

一个复杂的应用都是由简单的应用发展而来的, 随着越来越多的功能加入项目, 代码就会变得越来越难以控制. 本文章主要探讨在大型项目中如何对组件进行组织, 让项目具备可维护性.
系列目录
目录
1. 组件设计的基本原则
基本原则
单一职责(Single Responsibility Principle). 这原本来源于面向对象编程, 规范定义是"一个类应该只有一个发生变化的原因", 白话说"一个类只负责一件事情". 不管是什么编程范式, 只要是模块化的程序设计都适用单一职责原则. 在 React 中, 组件就是模块.
单一职责要求将组件限制在一个'合适'的粒度. 这个粒度是比较主观的概念, 换句话说'单一'是一个相对的概念. 我个人觉得单一职责并不是追求职责粒度的'最小'化, 粒度最小化是一个极端, 可能会导致大量模块, 模块离散化也会让项目变得难以管理. 单一职责要求的是一个适合被复用的粒度.
往往一开始我们设计的组件都可能复合多个职责, 后来出现了代码重复或者模块边界被打破(比如一个模块依赖另一个模块的'细节'), 我们才会惰性将可复用的代码抽离. 随着越来越多的重构和迭代, 模块职责可能会越来越趋于'单一'(😂 看谁, 也可能变成面条).
当然有经验的开发者可以一开始就能考虑组件的各种应用场景, 可以观察到模块的重合边界. 对于入门者来说Don't repeat yourself原则更有用, 不要偷懒/多思考/重构/消除重复代码, 你的能力就会慢慢提升
单一职责的收益:
- 降低组件的复杂度. 职责单一组件代码量少, 容易被理解, 可读性高
- 降低对其他组件的耦合. 当变更到来时可以降低对其他功能的影响, 不至于牵一发而动全身
- 提高可复用性. 功能越单一可复用性越高, 就比如一些基础组件
高质量组件的特征
一个高质量的组件一定是高内聚, 低耦合的, 这两个原则或者特征是组件独立性的一个判断标准.
高内聚, 要求一个组件有一个明确的组件边界, 将紧密相关的内容聚集在一个组件下, 实现"专一"的功能. 和传统的前端编程不一样, 一个组件是一个自包含的单元, 它包含了逻辑/样式/结构, 甚至是依赖的静态资源. 这也使得组件天然就是一个比较独立的个体. 当然这种独立性是相对的, 为了最大化这种独立性, 需要根据单一职责将组件拆分为更小粒度的组件, 这样可以被更灵活的组合和复用.
虽然组件是独立的, 但是他需要和其他组件进行组合才能实现应用, 这就有了'关联'. 低耦合要求最小化这种关联性, 比如明确模块边界不应该访问其他组件的内部细节, 组件的接口最小化, 单向数据流等等
文章后续内容主要讨论实现高内聚/低耦合主要措施
2. 基本技巧
这些技巧来源于react-bits:
- 如果组件不需要状态, 则使用无状态组件
- 性能上比较: 无状态函数 > 有状态函数 > class 组件
- 最小化 props(接口). 不要传递超过要求的 props
- 如果组件内部存在较多条件控制流, 这通常意味着需要对组件进行抽取
- 不要过早优化. 只要求组件在当前需求下可被复用, 然后'随机应变'
3. 组件的分类
1️⃣ 容器组件和展示组件分离
容器组件和展示组件分离是 React 开发的重要思想, 它影响的 React 应用项目的组织和架构. 下面总结一下两者的区别:
| 容器组件 | 展示组件 | |
|---|---|---|
| 关注点 | 业务 | UI |
| 数据源 | 状态管理器/后端 | props |
| 组件形式 | 高阶组件 | 普通组件 |
-
展示组件是一个只关注展示的'元件', 为了可以在多个地方被复用, 它不应该耦合'业务/功能', 或者说不应该过渡耦合. 像
antd这类组件库提供通用组件显然就是'展示组件'下面是一个典型的应用目录结构, 我们可以看到展示组件与业务/功能是可能有不同的耦合程度的, 和业务的耦合程度越低, 通用性/可复用性越强:
node_modules/antd/ 🔴 通用的组件库, 不能和任何项目的业务耦合 src/ components/ 🔴 项目通用的组件库, 可以被多个容器/页面组件共享 containers/ Foo/ components/ 🔴 容器/页面组件特有的组件库, 和一个业务/功能深度耦合. 以致于不能被其他容器组件共享 index.tsx Bar/ components/ index.tsx对于展示组件,我们要以一种'第三方组件库'的标准来考虑组件的设计, 减少与业务的耦合度, 考虑各种应用的场景, 设计好公开的接口.
