

本系列所有文章的代码都是用JavaScript实现,之所以用JavaScript实现是因为它可以直接在浏览器宿主中运行代码,即在浏览器中按f12打开控制台,选择console按钮,在下面空白的文本框把本例的代码黏贴上去回车即可运行。方便各位同学学习和调试。
一、前言
数组这个概念相信各位同学在日常写代码的时候肯定会经常用到,我们通常用数组作为容器来存储数据。基本上每一种编程语言都有这种数据结构,它是一个基础的数据结构,下面将仔细的讲解数组的原理及应用。
二、数组概念
什么是数组呢?按照专业的名词解释,数组是一种线性表数据结构,它用连续的内存空间来存储一组具有相同类型的数据。从定义里我们可以看到几个关键词,分别是线性表(Linear List)和连续的内存空间和相同类型的数据。
1.线性表
线性表的意思其实就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等都是线性表结构。而与线性表对立的则是非线性表 ,比如二叉树、图、堆等。之所以叫非线性,是因为非线性表中的数据并不是简单的前后关系。
2.连续的内存空间和相同类型的数据
当我们声明一个数组的时候,计算机就会为数组分配一个连续的内存空间。假如我们声明的数组长度是10,在数组中存储的元素都说int类型的数据,如果内存的首地址为1000,则计算机为数组分配了1000~1039的连续内存空间。数组和链表不同的一点就是数组存储的都是连续的内存空间,而链表存储的都说不连续的内存空间,所以如果一个计算机的内存只有1G的情况下,我们声明了一个占用1G内存的数组很有可能会导致内存溢出,因为有可能内存里有不连续的空间,而声明1G内存的链表则不会出现这种情况。
结合上面所说的两点,数组由于是线性的并且是连续的内存空间,随机访问的时候时间复杂度非常的快,为O(1)。数组的随机访问并不需要遍历本身,只需要知道下标就可以得出值。但是有利也有弊,与快速的查询相反的就是在插入和删除的时候所要耗费更多的复杂度。在这里需要提一点的是,数组是随机查找的时候时间复杂度为O(1),不能笼统的认为数组在执行查找操作的时候时间复杂度为O(1),如果你用二分查找来对数组进行查找操作,耗费的时间复杂度为O(logn)。
三、数组的插入和删除
上面提到数组由于连续的内存空间导致了在执行插入和删除操作的时候占用大量的性能。首先我们来说一下插入操作在数组的执行过程。
假设我们声明了一个数组长度为n,如果我们要插入的数组在数组第m个位置的时候,为了能够让数据成功的插入下标m当中,我们要把m到n这一部分的数据往后移一位,然后把数据放入下标m当中。那如果数据是要插入到数组最后面的话,那时间复杂度也只是O(1),如果是在开头插入的话时间复杂度则为O(n),因为每个位置的概率都是一样的,所以我们可以得到平均时间复杂度为: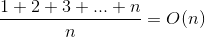 。
。
如果一个数组是有序的,我们为了保持数组的有序性,的确只能用上述的方法来解。但是如果数组是无序的,为了避免大规模的数据移动,我们可以把当前下标m的数据放到最后面,把我们的值放入到下标m当中。利用这个方法我们可以将时间复杂度降到O(1),性能将极大的提升。
同理在删除中,如果我们要删除下标为m的元素,为了内存的连续性,也需要把m到n后面的数据往前移,不然就不连续。删除的最好时间复杂度是O(1),即删除的是结尾的数据的时候。最坏时间复杂度则为O(n),即在开头的数据被删除。它的平均时间复杂度的公式也和上面插入的公式一样,结果为O(n)。
那么如果我们对数组进行频繁的删除操作,程序的性能将会极大的降低,有时候办法可以解决呢?这个时候我们可以借助JVM标记清除垃圾回收算法来实现。当执行删除操作的时候我们并不是真的把数组里的元素给删除掉,而是给该元素标记一个删除状态,等到后面数组没有更多的空间存储数组的时候再一次性的执行删除操作,极大地减少数据的迁移。下面用JavaScript代码来简单的实现一下:
var arr = new Array(10)
var count = 0
function insertArr(obj) {
if (typeof arr[9] === 'object') {
var tempArr = []
for (var a = 0; a < arr.length; a++) {
if (!arr[a].removeSign) {
arr[a].index = tempArr.length
arr[a].removeSign = false
tempArr.push(arr[a])
}
}
arr = tempArr
count = tempArr.length
if (arr.length === 10) {
console.error('数组越界')
return
}
}
arr[count] = {
value: obj.value,
removeSign: false,
index: count
}
count++
}
function removeArr(index){
if (arr.length === 0) {
console.error('数组长度为0,不能删除元素')
return
}
