

安装 Python
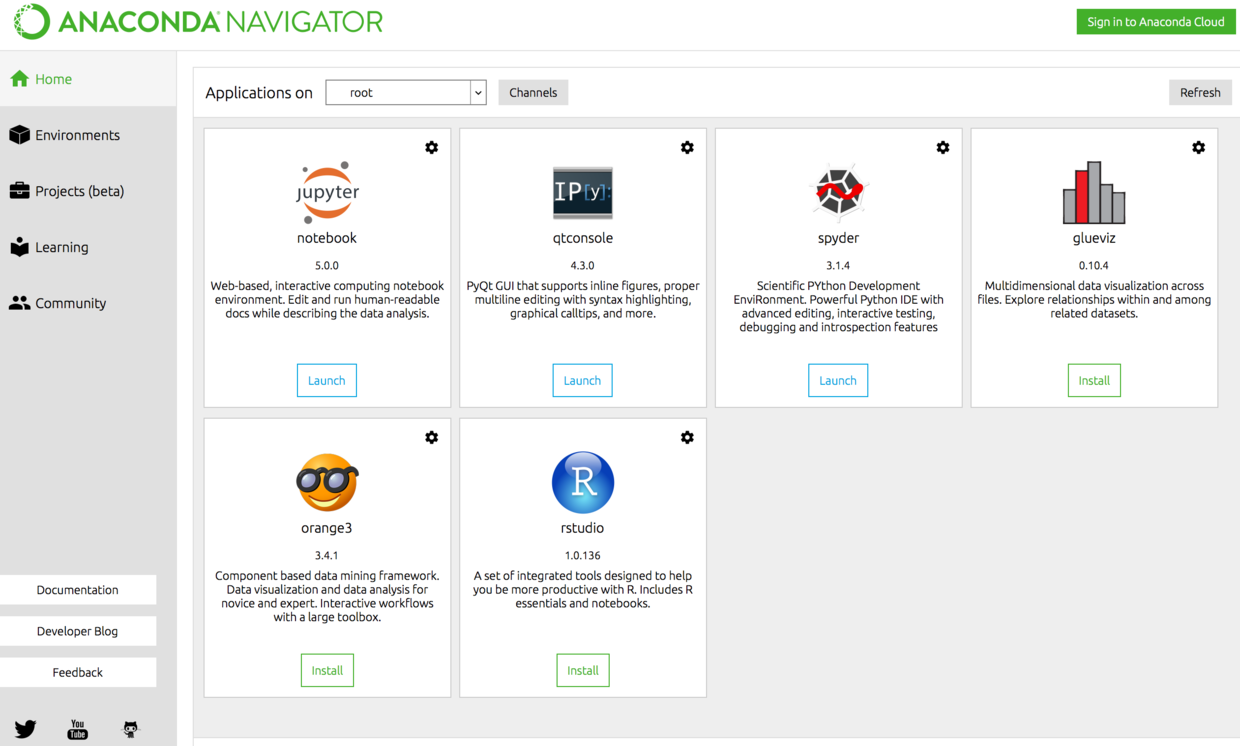
由 Python 提供支持的领先开放数据科学平台
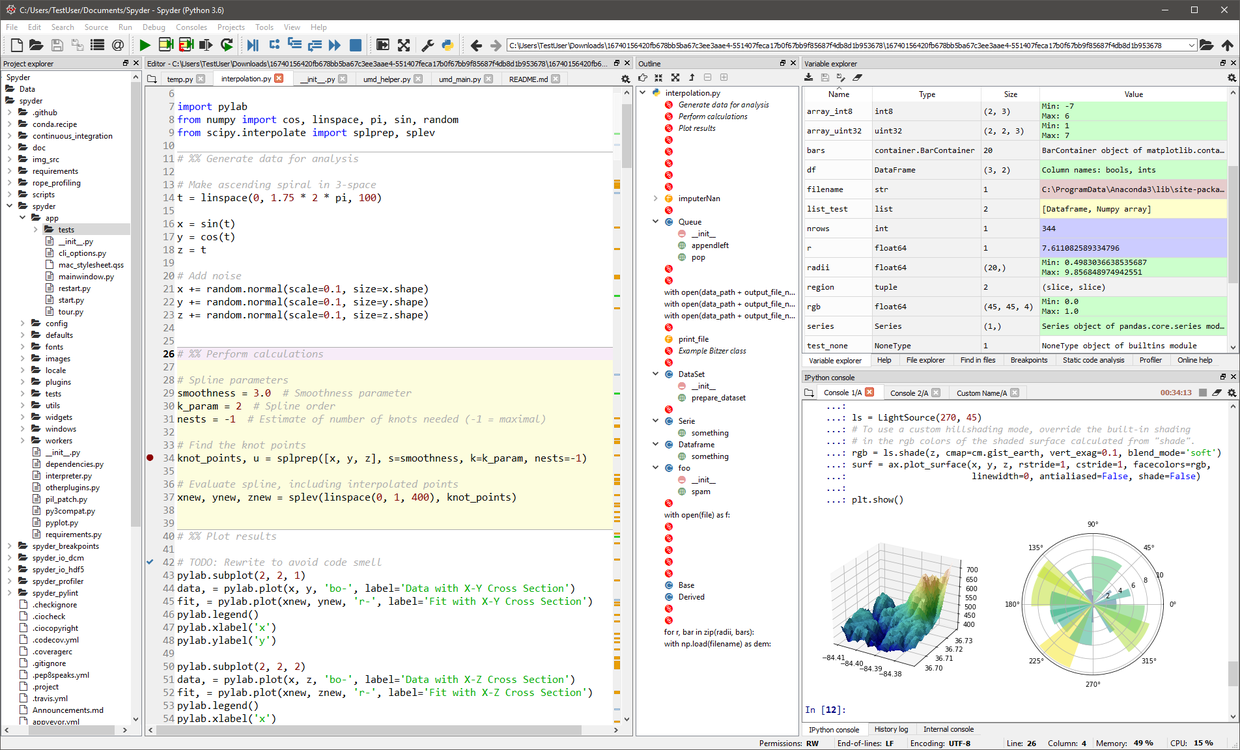
Anaconda 附带的免费 IDE
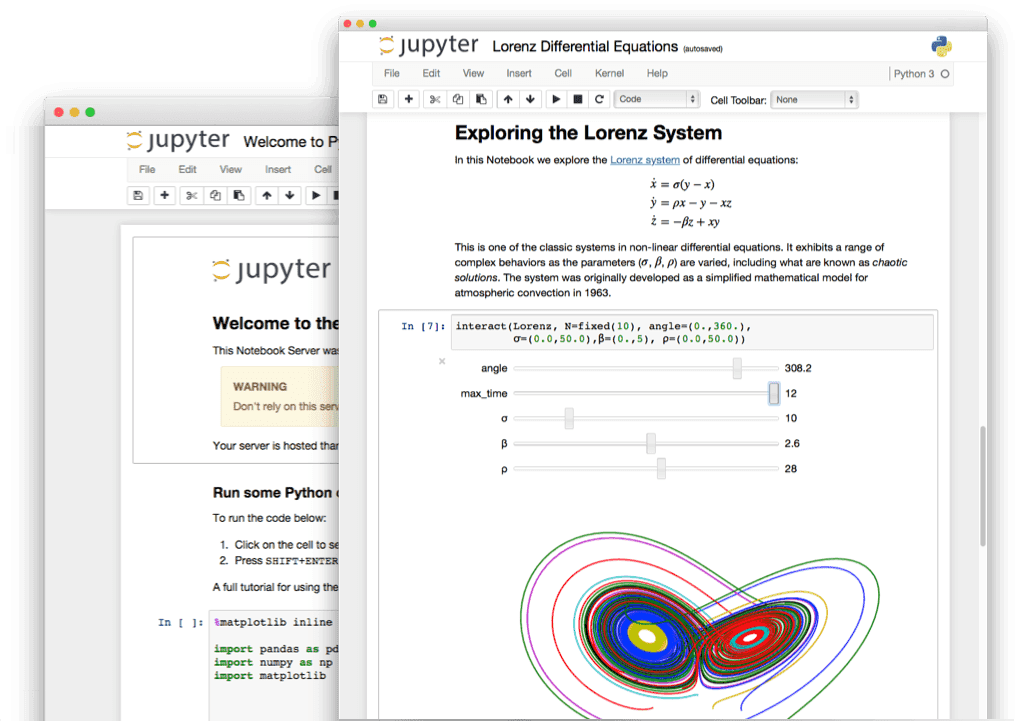
使用实时代码,可视化,文本创建和共享文档……
1. 变量和类型
变量赋值
x = 5
x
5
运算
x + 9 # 加
14
x - 9 # 减
-4
x * 9 # 乘
45
x ** 9 # 乘方
1953125
x % 9 # 取模
5
x / float(9) # 除
0.5555555555555556
类型与类型转换
| 类型转换 | 示例 | 类型 |
|---|---|---|
| str() | '59', '3.14', 'True' | 字符串 |
| int() | 5, 9 | 整型 |
| float() | 5.9, 3.14 | 浮点数 |
| bool() | True, True, True | 布尔 |
2. 字符串(String)
帮助
help(str)
zh_string = "最好的人工智能开发"
zh_string
'最好的人工智能开发'
字符串操作
zh_string * 2
'最好的人工智能开发最好的人工智能开发'
zh_string + '就在这里了'
'最好的人工智能开发就在这里了'
'我' in zh_string
False
字符串方法
zh_string.upper()
zh_string.lower()
zh_string.count('在')