-
容器组件主要关注业务处理. 容器组件一般以'高阶组件'形式存在, 它一般 ① 从外部数据源(redux 这些状态管理器或者直接请求服务端数据)获取数据, 然后 ② 组合展示组件来构建完整的视图.
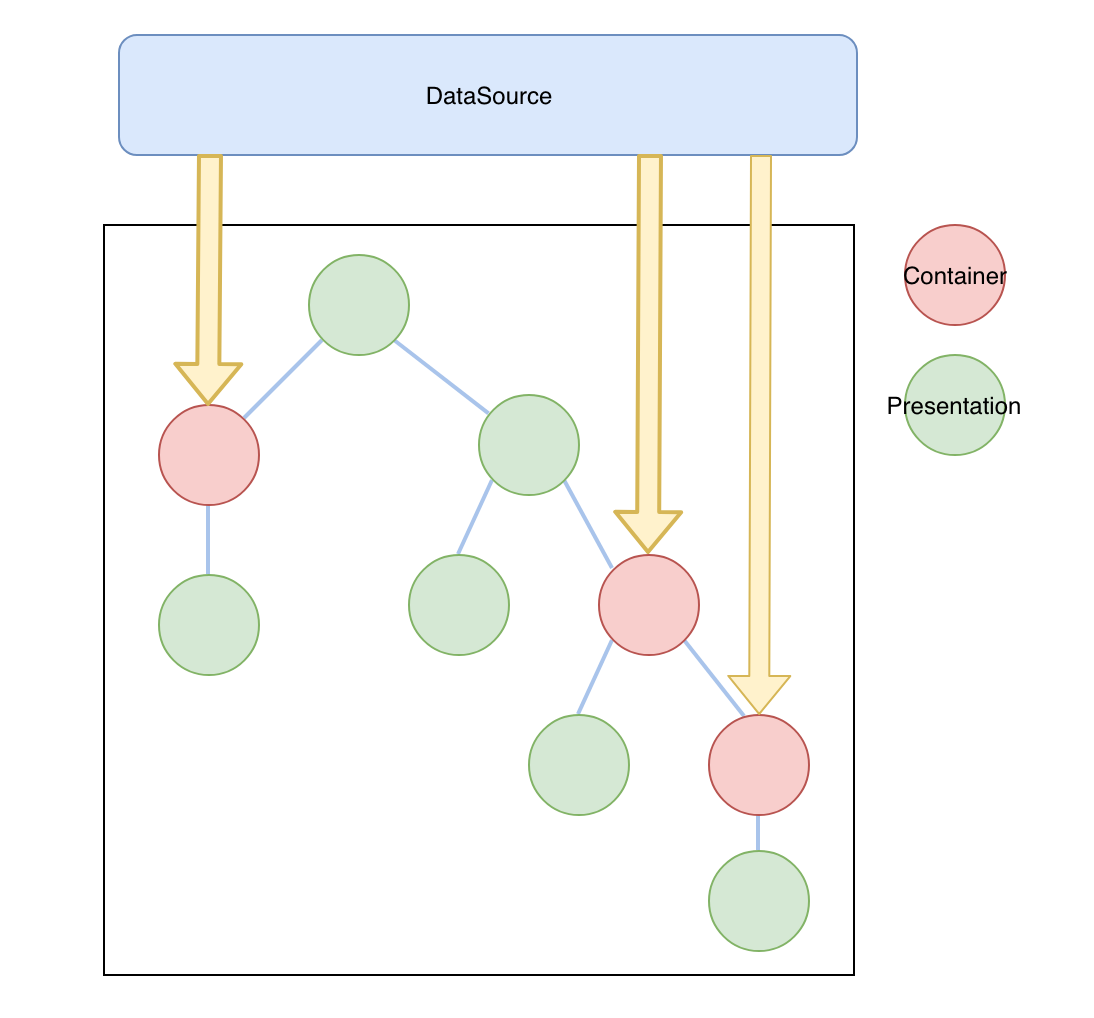
容器组件通过组合展示组件来构建完整视图, 但两者未必是简单的包含与被包含的关系.
