


前言
讲到索引,第一反应肯定是能提高查询效率。例如书的目录,想要查找某一章节,会先从目录中定位。如果没有目录,那么就需要将所有内容都看一遍才能找到。
索引的设计对程序的性能至关重要,若索引太少,对查询性能受影响;而如果索引太多,则会影响增/改/删等的性能。
知识点
MySQL中一般支持以下几种常见的索引:
- B+树索引
- 全文索引
- 哈希索引
我们今天重点来讲下B+树索引,以及为什么要用B+树来作为索引的数据结构。
B+树索引并不能直接找到具体的行,只是找到被查找行所在的页,然后DB通过把整页读入内存,再在内存中查找。
重温数据结构
1.1 哈希结构
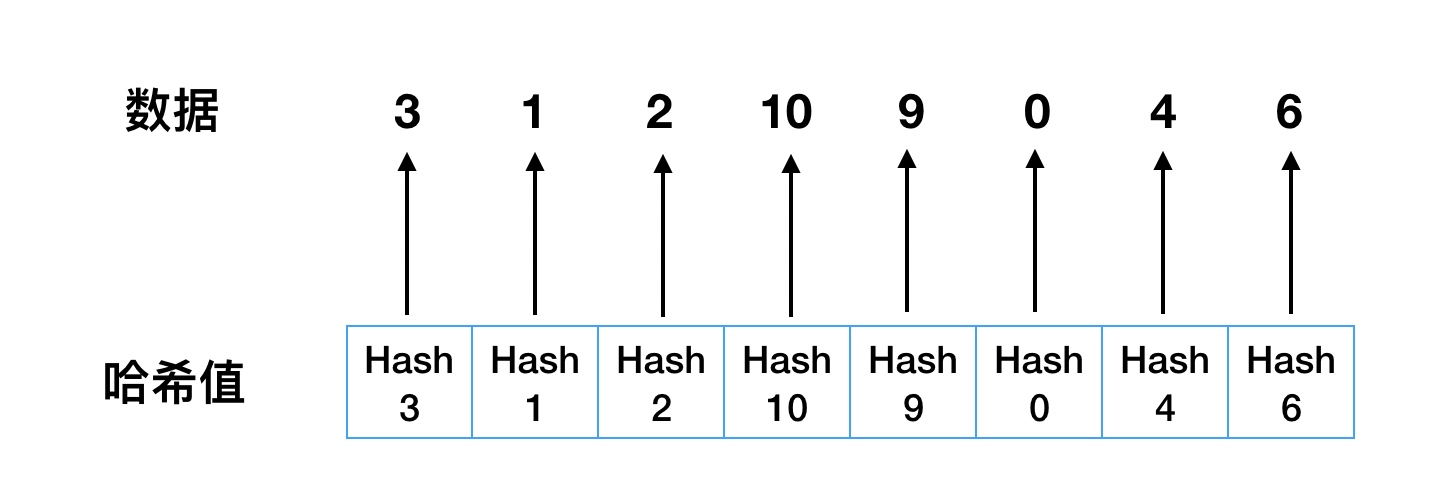
如有 3、1、2、10、9、0、4、6这8个数据,建立如图1-1所示哈希索引。
-
