

前言
大家还记得上一篇《如何教妈妈学会数据准备》吗?这一期我们将试图教会妈妈级小白选手建立模型并进行调优。
在准备完毕的数据上,我们再添上「seed1」这一列,如下图所示。「seed1」列中的数值1表示该id是我们已知的目标用户,0表示不是我们的目标用户。
(注意:在这里我们略为粗暴地将未知特质用户全部打上了0标签,这是出于建模需要,希望读者能够与真实情景进行区分)。
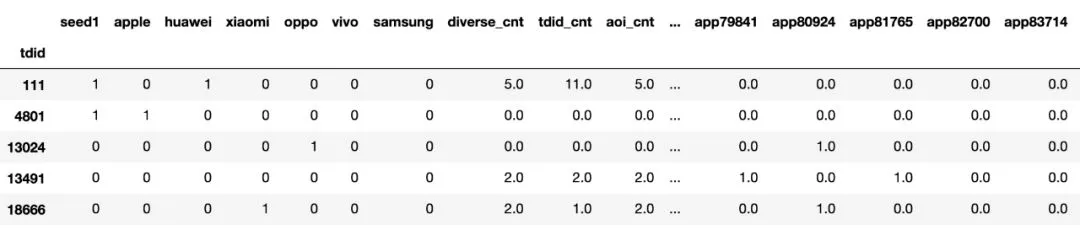 图:聚合数据的前5行示意
图:聚合数据的前5行示意
之后我们将用 XGBoost 开展建模。 XGBoost 被视为机器学习的一大利器,如果你还不了解它,就去看它的官方文档吧。这是关于 XGBoost 最好的介绍文档,简洁明了,图文并茂:https://xgboost.readthedocs.io/en/latest/index.html
我们需要对上述聚合数据进行切分,一份作为训练集,另一份作为测试集。
之所以要这样做,是为了防止过拟合。所谓的过拟合,即下面的左图。在过拟合时,训练所得的模型与样本数据几乎可以完全贴合。这样,模型就成为这一份样本数据的「量身定制」了,它只适用于这一份数据,泛化能力很差。
因此,为了防止出现左图的情形,我们从样本数据中抽出一部分(而不是全部)来做训练,得到模型后,再用另一部分数据来评估模型好坏。如果在训练集上得到的模型能够很好地对测试集进行预测,那么这就是一个令人满意的模型。
我们可以用以下语句实现数据集的拆分。
 图:拆分为训练集与测试集
图:拆分为训练集与测试集
训练模型
这个步骤听起来令人害怕,实际上只有一行。
01方法一 import xgboost
训练的核心语句是
1xgb.train(param, dtrain, num_round, evallist)括号中是我们填入的参数,分别是xgboost的超级参数、数据集、训练次数、评估结果。在赋值过程我们把设定赋予参数,然后运行训练语句即可。
1)超级参数。在实际运行的代码中,我们没有特意设置超级参数,而是选择了默认值(param = {})。读者可以参考官方文档进行超级参数的设定。

