据,然后抛出一条MQ消息。但是在这个MQ消息被处理前,这时候一条读请求被发起了,那么这个时候读请求会读到缓存中的旧数据。
问题2:如果先有一个写请求更新了数据库的数据,并抛消息MQ1。然后接着有另一个写请求紧跟着也更新了数据,并抛消息MQ2。如果MQ1和MQ2串行执行,那么就没有问题。但是分布式环境下,服务是多机多进程部署,因此MQ2可能比MQ1先被处理。考虑这种极端条件下,如果第二次写请求前,MQ1的消息已经到达缓存更新服务并从数据库中取出消息。就在这时,MQ2消息到达被另一个进程处理,从数据库中取出数据并先于MQ1消息更新了缓存,然后这时MQ1消息取出的数据写入缓存就覆盖了MQ2消息的更新的数据。这时候缓存中的数据也与数据库中的数据不一致了。
如果对缓存中的数据与数据库中的数据的一致性要求非常高,可以引入脏标和版本号的机制来实现。如果完全不能接受缓存中数据与数据库数据不一致,就不要使用缓存。
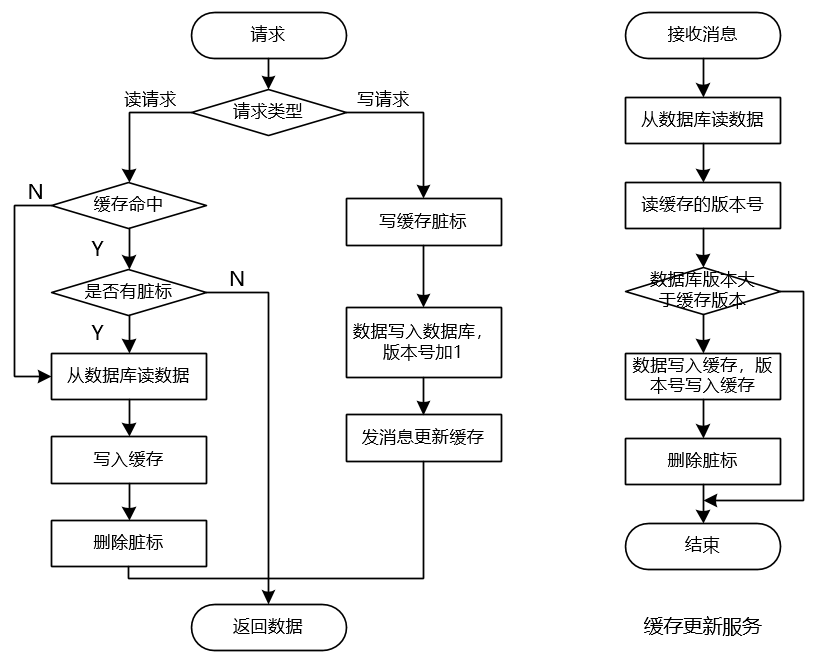
- 在更新数据到数据库之前先写一个脏标来标识缓存中的数据是脏的。脏标是用来解决问题1的。如果写脏标失败,则本次请求失败。如果写脏标成功,但是写数据库失败,本次请求也失败,这会导致缓存失效,下次读请求时发现缓存中的数据是脏数据,然后去读数据库。脏标写成功,数据也写成功,但是发消息失败,则由下一次读请求来更新缓存。为了避免脏标删除失败而导致缓存雪崩,最好给脏标设置一个过期时间。
- 给每一条数据都维护一个版本号,每次更新数据库都将版本号加1。版本号是用来解决问题2的。更新缓存之前先判断缓存中数据的版本号与数据库中数据的版本号,如果将要写入缓存中的数据的版本号大于缓存中数据的版本号则说明要更新的数据更新,此时更新缓存。如果数据库中数据的版本号小于缓存中数据的版本号则说明要更新的数据比缓存中的数据更旧或者数据相同,此时不更新缓存。
- 基于版本号的更新可以用redis的lua脚本来实现原子性
local cache_info = redis.call('GET', KEYS[1])
local cache_version = redis.call('GET', KEYS[2])
if(type(cache_version) ~= 'string' or
type(cache_info) ~= 'string' or
tonumber(cache_version) < tonumber(ARGV[1]))
then
redis.call('SET', KEYS[2], ARGV[1], 'EX', ARGV[3])
return redis.call('SET', KEYS[1], ARGV[2], 'EX', ARGV[3])