直接查询:现在要从8个数中查找6这条记录,只需要计算6的哈希值,便可快速定位记录,时间复杂度为O(1)。
-
范围查询:如果要进行范围查询(大于4的数据),那这个索引就完全没用了。
1.2 二叉树查找树
二叉树是一种经典的数据结构,要求左子树小于根节点,右子树大于根节点。
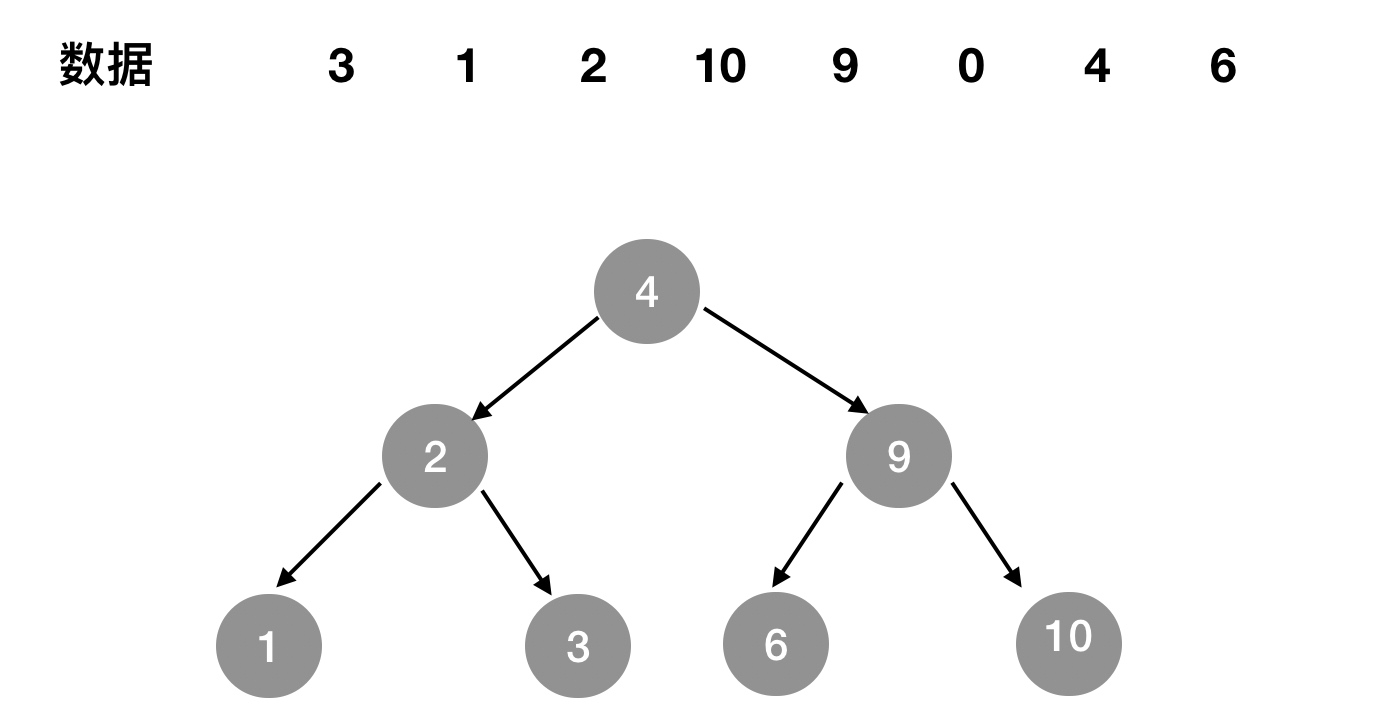
如有 3、1、2、10、9、0、4、6这8个数据,建立如图1-2所示二分查找树。
-
直接查询:假设查找键值为6的记录,先找到根4,4<6,因此查找4的右子树,找到9;9大于6,因此查找9的左子树;一共查找3次。但如果顺序查找,则需要查找8次(位于最后)。
-
范围查询:如果需要查找大于4的数据,则遍历4的右子树就行了。
1.3 平衡二叉树(AVL树)
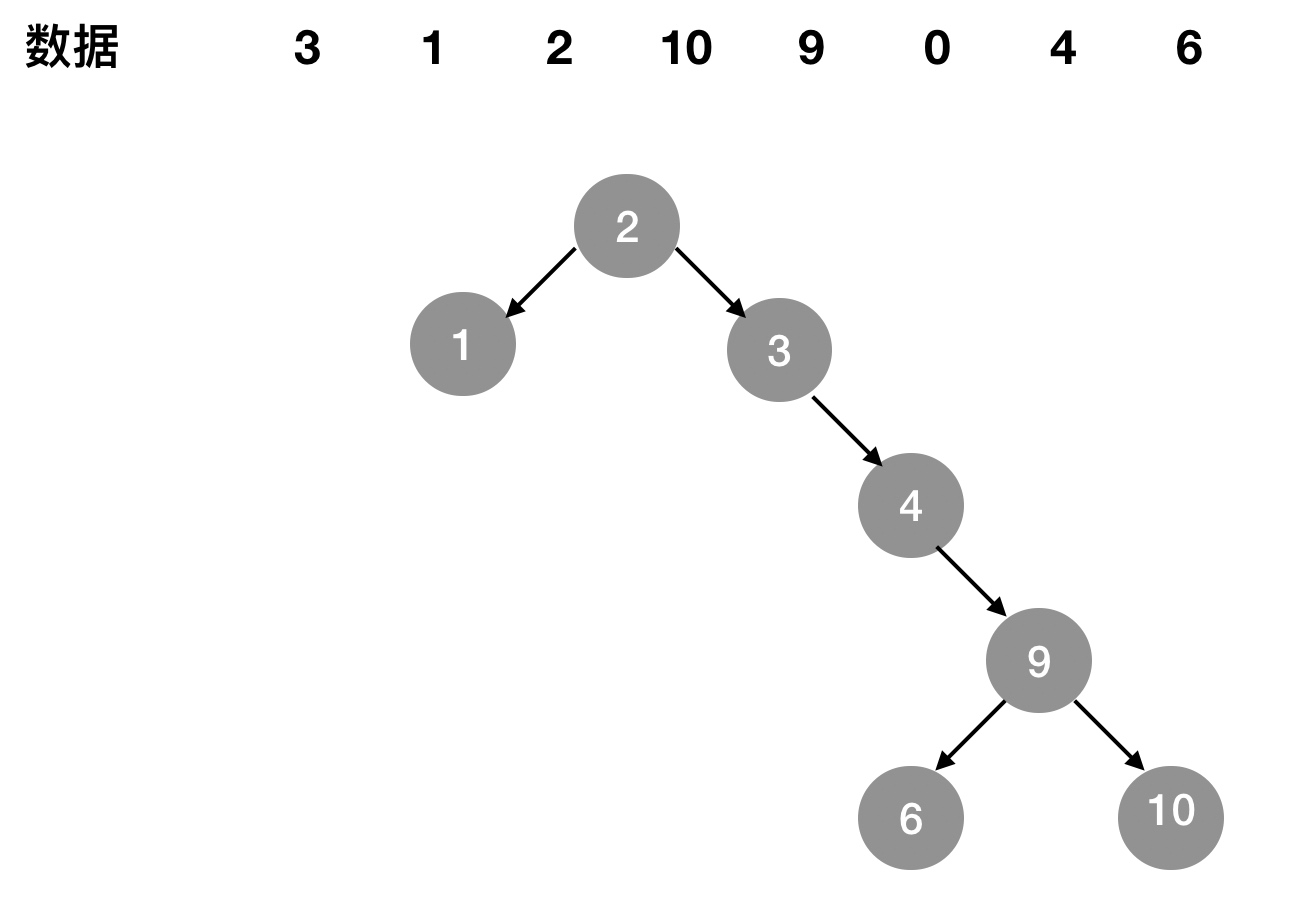