容器组件和展示组件的分离可以带来好处主要是可复用性和可维护性:
- 可复用性: 展示组件可以用于多个不同的数据源(容器组件). 容器组件(业务逻辑)也可以被复用于不同'平台'的展示组件
- 展示和容器组件更好的分离,有助于更好的理解应用和 UI, 两者可以被独立地维护
- 展示组件变得轻量(无状态/或局部状态), 更容易被测试
了解更多Presentational and Container Components
2️⃣ 分离逻辑和视图
容器组件和展示组件的分离本质上是逻辑和视图的分离. 在React Hooks出现后, 容器组件可以被 Hooks 形式取代, Hooks 可以和视图层更自然的分离, 为视图层提供纯粹的数据来源.
抽离的后业务逻辑可以复用于不同的'展示平台', 例如 web 版和 native 版:
Login/
useLogin.ts // 可复用的业务逻辑
index.web.tsx
index.tsx
上面使用了useLogin.tsx来单独维护业务逻辑. 可以被 web 平台和 native 平台的代码复用.
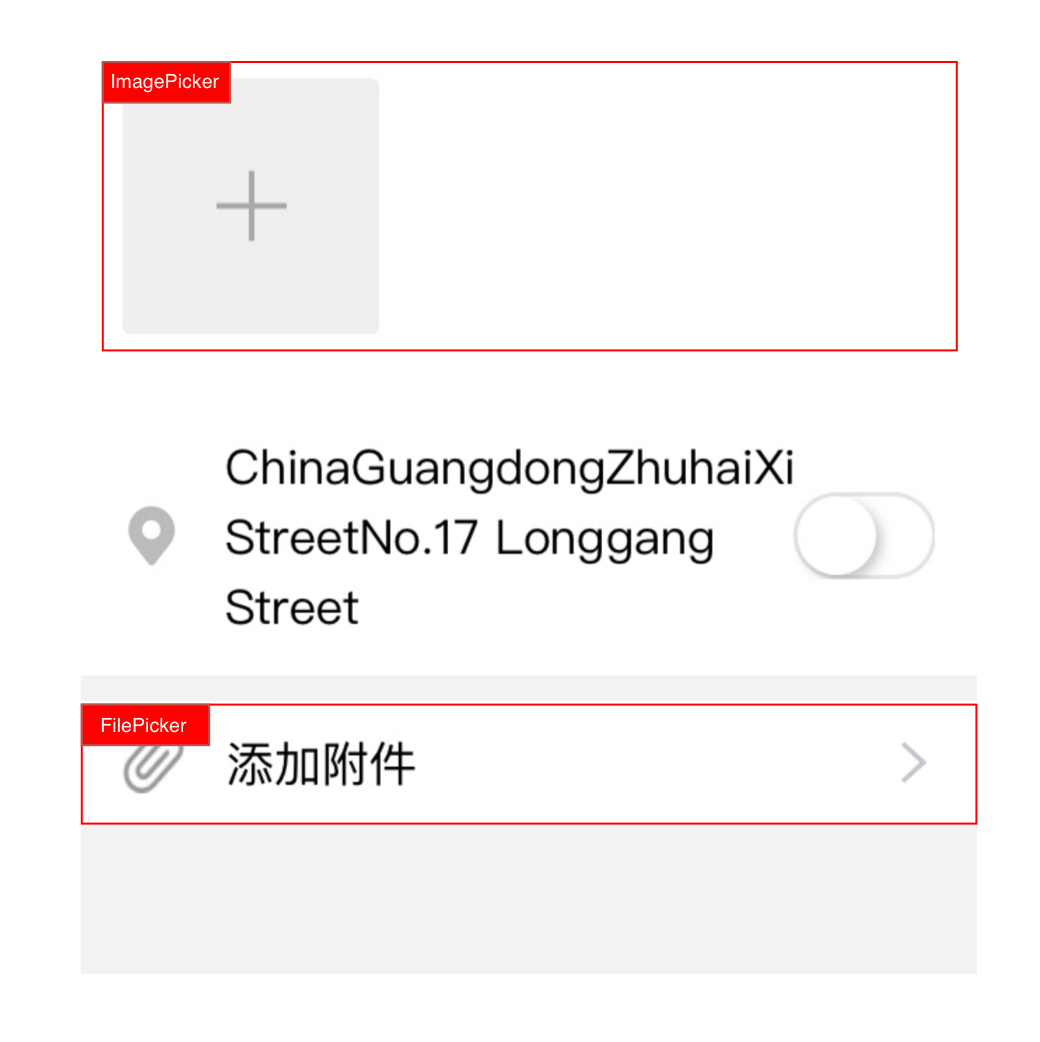
不仅仅是业务逻辑, 展示组件逻辑也可以分离. 例如上图, FilePicker和ImagePicker两个组件的'文件上传'逻辑是共享的, 这部分逻辑可以抽取到高阶组件或者 hooks, 甚至是 Context 中(可以统一配置文件上传行为)
分离逻辑和视图的主要方式有:
- hooks
- 高阶组件
- Render Props
- Context
3️⃣ 有状态组件和无状态组件
无状态组件内部不存储状态, 完全由外部的 props 来映射. 这类组件以函数组件形式存在, 作为低级/高复用的底层展示型组件. 无状态组件天然就是'纯组件', 如果无状态组件的映射需要一点成本, 可以使用 React.memo 包裹避免重复渲染
4️⃣ 纯组件和非纯组件
纯组件的'纯'来源于函数式编程. 指的是对于一个函数而言, 给定相同的输入, 它总是返回相同的输出, 过程没有副作用, 没有额外的状态依赖. 对应到 React 中, 纯组件指的是 props(严格上说还有 state 和 context, 它们也是组件的输入)没有变化, 组件的输出就不会变动.
