集合体系
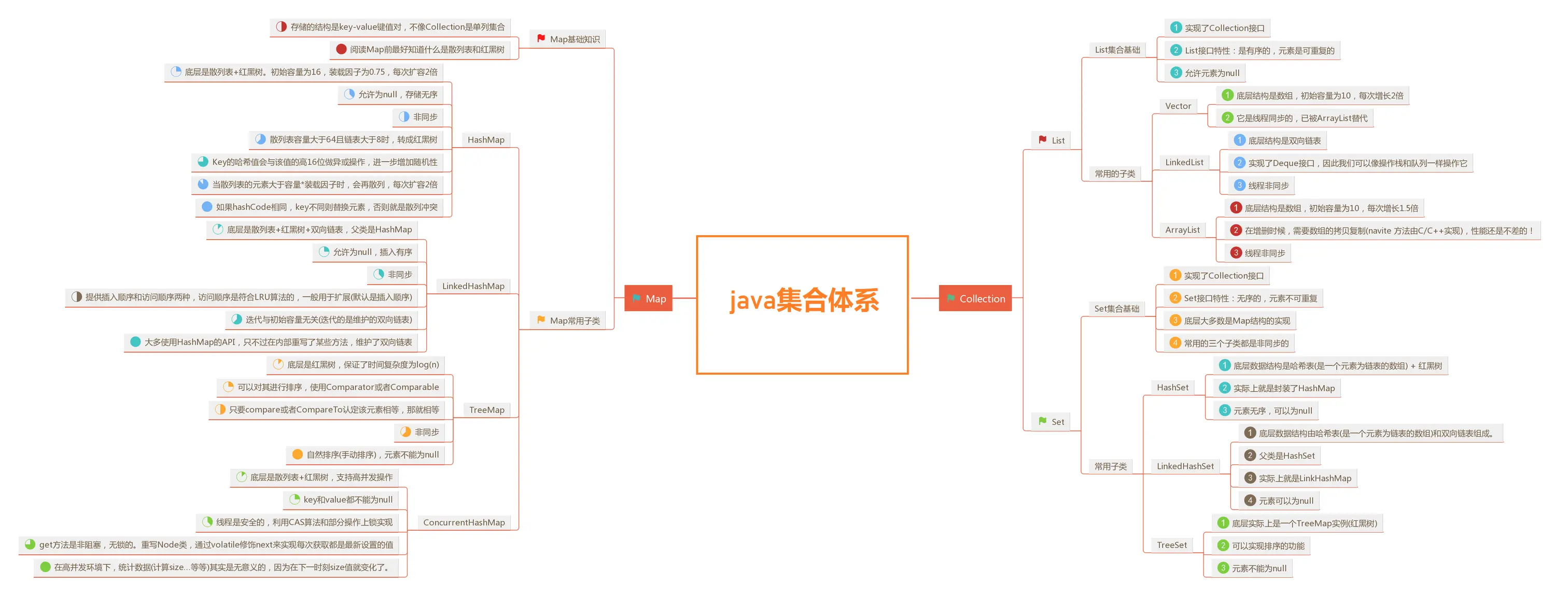
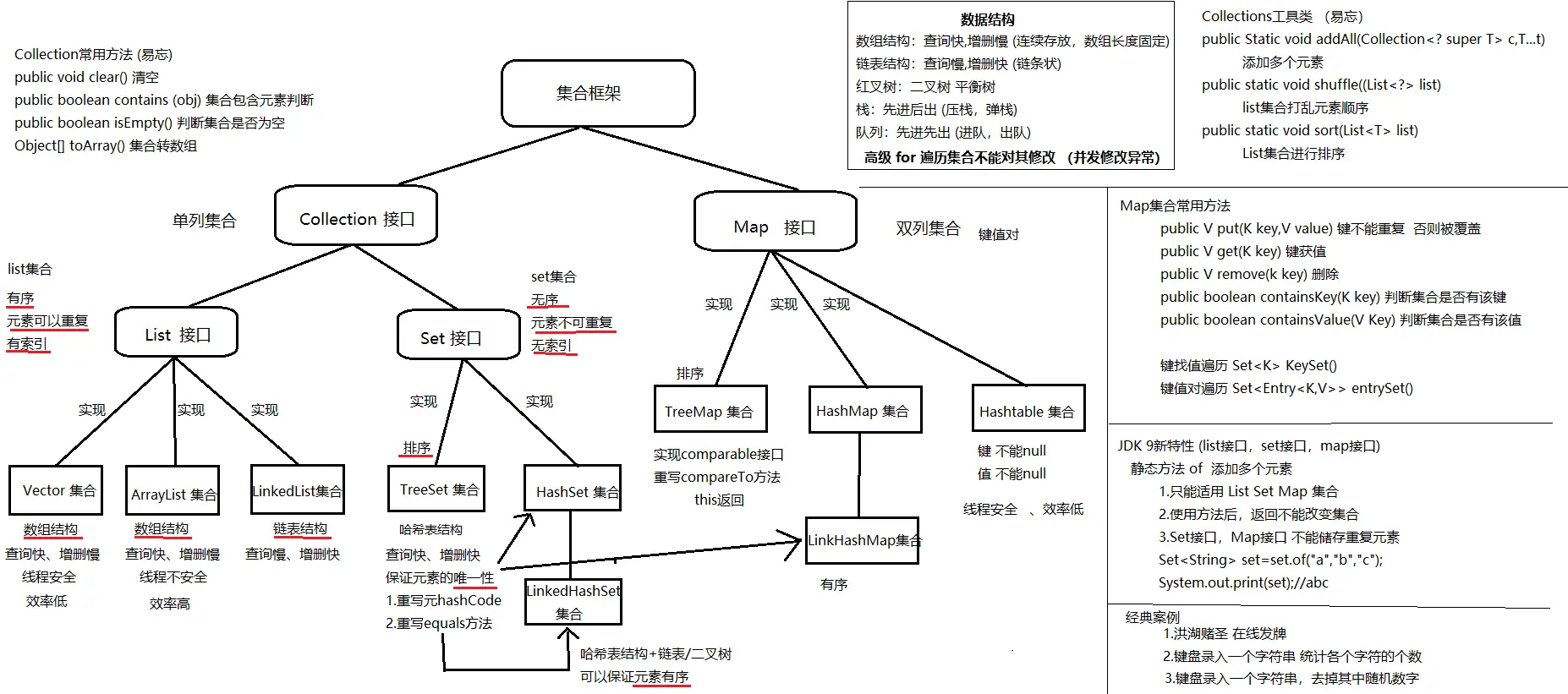
Collection接口
-
List接口
- 实现了Collection接口
- 有序的,元素是可重复的
- 允许元素为null
-
set接口
- 实现了Collection接口
- 无序的,元素是不可重复的
- 底层多是由map结构实现的
- 常用子类是非重复的
List接口
-
Vector集合
- 底层结构是数组,查询快,增删慢。初始容量是10,每次增长2倍
- 线程同步的,线程安全,效率低【已过时】
-
ArrayList集合
- 底层结构是数组,查询快,增删慢。初始容量是10,每次增长1.5倍
- 线程不同步,线程不安全,效率高
-
LinkedList集合
- 底层结构是双向链表,查询慢,增删慢
- 实现了Deque接口,因此我们可以像操作栈和队列一样操作它
- 线程非同步,线程不安全。
Set接口
-
HashSet集合
- 底层数据结构是哈希表(元素为链表的数组)+ 红黑树
- 实际就是封装了HashMap
- 元素无序,可以为null
-
LinkedHashSet集合
- 底层数据结构是哈希表(元素为链表的数组)+ 双向链表
- 父类是HashSet,实际是LinkedHashMap封装
- 元素可以为null
-
TreeSet集合
- 底层实际上是一个TreeMap实例(红黑数)
- 可以实现排序,元素不能为null
Map接口
-
HashMap集合
- 底层是数组+【链表】散列表+红黑树。初始容量为16,装载因子是0.75,每次扩容2倍
- 非同步,允许为null,储存无序
- 散列表容量大于64且链表大于8时,转为红黑树。
- 如果hashCode相同,key不同则替换元素,否则就是散列冲突
-
HashTable集合
- 同步,线程安全,效率低【已过时】
- 键和值均不能为null
-
LinkedHashMap集合