else
return 0
end
ps:KEYS[1]是缓存数据的key,KEYS[2]是版本号的key,ARGV[1]是更新后的缓存数据,ARGV[2]是更新后的版本号,ARGV[3]是key的过期时间。
先写缓存,异步将脏数据刷到数据库
先写缓存然后异步将数据刷到数据库的方法与操作系统的文件系统的读写核心流程是相同的。对于操作系统的文件系统,由于内存操作与磁盘操作存在百万数量级的差别,因此操作系统的文件系统维护了一个高速缓存区来减小这种巨大差距带来的影响。文件系统读操作时,先查询高速缓存区是否存在数据,如果没有则从磁盘读入高速缓存区。写数据时,将数据写入高速缓存区,系统调用write就返回成功了。然后通过一个名为update的后台进程,不断的调用sync将高速缓存区的内容写入磁盘。
先写缓存,然后异步将数据刷到数据库的方案流程图如下:
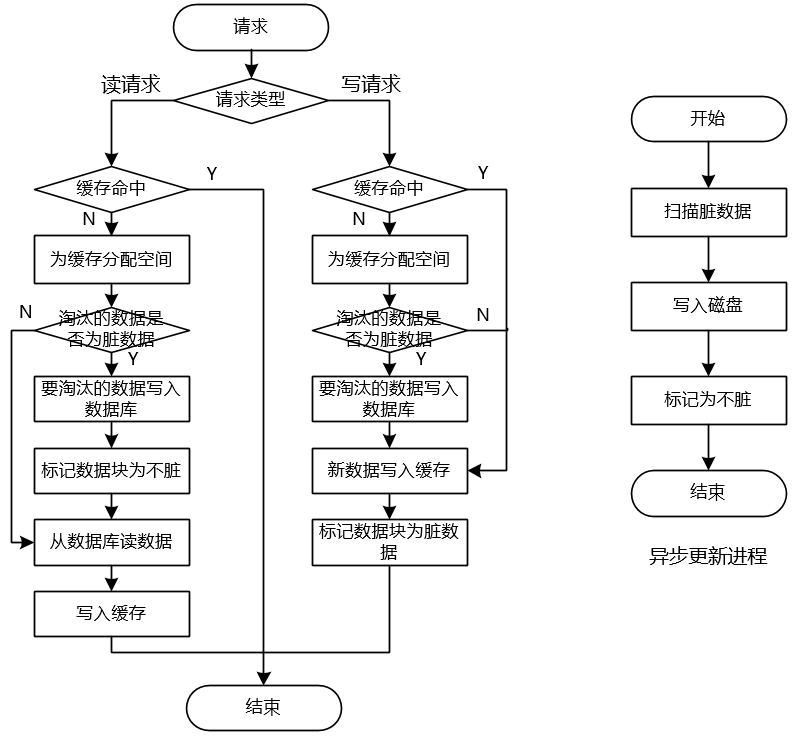
该方案的好处是,读写都是走缓存,因此数据极快,可以应对极高的并发请求。不过这种方案会导致缓存中数据与数据库中数据存在不一致的时间段,更为严重的是如果机器宕机,还没写入数据库的脏数据会丢失。如果要避免数据丢失,还可以使用双缓存的方案,不过这有会是系统更加复杂,维护一致性更加困难。
缓存中存在常见问题
缓存穿透
一般情况下查询数据,数据都是存在的。大部分业务系统都需要给用户创建一个账户,如果一个新用户去查询用户信息,数据库中不存在这个用户的信息,会返回该用户是一个新用户。正常情况下,这样没有问题。如果有人利用这个漏洞,用这种新用户的账号,不断请求用户系统的接口,那么每次查询缓存时都无法命中,导致请求都打到DB上,会DB带来很大的压力,甚至宕机。
像这种查询缓存中压根不存在的数据,使请求落到DB上的情况,被称为缓存穿透。
对于缓存穿透常用解决方案有两个:缓存空值和布隆过滤器
缓存空值
缓存空值的方法,正如其名,当查询到数据不存在时,向缓存的key中写入null。那么当一个新用户请求时,会先查询缓存,查询到缓存的KEY存在只是值为null,那么可以判定这是一个新用户。很多时候缓存用户信息时,会将用户信息序列化后,再存入string。如果用户不存在,则将UUID为null的对象序列化后存入string。查询时,反序列化后判断用户的UUID是否为0,为0则表示是缓存的空值。
布隆过滤器
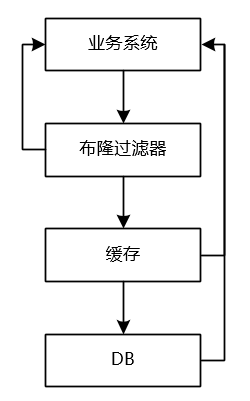
第二种方案是在前一种方案之前再加一层布隆过滤器,因此,如果布隆过滤器能命中,则查缓存,如果布隆过滤器没有命中,则直接返回。布隆过滤器的特点是如果数据存在则布隆过滤器一定会命中,如果数据不存在则布隆过滤器绝大多数情况下不会被命中。因此,即使有部分不存在的数据通过了布隆过滤器的过滤,还是会被空值缓存拦截住。
