

前言
为什么要写散列表(Hash Table)?!因为忘记,就算以前在大学的时候学得多好,分数考多高。成了前端狗之后一方面是自己对自己不够严格,另一方面工作方面也是用得少这方面的知识,平时大多都是一群朋友吹牛皮的时候,亮出来吓吓人(也只能说自己记得的部分)。当夜深人静时都会想想自己吹过的牛皮~感叹这些知识自己真的忘得差不多了,三分钟热度来写个文章温故知新!
正文
什么是散列表
散列表(Hash Table),用一个映射函数将数据的特征值与数据保存表的存储位置建立联系,以便在寻找数据的时候可以快速定位,这样的表成为散列表(Hash Table),上述映射函数成为hash函数。
根据设定的哈希函数和冲突处理方法将一组关键字映射到一个有限连续的地址集上,并以关键字映射得到的值作为关键字对应数据在表中的存储位置,这种称为哈希表。
一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名 x 到首字母 F(x) 的一个函数关系),在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则 F(),存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。(摘自散列表维基百科)
为什么需要散列表
一般来说hash表的数据会用一个一维数组存储。而在低级语言中使用数组是需要预先申请数组的长度,即是内存大小。而在实际应用中,很难确定最后应该申请多大的内存,过大浪费资源,过小则会造成内存溢出。在溢出前你就需要扩容,扩容的时候又涉及到内存拷贝的问题,因为数组是一组连续的地址集,你难保在这段地址集后面的地址没有保存另外的数据。另外,单纯用数组存储数据,存储的时候很爽,但是在寻找的时候就一身骚了~毕竟在数组一定规模的时候你遍历一次或许就要做成千上万次的对比数据,这还是单纯的一维数组而已,如果是个矩阵呢?复杂度是不是就蹭蹭往上涨!
如何构建散列表
哈希函数
如上文所述,哈希函数就是用来确定数据特征值与数据在哈希表存储位置的映射关系。
对不同的关键字可能得到同一散列地址,即k1≠k2,而f(k1)=f(k2),这种现象称为冲突。具有相同函数值的关键字对该散列函数来说称做同义词。
常用的几个用于构建哈希函数的方法如下:
- 直接定址法:使用一个线性函数作为映射函数;
- 除留余数法:通过模 一个小于或等于散列表长度的值,取其余数作为散列表的存储位置;
- 数字分析法:肉眼观测,剔除显而易见的噪点;
- 平方中值法:将数据特征(一般是自然数)平方后取中间几位数,取几位取决于表的大小;
- 折叠法:将数据特征值分隔成为数相同的几部分,然后取叠加和(舍去高位);
- 伪随机数法;
以上每个方法不一一阐述,我只挑出“除留余数法”浅析。一是它常用;二是我只想说它。
除留余数法的数学表达式:
- hash( key ) = key mod p ( p ≤ m )
-
key: 数据特征值;
m: 散列表的长度;
下面用一例子对上述数学表达式进行实践(注意,一下例子只是对除留余数法的实践,并未完全达到理想的映射关系,仅仅是基本的关系):
假设现有一组数据
const names = ['Issac', 'Fanck', 'Sonia', 'Gary', 'Rick', 'Ryron', 'Emma'];
取以上人名的首字母的 ASCII码 作为数据的特征值。
const nameKeys = names.map((name) => {
const initial = name.slice(0, 1);
const key = initial.charCodeAt();
return key;
});
// print: [73, 70, 83, 71, 82, 82, 69]
然后,取 p = 7。对p的选择很重要,一般取素数(质数)或m,若p选择不好,容易产生冲突(哈希冲突)。
const p = 7;
const indexs = nameKeys.map((nameKey) => {
const index = nameKey % p;
return index;
});
// print: [3, 0, 6, 1, 5, 5, 6]
根据 names 和 indexs 的值:
['Issac', 'Fanck', 'Sonia', 'Gary', 'Rick', 'Ryron', 'Emma']
[ 3, 0, 6, 1, 5, 5, 6]
可以得到一个基本的关系表:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Fanck | Gary | - | Issac | - | Rick | Sonia |
| - | - | - | - | - | Ryron | Emma |
由表中的数据你可以看见3、5、6这三个位置都有一个以上的name映射到了同一个存储位置上,显然一个位置是不能存放多个数据,除非使用别的储存方式。该当如何下节分解!