按照二叉查找树的定义,它是可以任意的构造,同样是这些数字,可以按照图1-3-1的方式来建立二叉查找树。同样查找数据6,需要查找5次。
因此为了最大性能地构造一个二叉查找树,需要它是平衡的,即平衡二叉树。
平衡二叉树定义:首先符合二叉查找树的定义,另外任何节点的两个子树高度最大差为1。
平衡二叉树的查询速度是很快的,但是有缺点:
- 维护树的代价是非常大,在进行插入或更新时,经常会需要多次左旋或右旋来维持平衡。如
图1-3-2所示 - 数据量多的时候,树会很高,需要多次I/O操作。
- 在进行范围查找时,假设查找>=3,先找到3,然后需要查找到3的父节点,然后遍历父节点的右子树。
1.4 B+ 树
在B+树中,所有记录节点存放在叶子节点上,且是顺序存放,由各叶子节点指针进行连接。如果从最左边的叶子节点开始顺序遍历,能得到所有键值的顺序排序。
如有 3、1、2、10、9、0、4、6这8个数据,可建立如图1-4-1所示高度为2的B+树。
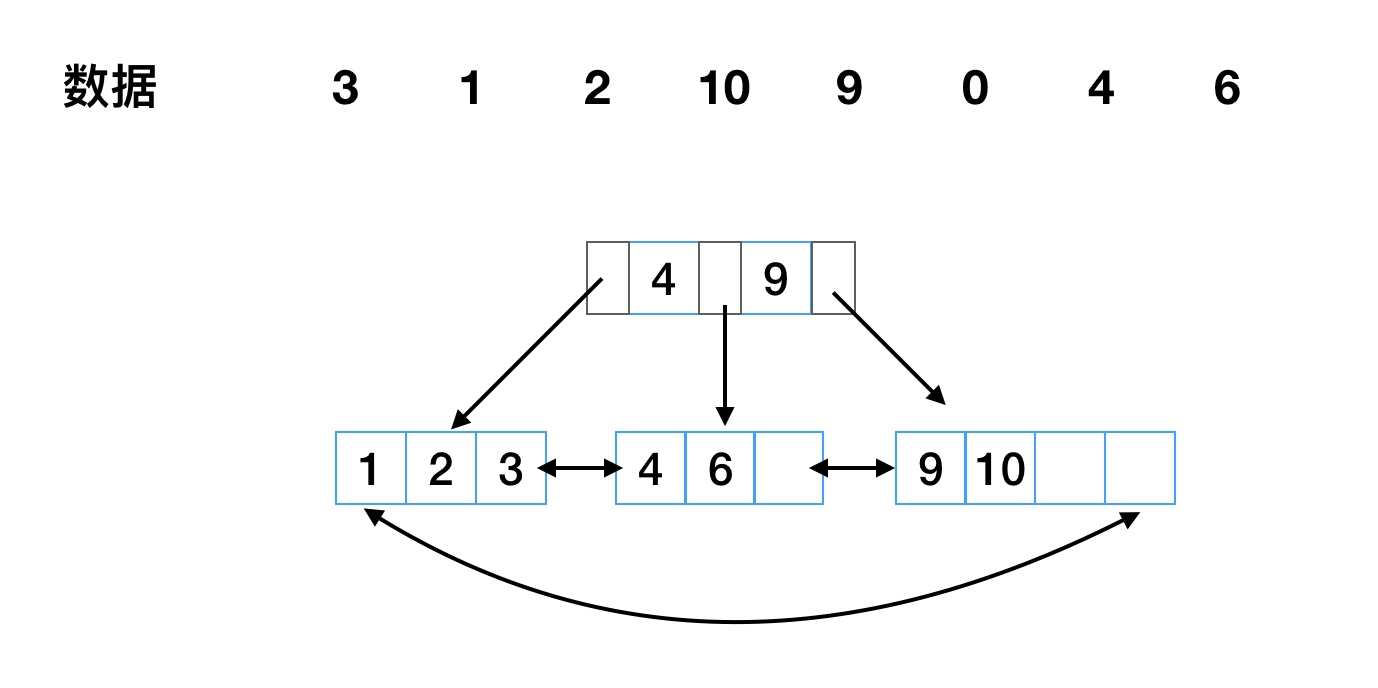
在进行更新时,B+树同样需要类似二叉树的旋转操作。举例,假设新增一个7,那可以直接填充到4、6的后面。如果再添加8,那么就需要进行旋转了,感受下面的B+树旋转过程。
采用B+树的索引结构优点:
- B+树的高度一般为2-4层,所以查找记录时最多只需要2-4次IO,相对二叉平衡树已经大大降低了。
- 范围查找时,能通过叶子节点的指针获取数据。例如查找大于等于3的数据,当在叶子节点中查到3时,通过3的尾指针便能获取所有数据,而不需要再像二叉树一样再获取到3的父节点。

未完待续…
如果想要实时关注更新的文章以及分享的干货,可以关注我的公众号