zh_string.replace('在', ' is ')
zh_string.strip()
'最好的人工智能开发'
3. 列表(List)
a = '是'
b = '这'
zh_list = ['我', '列表', a, b]
zh_list2 = [[1, 3, 5, 7], [2, 4, 6, 8]]
元素选择
# 下标
zh_list[1] # 索引从 0 开始,这里取第 2 个元素
zh_list[-1] # 最后一个元素
'这'
# 分片
zh_list[1:3] # 索引 1, 2
zh_list[1:] # 索引 1 及之后
zh_list[:3] # 索引 3 之前
zh_list[:] # 所有 / 复制列表
['我', '列表', '是', '这']
# 子列表
zh_list + zh_list
zh_list * 2
['我', '列表', '是', '这', '我', '列表', '是', '这']
# 列表方法
zh_list = [1, 3, 5, 7]
zh_list.index(3) # 获取元素下标
zh_list.count(3) # 统计元素个数
zh_list.append(0) # 追加元素
zh_list.remove(0) # 移除元素
del(zh_list[:2]) # 删除前 2 个元素
zh_list.reverse() # 反转列表
zh_list.extend([2, 4, 6]) # 扩展列表
zh_list.pop(-1) # 弹出(移除并返回)指定 index 元素
zh_list.insert(3, 9) # 在 index 位置新增元素
zh_list.sort() # 排序列表
4. 库

导入库
import numpy
import numpy as np
选择性导入
from sklearn import datasets
5. Numpy 数组
zh_list = [1, 3, 5, 7]
zh_array = np.array(zh_list)
zh_2darray = np.array([[1, 3, 5, 7], [2, 4, 6, 8]])
Numpy 数组元素选择
# 下标
zh_list[0] # 索引从 0 开始
1
# 切片
zh_list[:2]
[1, 3]
# 2 维数组下标
zh_2darray[:, 1]
array([3, 4])
Numpy 数组操作
zh_array > 3
array([False, False, True, True])
zh_array * 2
array([ 2, 6, 10, 14])
zh_array + np.array([9, 8, 7, 6])
array([10, 11, 12, 13])
Numpy 数组函数
other_array = np.array([5, 5, 5, 5])
zh_array.shape # 维数
np.append(zh_array, other_array) # 追加数组
np.insert(zh_array, 1, 5) # 插入元素
np.delete(zh_array, [1]) # 删除元素
np.mean(zh_array) # 均值
np.median(zh_array) # 中位数
np.corrcoef(zh_array) # 相关系数
np.std(zh_array) # 标准差
2.23606797749979