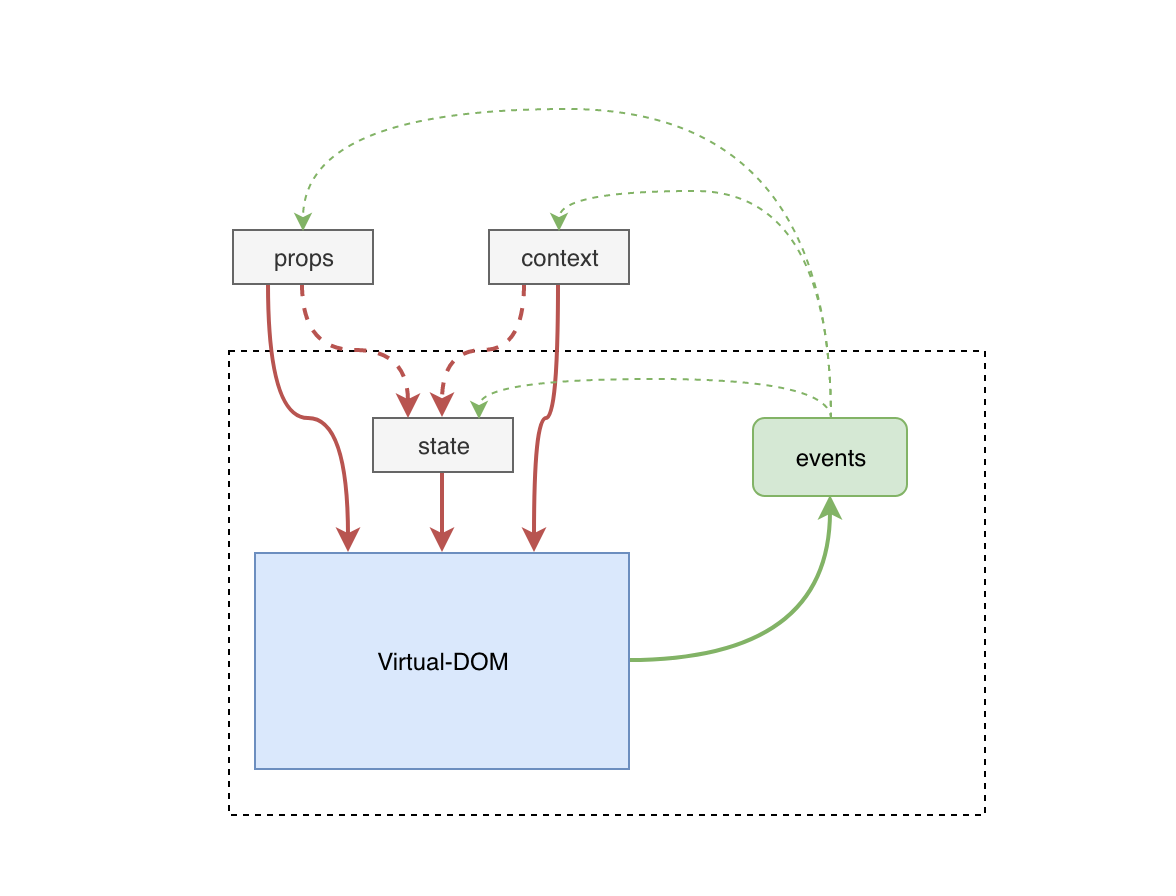
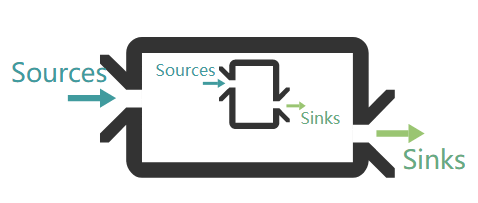
和 React 组件的输出输出模型相比, Cyclejs对组件输入/输出的抽象则做的更加彻底,更加‘函数式’👇。它的组件就是一个普通的函数,只有'单向'的输入和输出:
函数式编程和组件式编程思想某种意义上是一致的, 它们都是'组合'的艺术. 一个大的函数可以有多个职责单一函数组合而成. 组件也是如此. 我们将一个大的组件拆分为子组件, 对组件做更细粒度的控制, 保持它们的纯净性, 让它们的职责更单一, 更独立. 这带来的好处就是可复用性, 可测试性和可预测性.