else if (index > arr.length) {
console.error('数组越界')
return
}
// 如果当前的已标记为true则查看下一个元素是否为true,如果不是则标记为true,是的话则继续递归
if (arr[index].removeSign) {
return removeArr(++index)
}
arr[index].removeSign = true
}这个代码的含义是声明一个长度为10的数组,存入的都是对象,对象里的value属性代表它的值,removeSign属性表示的是删除标志,为false的时候表示的是未删除,index属性表示的是下标。下面的一个测试用例表示在数组里存入10个数,然后删除其中三个,最后添加一个元素后得到长度为8的数组。整个程序在存入是数据大于数组长度的时候才会发生数组的删除操作。
for (let a = 0; a < 8; a++) {
insertArr({
value: a,
removeSign: false
})
}
removeArr(2)
insertArr({
value: 10,
removeSign: false
})
insertArr({
value: 11,
removeSign: false
})
removeArr(1)
removeArr(2)
removeArr(3)
insertArr({
value: 13,
removeSign: false
})四、数组越界
数组越界问题在不同的编程语言中会出现不一样的结果。就拿上面的JavaScript代码为例,由于JavaScript的数组是动态的,所以即使你声明一个长度为10的数组,你也可以给数组的第十一位赋值,之后数组的长度就会变成11。而像Java这种静态语言,本身就有对数组长度是否越界进行检查,当你给数组第十一位赋值的时候就会报数组越界的问题,而像C语言,情况则更复杂。下面写个代码来举例:
int main(int argc, char* argv[]){
int i = 0;
int arr[3] = {0};
for(; i<=3; i++){
arr[i] = 0;
printf("hello world\n");
}
return 0;
}
上面的这个代码在C语言环境中是无限循环输出hello world,为什么会出现这种情况呢?那是因为在 C 语言中,只要不是访问受限的内存,所有的内存空间都是可以自由访问的,函数体内的局部变量存在栈上,且是连续压栈。在Linux进程的内存布局中,栈区在高地址空间,从高向低增长。变量i和arr在相邻地址,且i比arr的地址大,所以arr越界正好访问到i。当然,前提是i和arr元素同类型,否则那段代码仍是未决行为。并且很多计算机病毒也正是利用到了代码中的数组越界可以访问非法地址的漏洞,来攻击系统,所以写代码的时候一定要警惕数组越界。
五、为何数组的下标都是从0开始
从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。上面说到,我们定义一个数组时,计算机会给每个内存单元分配一个地址,计算机通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址公式如下:
a[i]_address = base_address + i * data_type_size
其中 data_type_size 表示数组中每个元素的大小。如果用 a 来表示数组的首地址,a[0] 就是偏移为 0 的位置,也就是首地址,a[k] 就表示偏移 k 个 type_size 的位置,所以计算 a[k] 的内存地址只需要用这个公式:
a[k]_address = base_address + k * type_size
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k] 的内存地址就会变为:
a[k]_address = base_address + (k-1)*type_size
对比两个公式,我们不难发现,从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。不过其他编程语言不一定数组下标就是从0开始,比如MATLAB,而像python则可以负下标。
上面讲到的是一维数组的内存寻址公式,如果到一个m*n的二维数组,当它的下标i<m,j<n时,它的公式如下:
a[i][j]address = base_address + n * i * type_size + j * type_size = base_address + ( i * n + j) * type_size
同理a*b*c的三维数组,当它的下标i<a,j<b,k<c时,公式如下:
a[i][j][k]address = base_address + bc * i * type_sizze + c * j * type_size + k * type_size = base_address + (bc * i + c * j + k) * type_size
上一篇文章:数据结构与算法的重温之旅(二)——复杂度进阶分析
下一篇文章:数据结构与算法的重温之旅(四)——链表