图:部分超级参数
2)数据集。之前我们已经切分好了数据集,但还不够。在这一步我们要把数据准备为 xgboost 可识别的 DMatrix 格式。
3)训练次数。
4)评估结果。用一些评估方法(如均方误差根rmse、auc等)对模型在训练集和测试集上的表现进行评价。
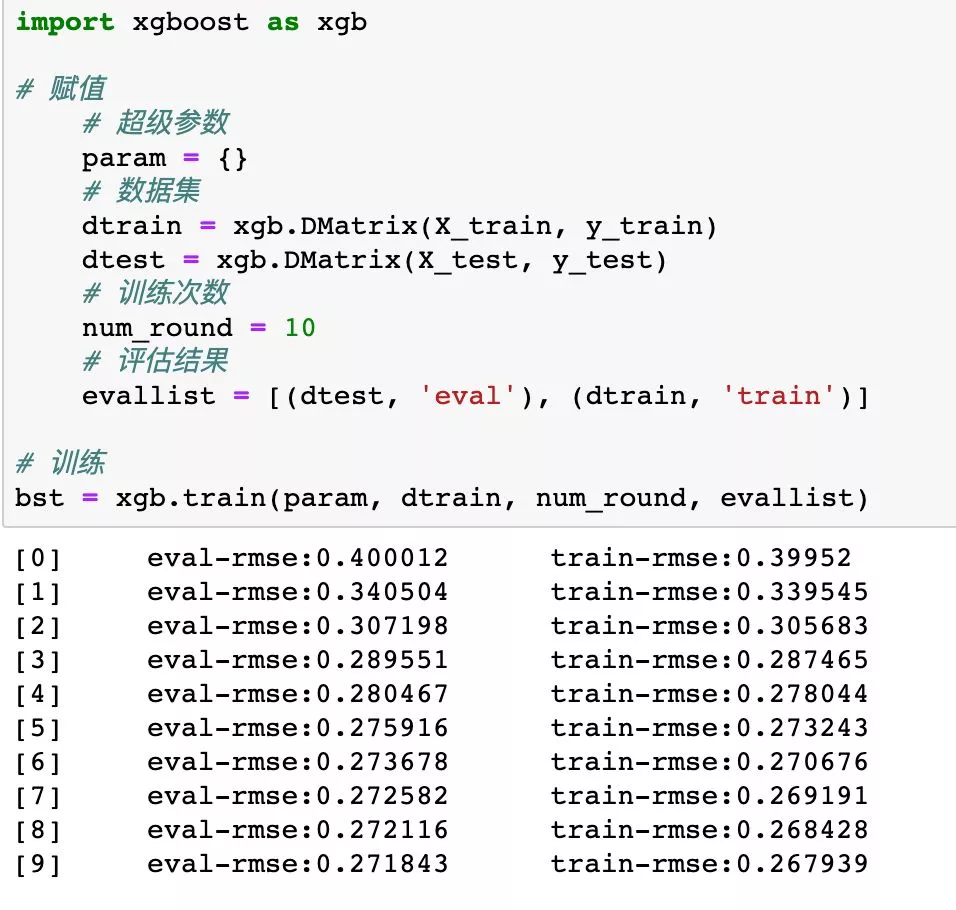
从上图可以看出,随着训练次数的增多,均方误差根rmse在下降,说明模型的表现在变好。
如果你对模型现在的效果足够满意,就可以用当前的模型进行预测了。这意味着我们的任务已经接近尾声!
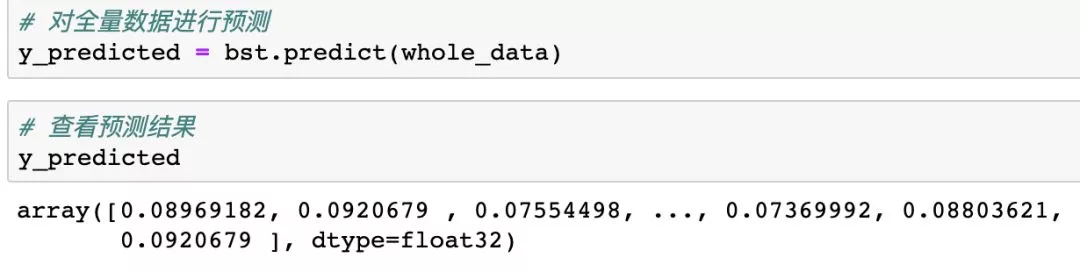 图:用训练完成的模型进行预测
图:用训练完成的模型进行预测
02方法二 from xgboost.sklearn import XGBClassifier
XGBClassifier是xgboost的sklearn包,同样的,方法二中的核心代码也只有一句:
1XGBClassifier().fit(X_train, y_train)在这里我们直接使用了默认设定,读者也可按照官方文档说明自行设定,参数跟方法一中大体一致,具体见下(感到眼花缭乱的现在可以跳过不看):
class xgboost.XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True, objective='binary:logistic', booster='gbtree', n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)
中文版参数详解:
https://blog.csdn.net/qq_36603091/article/details/80592157

图:训练模型
下图中的 bst 就是我们训练所得的模型,拿来预测就可以了。

虽然看起来已经完成了任务,但其实模型还有优化的空间,可以按照下文中的步骤调参。
好了!最后具体的调优就交给读者们自己完成。以上就是lookalike 任务的全部内容,下一期我们再见!
本文转自:TalkingData数据学堂
封面图来源于网络,如有侵权,请联系删除