哈希冲突(碰撞)
前一小节中出现“多个name映射到了同一个存储位置”的情况就是典型的哈希冲突。 出现哈希冲突,一是更换其他的哈希函数,二是对哈希函数的结果进行处理。要知道在数据足够大后无论怎么更换哈希函数都无法避免哈希冲突,只能尽量减小出现哈希冲突的几率。
常用方法有以下几种:
- 开放定址法;
- 单独链表法;
- 再散列;
- 双散列;
以下浅析前两种方法,原因同上。
开放定址法
开放定址法的数学表达式:
- Hash = (hash(key) + di) mod m, i=1,2,3...k (k <= m-1)
-
m为散列表长,di为增量序列(函数),i为已发生冲突的次数
增量序列的构建方法有以下几种:
- 线性探测:d(i) = i;
- 平方探测:d(i) = i^2;
- 伪随机探测;
下面用“线性探测”编写例子。
回顾哈希函数得到的映射结果:
['Issac', 'Fanck', 'Sonia', 'Gary', 'Rick', 'Ryron', 'Emma']
[ 3, 0, 6, 1, 5, 5, 6]
取哈希表的长度m = p = 7。
映射 Ryron 时出现冲突
# i = 1, d(1) = 1,hash(key) = 5
(5 + 1) mod 7 = 6 # 冲突
# i = 2, d(2) = 2,hash(key) = 5
(5 + 2) mod 7 = 0 # 冲突
// ...
# i = 4, d(4) = 4,hash(key) = 5
(5 + 4) mod 7 = 2 # 命中
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Fanck | Gary | Ryron | Issac | - | Rick | Sonia |
映射 Emma 时继续出现冲突
# i = 1, d(1) = 1,hash(key) = 6
(6 + 1) mod 7 = 0 # 冲突
# ...
# i = 5, d(5) = 5,hash(key) = 6
(6 + 5) mod 7 = 4 # 命中
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Fanck | Gary | Ryron | Issac | Emma | Rick | Sonia |
到此,冲突处理完毕,散列表构建完成!我们可以试着在散列表中查找数据。
假设现在要查找 Issac 和 Ryron:
# Issac
# key('I') = 73, Hash(key) = 3
hashTable(3) # output 'Issac' => Hit
# Ryron
# key('R') = 82, Hash(key) = 5
hashTable(3) # output 'Rick' => Miss
# d(1) = 1, Hash(key) = 6
hashTable(6) # output 'Sonia' => Miss
# ...
# d(4) = 4, Hash(key) = 2
hashTable(2) # output 'Ryron' => Hit
单独链表法
使用单链表作为存储数据的方式,言外之意,hash(key)得到的在哈希表的存储位置不再是数据的存储位置,而是用于存储数据所用链表的地址。
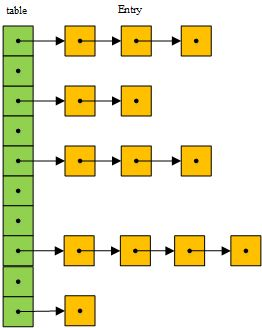
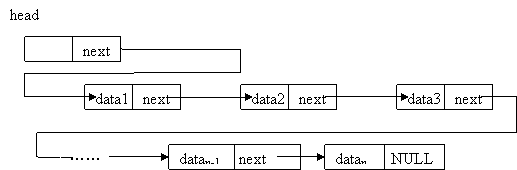
单链表(LinkList)形如:
class LinkList() {
constructor(_data, _next) {
this.head = new Entry();
}
insert(_data) {
// ...
}
find(_data) {
// ...
}
// ...