- 底层是散列表+红黑树+双向链表,父类是HashMap
- 非同步,允许为null,插入有序
-
TreeMap集合
- 底层是红黑树
- 实现Comparable接口,重写CompareTo方法,对其进行排序
- 非同步,自然排序(手动排序),元素不能为null
-
ConcurrentHashMap集合
- 线程安全,利用CAS算法等实现上锁
- 底层是散列表+红黑树,支持高并发
集合面试题
-
ArrayList和LinkedList区别
- ArrayList是一个可改变大小的数组。当更多元素假如ArrayList时,其大小会动态地增长【1.5倍】。查询快【直接根据索引查找元素】,增删慢【复制移动数组】,线程不同步,效率相对较高
- LinkedList是一个双链表,增删快【直接修改对应的指针】,查询慢【遍历链表】。线程非同步,线程不安全
-
ArrayList和Vector区别
- 两者,首先都实现了List接口,都是有序有索引集合,底层都是数组结构
- ArrayList集合是线程不同步,效率相对较高,Vector集合是线程同步,更加安全,效率相对较低【以过时】,元素扩充,ArrayList是0.5倍,Vector是1倍
-
HashMap和Hashtable的区别
- 两者,首先都实现了Map接口,存储结构和实现基本相同
- HashMap线程是非同步的,线程不安全,Hashtable线程是同步的,线程安全,实际操作的时候不适用,使用的是ConcurrentHashMap【底层是散列表+红黑树,支持高并发的访问和更新,key,value都不能为null】
- HashMap允许为null,Hashtable不允许为null
-
Collection和Collections的区别
- Collection【单列集合】,继承它的有List,Set接口
- Collections是集合的工具类,提供了一系列的静态方法对集合的搜索、查找、同步等操作
-
Java中HashMap的key值要是为类对象则该类需要满足什么条件?