纯组件对 React 的性能优化也有重要意义. 如果一个组件是一个纯组件, 如果'输入'没有变动, 那么这个组件就不需要重新渲染. 组件树越大, 纯组件带来的性能优化收益就越高.
我们可以很容易地保证一个底层组件的纯净性, 因为它本来就很简单. 但是对于一个复杂的组件树, 则需要花点心思进行构建, 所以就有了'状态管理'的需求. 这些状态管理器通常都在组件树的外部维护一个或多个状态库, 然后通过依赖注入形式, 将局部的状态注入到子树中. 通过视图和逻辑分离的原则, 来维持组件树的纯净性.
Redux 就是一个典型的解决方案, 在 Redux 的世界里可以认为一个复杂的组件树就是一颗状态树的映射, 只要状态树(需要依靠不可变数据来保证状态的可预测性)不变, 组件树就不变. Redux 建议保持组件的纯净性, 将组件状态交给 Redux 和配套的异步处理工具来维护, 这样就将整个应用抽象成了一个"单向的数据流", 这是一种简单的"输入/输出"关系
不管是 Cyclejs 还是 Redux,抽象是需要付出一点代价的,就比如 redux 代码可能会很罗嗦; 一个复杂的状态树, 如果缺乏良好的组织,整个应用会变得很难理解。实际上, 并不是所有场景都能够顺利/优雅通过'数据驱动'进行表达(可以看一下这篇文章Modal.confirm 违反了 React 的模式吗?), 例如文本框焦点, 或者模态框. 所以不必极端追求无副作用或者数据驱动
后续会专门写篇文章来回顾总结状态管理.
扩展:
5️⃣ 按照 UI 划分为布局组件和内容组件
- 布局组件用于控制页面的布局,为内容组件提供占位。通过 props 传入组件来进行填充. 比如
Grid,Layout,HorizontalSplit - 内容组件会包含一些内容,而不仅有布局。内容组件通常被布局组件约束在占位内. 比如
Button,Label,Input
例如下图, List/List.Item 就是布局组件,而 Input,Address 则是内容组件
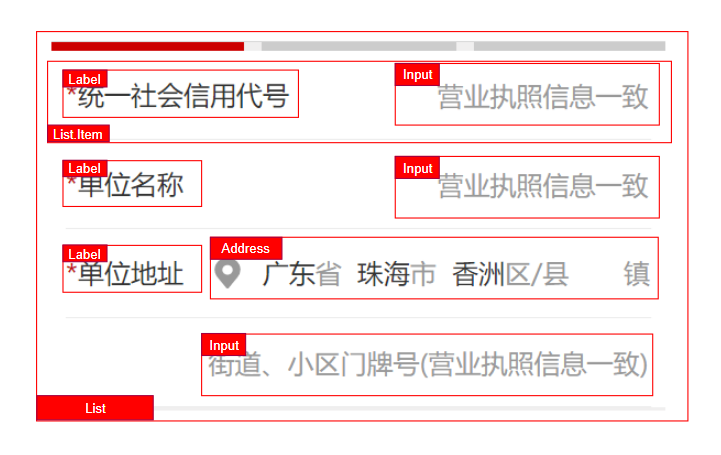
将布局从内容组件中抽取出来,分离布局和内容,可以让两者更好维护,比如布局变动不会影响内容,内容组件可以被应用不同的布局; 另一方面组件是一个自包含内聚的隔离单元, 不应该影响其外部的状态, 例如一个按钮不应该修改外部的布局, 另外也要避免影响全局的样式
6️⃣ 接口一致的数据录入组件
数据录入组件, 或者称为表单, 是客户端开发必不可少的元素. 对于自定义表单组件, 我认为应该保持一致的 API:
interface Props<T> {
value?: T;
onChange: (value?: T) => void;
}
这样做的好处:
-
接近原生表单元素原语. 自定义表单组件一般不需要封装到 event 对象中
-
几乎所有组件库的自定义表单都使用这种 API. 这使得我们的自定义组件可以和第三方库兼容, 比如antd 的表单验证机制
-
更容易被动态渲染. 因为接口一致, 可以方便地进行动态渲染或集中化处理, 减少代码重复
-
回显问题. 状态回显是表单组件的功能之一, 我个人的最佳实践是
value应该是自包含的:比如一个支持搜索的用户选择器, option 都是异步从后端加载, 如果 value 只保存用户 id, 那么回显的时候就无法显示用户名, 按照我的实践的 value 的结构应该为:
{id: string, name: string}, 这样就解决了回显问题. 回显需要的数据都是由父节点传递进来, 而不是组件自己维护 -
组件都是受控的. 在实际的 React 开发中, 非受控组件的场景非常少, 我认为自定义组件都可以忽略这种需求, 只提供完全受控表单组件, 避免组件自己维护缓存状态
4. 目录划分
1️⃣ 基本目录结构
关于项目目录结构的划分有两种流行的模式:
- Rails-style/by-type: 按照文件的类型划分为不同的目录,例如