}
链表的每个节点形如:

class Entry {
constructor(_data, _next) {
this.data = _data;
this.next = _next;
}
}
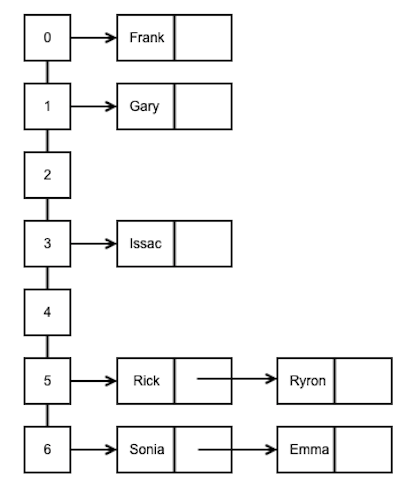
回顾哈希函数得到的映射结果:
['Issac', 'Fanck', 'Sonia', 'Gary', 'Rick', 'Ryron', 'Emma']
[ 3, 0, 6, 1, 5, 5, 6]
let key;
let index;
const hashTable = new Array(7);
// insert 'Issac'
key = getKey('Issac'); // 73
index = hash(key); // 3, 命中
hashTable(index) = new LinkList();
hashTable(index).insert('Issac');
// insert 'Fanck'
key = getKey('Fanck'); // 70
index = hash(key); // 0, 命中
hashTable(index) = new LinkList();
hashTable(index).insert('Fanck');
// insert 'Sonia'
key = getKey('Sonia'); // 83
index = hash(key); // 6, 命中
hashTable(index) = new LinkList();
hashTable(index).insert('Sonia');
// insert 'Gary'
key = getKey('Gary'); // 71
index = hash(key); // 1, 命中
hashTable(index) = new LinkList();
hashTable(index).insert('Gary');
// insert 'Rick'
key = getKey('Rick'); // 82
index = hash(key); // 5, 命中
hashTable(index) = new LinkList();
hashTable(index).insert('Rick');
// insert 'Ryron'
key = getKey('Ryron'); // 82
index = hash(key); // 5, 冲突
hashTable(index).insert('Ryron');
// insert 'Emma'
key = getKey('Emma'); // 69
index = hash(key); // 6, 冲突
hashTable(index).insert('Emma');
平均查找长度
为什么要求取“平均查找长度”?从上文中你可以发现,由于哈希冲突的出现,用数据特征并不能直接获取数据的储存位置,是需要进行一次以上的对比才能找到目标数据,也可能数据并不存在于哈希表中,即查找不成功。因此,就需要一个量度去衡量查找效率,即平均查找长度。
平均查找长度分为下面两类:
- 成功的平均查找长度:
- ASL = (d0 + d1 + d2 + ... + di) / n, (i = 0, 1, 2 ... n)
-
ASL: 平均查找长度,n: 哈希表的元素个数
di: 第 i 个元素查找成功所需要的查找(比对)次数
- 不成功的平均查找长度:
- ASL = (d0 + d1 + d2 + ... + di) / n, (i = 0, 1, 2 ... l)
-
l: 哈希表的长度,
n: 哈希表的元素个数,
ASL: 平均查找长度
di: 在第 i 个存储位置开始查找直到确定不存在所需要的查找(比对)次数
下面分别计算前一小节中哈希表的成功和不成功的平均查找长度。
# 成功的平均查找长度
Frank:1
Gary: 1
Issac: 1
Rick: 1
Ryron: 2
Sonia: 1
Emma: 2
ASL = (1 + 1 + 1 + 1 + 2 + 1 + 2) / 7 ≈ 1.2857
对于不成功的平均查找长度数学代数式中di有必要再细说一下。
比如现在要再上表中查找Fiona,这是不存在中的。
hash('F') # output 0
然后,就是在 hashTable(0) 存储的单链表中查找Fiona
# 第一次查找, 第一个节点的data存的是Frank,不匹配!
# 并且第一个的指针域为空指针(没有指向下一个节点),这样就成功确定Fiona不在表中,即查找失败!
结果是hash(key)等于0的查找失败长度为1
由上面的例子就可以知道:
# 不成功的平均查找长度
hash(key) => 0: 1
hash(key) => 1: 1
hash(key) => 2: 0
hash(key) => 3: 1
hash(key) => 4: 0
hash(key) => 5: 2
hash(key) => 6: 2
ASL = (1 + 1 + 0 + 1 + 0 + 2 + 2) / 7 = 1
载荷(装填)因子
载荷因子指的是哈希表的装满程度,具体计算式是:
- α = 表中元素个数 / 哈希表长度
从公式中你可以直观地感受到,α 越大下次存入新元素的时候发生冲突的几率越大,因为表中空缺的位置已经很小了!
发生冲突的次数越多,也就是意味着查找长度就可能越大!想想哈希表的存在意义:为了方便定位目标查找元素!查找长度足够大时哈希表就不在方便了,也就失去存在意义。而α就可以直观地指明当前哈希表已经不够方便了,那么这个时候就需要对哈希表进行扩容!没错,它就是标示何时应该扩容,比如java中的hashMap则是α > 0.75 时后对当前哈希表进行扩容!
最后写两句
上文其实已经很早就写好,剩下自己定的两个问题本来想浅析一下,但是由于自身原因一拖再拖,也只能先在此留个坑,希望自己有生之年可以回来填坑(滑稽)
- 如何判断一个哈希表的好坏?
- 为什么除留余数发中p一般取质数?
希望自己一如既往可以对未知的知识保有好奇心~