- 需要同时重写该类的hashCode()方法和它的equals()方法【判断对象是否相等】
-
说一下HashMap的实现原理
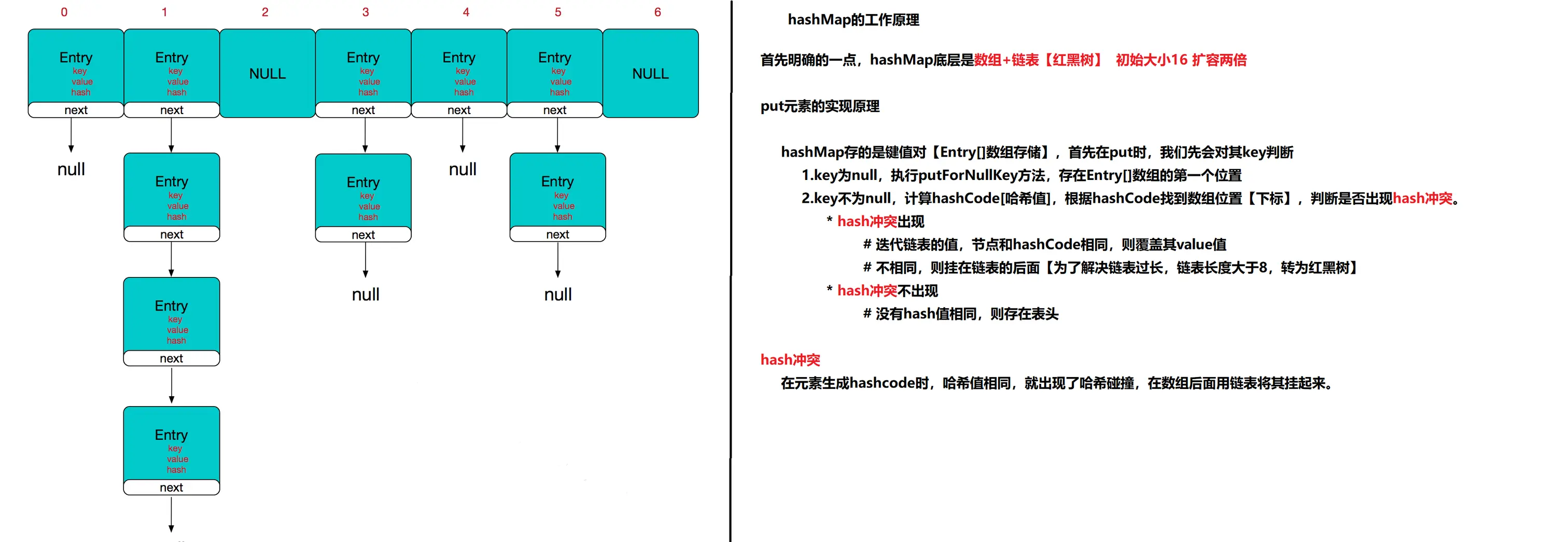
HashMap 基于 Hash 算法实现的,我们通过 put(key,value)存储,get(key)来获取。当传入 key 时,HashMap 会根据 key. hashCode() 计算出 hash 值,根据 hash 值将 value 保存在 bucket 里。当计算出的 hash 值相同时,我们称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value。
- 当 hash 冲突的个数比较少时,使用链表否则使用红黑树【链表大于8】。
-
List集合如何去掉重复值
-
如何理解hashCode,equals,它有什么作用
- 应用场景:set集合判断对象是否相等。如果直接用equals比较会效率很低。而hashcode获取的是散列码【实际返回对象的存储地址】,如果该地址没有元素,就可以直接存储。如果有元素在调用equals进行比较,相同就不存储。这样效率会大大增加
- 如果两个对象相等,那么它们的hashCode()值一定要相同;
- 如果两个对象hashCode()相等,它们并不一定相等
未完待续