第二种方案是在第一种方案的基础上形成的,因此第二种方案会复杂一些,但是如果缓存大量的空值,会占用大量的存储空间,而布隆过滤器可以花费很少的空间就过滤掉大量的无效请求。因此,如果为null的key的数量不是很多,直接用第一种方法即可,反之,如果为null的key的数量很多,则建议加一层布隆过滤器。
第二种方案与第一种方案相比还有一个优势,缓存空值还是会查询一次DB,如果同一时间内有大量的新用户同时请求,那么DB同样会存在峰值压力,而布隆过滤器则不存在这样的问题。
缓存洞穿
在高并发下,当缓存数据失效的一瞬间,这时所有的请求都会发现查询缓存不存在,因此都会去查询DB,造成DB瞬时QPS陡增,这就是缓存洞穿。
防止缓存洞穿的方法是当发现缓存失效时,在查询DB之前先加锁,这样第一个取到锁的线程更新缓存,其他线程因为取不到锁会等待。等到一个线程更新缓存成功后,其他线程就可以从缓存中查询信息了。
缓存雪崩
缓存雪崩是指同一时间缓存大规模失效,导致请求都直接打到DB上,瞬间的流量将DB打挂,导致整个系统崩溃,这种情况就是缓存雪崩。比如缓存机器宕机或者重启时都可能导致缓存雪崩。
对于缓存雪崩首先采用缓存集群的方案来增加容错性,如果使用redis做缓存,可以使用主从+哨兵的部署来方案来提高可用性,避免缓存大量失效的问题发生。不过即使使用了主从+哨兵的方案,在redis进行failover的过程中,redis的查询还是会失败。所以限流还是要做的。
对于微服务架构,雪崩已经发生的情况,可以使用开源的Hystrix实现降级和限流,避免DB宕机。但是Hystrix不具备很好的通用性,对于spring cloud可以比较方便的使用,对于其他语言下该怎么做呢?微服务治理的新趋势是使用server mesh,通过server mesh解放了业务系统,业务侧只需要专注于业务逻辑的实现,诸如限流,熔断等分布式系统中的弹力设计则交给server mesh来做。server mesh更加抽象,因此通用性会更强,是未来的趋势。
热点数据
如果一个数据同时会被大多数用户访问,导致大量的请求打到同一个KEY上,这个KEY就可以称为热点数据。如果TPS提升,热点数据很有可能首先成为瓶颈。
我们列举几条常见的热点数据场景:
[1] 热门新闻数据
新浪微博偶尔会因为热点事件的发生,导致某一条微博被很多用户在同一时间段内集中访问,这条微博就是一个热点数据。对于微博这种热点数据,最主要的防止手段在于如何自动发现热点数据。可以通过流式计算平台,统计微博的访问量,如果指定时间段内统计的访问量超过一定的阈值,则将该数据同步到配置中心(如zookeeper等)。发现热点数据后,需要对热点数据进行分KEY存储,存储到多个实例里,可以分摊查询的压力。