components、constants、typings、views - Domain-style/by-feature: 按照一个功能特性或业务创建单独的文件夹,包含多种类型的文件或目录
实际的项目环境我们一般使用的是混合模式,下面是一个典型的 React 项目结构:
src/
components/ # 🔴 项目通用的‘展示组件’
Button/
index.tsx # 组件的入口, 导出组件
Groups.tsx # 子组件
loading.svg # 静态资源
style.css # 组件样式
...
index.ts # 到处所有组件
containers/ # 🔴 包含'容器组件'和'页面组件'
LoginPage/ # 页面组件, 例如登录
components/ # 页面级别展示组件,这些组件不能复用与其他页面组件。
Button.tsx # 组件未必是一个目录形式,对于一个简单组件可以是一个单文件形式. 但还是推荐使用目录,方便扩展
Panel.tsx
reducer.ts # redux reduces
useLogin.ts # (可选)放置'逻辑', 按照👆分离逻辑和视图的原则,将逻辑、状态处理抽取到hook文件
types.ts # typescript 类型声明
style.css
logo.png
message.ts
constants.ts
index.tsx
HomePage/
...
index.tsx # 🔴应用根组件
hooks/ # 🔴可复用的hook
useList.ts
usePromise.ts
...
index.tsx # 应用入口, 在这里使用ReactDOM对跟组件进行渲染
stores.ts # redux stores
contants.ts # 全局常量
上面使用Domain-style风格划分了LoginPage和HomePage目录, 将所有该业务或者页面相关的文件聚合在一起; 这里也使用Rails-style模式根据文件类型/职责划分不同的目录, 比如components, hooks, containers; 你会发现在LoginPage内部也有类似Rails-Style的结构, 如components, 只不过它的作用域不同, 它只归属于LoginPage, 不能被其他 Page 共享
前端项目一般按照页面路由来拆分组件, 这些组件我们暂且称为‘页面组件’, 这些组件是和业务功能耦合的,而且每个页面之间具有一定的独立性.
这里将页面组件放置在containers, 如其名,这个目录原本是用来放置容器组件的, 实际项目中通常是将‘容器组件’和‘页面组件’混合在了一起, 现阶段如果要实现纯粹的逻辑分离,我个人觉得还是应该抽取到 hook 中. 这个目录也可以命名为 views, pages...(whatever), 命名为 containers 只是一种习惯(来源于 Redux).
扩展:
2️⃣ 多页应用的目录划分
对于大型应用可能有多个应用入口, 例如很多 electron 应用有多个 windows; 再比如很多应用除了 App 还有后台管理界面. 我一般会这样组织多页应用:
src/
components/ # 共享组件
containers/
Admin/ # 后台管理页面
components/ # 后台特定的组件库
LoginPage/
index.tsx
...
App/
components/ # App特定的组件库
LoginPage/ # App页面
index.tsx
stores.ts # redux stores
AnotherApp/ # 另外一个App页面
hooks/
...
app.tsx # 应用入口
anotherApp.tsx # 应用入口
admin.tsx # 后台入口
webpack 支持多页应用的构建, 我一般会将应用入口文件命名为*.page.tsx, 然后在 src 自动扫描匹配的文件作为入口.