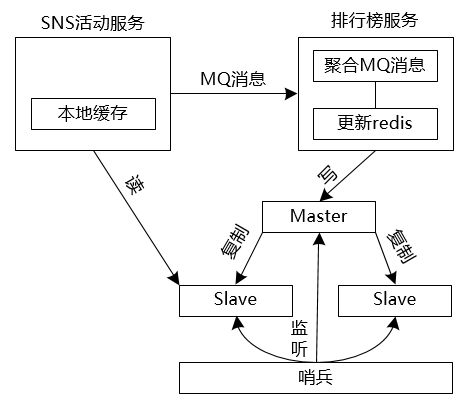
[2] 活动用户实时排行榜
这个场景来源于项目中遇到的场景需求,一个SNS页面活动,几个用户可以组一个战队,每个战队所有用户的积分加和就是战队的总积分,根据战队的总积分排名会决定战队瓜分奖金的大小。该项目需要能够实时展示每个战队的排名,我用ZSET来实现排名的功能。但是所有用户的行为都可能导致积分变化,会导致战队积分的变化,最终导致积分排行的变化。而且每个用户也会查询战队的排名,也都会查询这个KEY。因此,这个KEY通过面临着读和写的并发压力。
尽可能削减存储的数据。因为是做排名,因此很难分KEY,分KEY的话需要频繁的做数据转移。因此在排名的KEY中只存最少的信息,那就是用积分做score,用战队的ID做value,这样可以避免成为大KEY。
需求上进行限制。需求上限制排名只统计到前5万,超出该范围的直接显示5万+,因为超出这个范围时排名的意义已经不大。以score占4个字节,value占4个字节计算,1M空间的ZSET可以存10多万个值。因此5万个value不会成为大KEY。
异步解耦。将排名的更新用一个独立的服务来实现,用户更新积分后发消息给排名系统。这样消息队列可以削峰填谷,避免了更新热KEY时发生排队,导致所有接口被拖慢,甚至宕机。
聚合请求。同一时间段内到达的请求,可能是对同一个value进行修改score排名。因此,收到消息后不是立刻处理,而是继续收消息,如果两个消息更新同一个value,则新的消息完全可以覆盖旧的消息,则只需要更新一次。为了不让Redis空闲下来,聚合消息和写redis分两个线程分别进行。
本地缓存与读写分离。对排名的数据可以在本地内存再做一级缓存,减少redis的请求。同时redis查询进行读写分离,查询接口读从redis,写接口写主redis。
热点数据失效
大量热点缓存数据同时失效,导致大量请求直接打到DB上。对于热点数据同时失效的问题,可以在过期时间上,加上一个随机值,避免缓存同时失效。
大KEY
Redis大key是指一个key占用的空间过大,一般以万为单位的元素,以M为单位的数据占用。因为redis是单线程,一个key里的数据过大会导致网络磁盘占用较大,因此要避免大key。 大key的解决思路就是拆分了,将一个key,拆成多个小的key,根据某个属性值计算路由值,看应该访问哪个key。
总结
本篇文章,总结了自己对缓存知识的认识,介绍了四种常见的缓存方案,每种方案各有优劣,需要根据业务需求来选择合理的方案。然后介绍了使用缓存时可能遇到的几个问题,并总结了常见的解决方案。