利用 webpack 的SplitChunksPlugin可以自动为多页应用抽取共享的模块, 这个对于功能差不多和有较多共享代码的多页应用很有意义. 意味着资源被一起优化, 抽取共享模块, 有利于减少编译文件体积, 也便于共享浏览器缓存.
html-webpack-plugin4.0 开始支持注入共享 chunk. 在此之前需要通过 SplitChunksPlugin 显式定义共享的 chunk, 然后也要 html-webpack-plugin 显式注入该 chunk, 比较挫.
3️⃣ 多页应用的目录划分: monorepo 模式
上面的方式, 所有页面都聚集在一个项目下面, 共享一样的依赖和 npm 模块. 这可能会带了一些问题:
- 不能允许不同页面有不同版本的依赖
- 对于毫无相关的应用, 这种组织方式会让代码变得混乱, 例如 App 和后台, 他们使用的技术栈/组件库/交互体验都可能相差较大, 而且容易造成命名冲突.
- 构建性能. 你希望单独对某个页面进行构建和维护, 而不是所有页面混合在一起构建
这种场景可以利用lerna或者 yarn workspace 这里 monorepo 机制, 将多页应用隔离在不同的 npm 模块下, 以 yarn workspace 为例:
package.json
yarn.lock
node_modules/ # 所有依赖都会安装在这里, 方便yarn对依赖进行优化
share/ # 🔴 共享模块
hooks/
utils/
admin/ # 🔴 后台管理应用
components/
containers/
index.tsx
package.json # 声明自己的模块以及share模块的依赖
app/ # 🔴 后台管理应用
components/
containers/
index.tsx
package.json # 声明自己的模块以及share模块的依赖
扩展:
4️⃣ 跨平台应用
使用 ReactNative 可以将 React 衍生到原生应用的开发领域. 尽管也有react-native-web这样的解决方案, Web 和 Native 的 API/功能/开发方式, 甚至产品需求上可能会相差很大, 久而久之就可能出现大量无法控制的适配代码; 另外 react-native-web 本身也可能成为风险点。 所以一些团队需要针对不同平台进行开发, 一般按照下面风格来组织跨平台应用:
src/
components/
Button/
index.tsx # 🔴 ReactNative 组件
index.web.tsx # 🔴 web组件, 以web.tsx为后缀
loading.svg # 静态资源
style.css # 组件样式
...
index.ts
index.web.ts
containers/
LoginPage/
components/
....
useLogin.ts # 🔴 存放分离的逻辑,可以在React Native和Web组件中共享
index.web.tsx
index.tsx
HomePage/
...
index.tsx
hooks/
useList.ts
usePromise.ts
...
index.web.tsx # web应用入口
index.tsx # React Native 应用入口
可以通过 webpack 的resolve.extensions来配置扩展名补全的优先级. 早期的antd-mobile就是这样组织的.
5️⃣ 跨平台的另外一种方式: taro
对于国内的开发者来说,跨平台可不只 Native 那么简单,我们还有各种各样的小程序、小应用。终端的碎片化让前端的开发工作越来越有挑战性.
Taro 就这样诞生了, Taro 基于 React 的标准语法(DSL), 结合编译原理的思想, 将一套代码转换为多种终端的目标代码, 并提供一套统一的内置组件库和 SDK 来抹平多端的差异
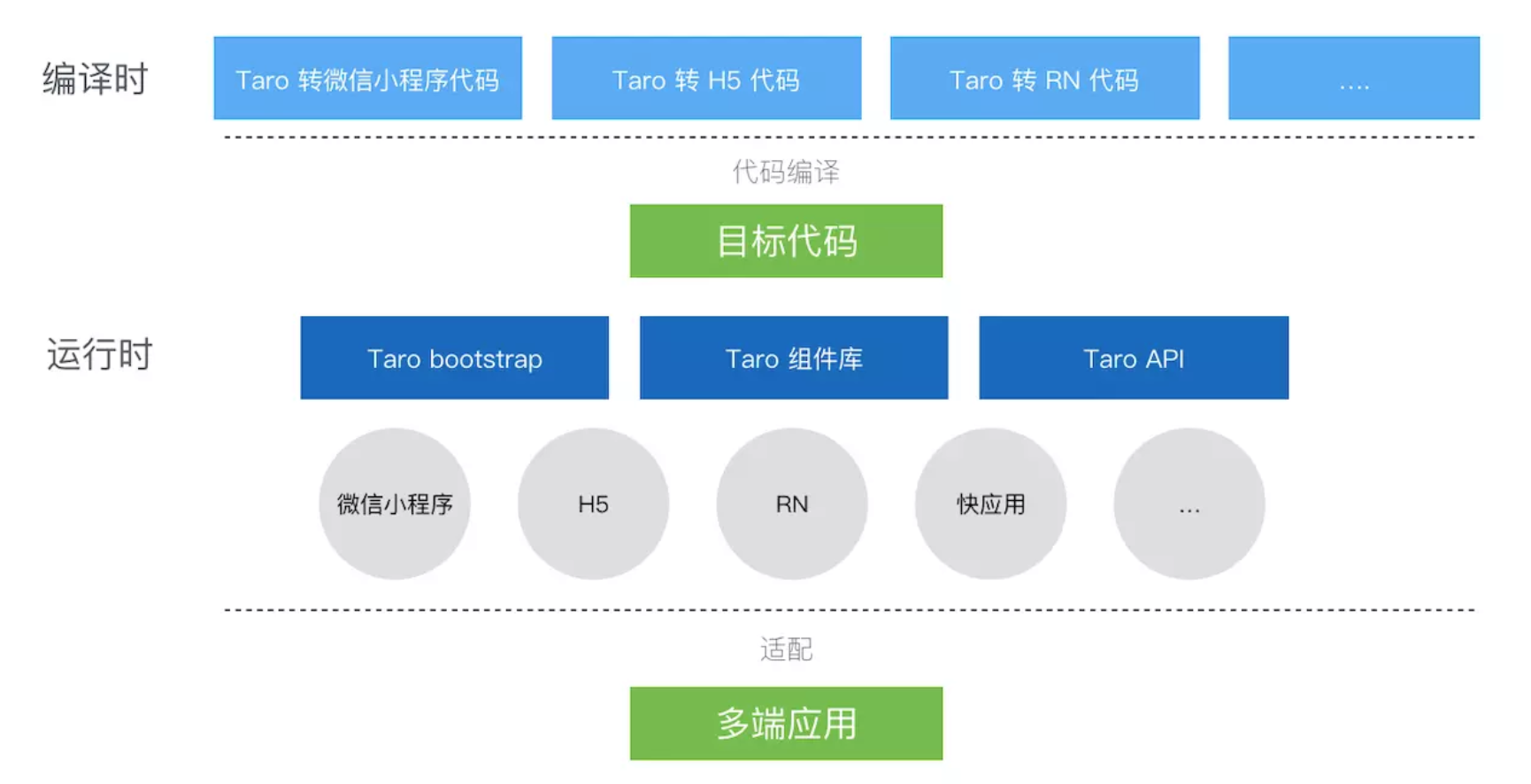
因为 Taro 使用 React 的标准语法和 API,这使得我们按照原有的 React 开发约定和习惯来开发多端应用,且只保持一套代码. 但是不要忘了抽象都是有代价的
可以查看 Taro 官方文档了解更多
Flutter是近期比较或的跨平台方案,但是跟本文主题无关
5. 模块
1️⃣ 创建严格的模块边界
下图是一个某页面的模块导入,相当混乱,这还算可以接受,笔者还见过上千行的组件,其中模块导入语句就占一百多行. 这有一部分原因可能是 VsCode 自动导入功能导致(可以使用 tslint 规则对导入语句进行排序和分组规范),更大的原因是这些模块缺乏组织。
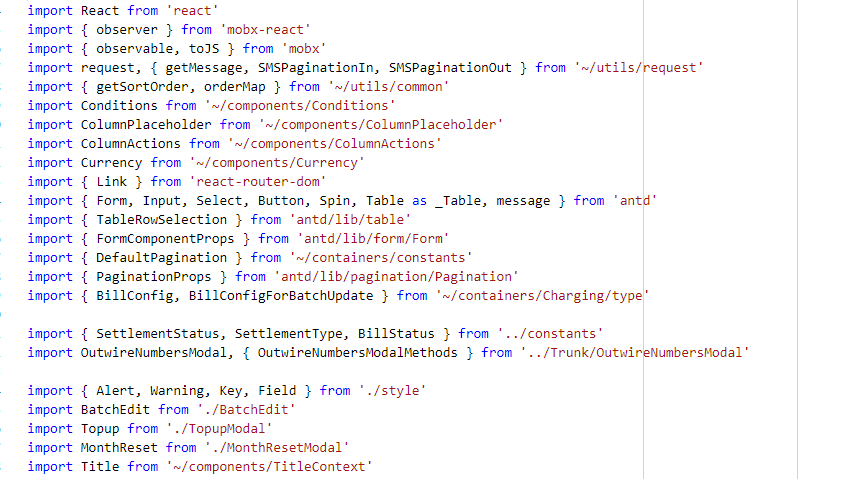
我觉得应该创建严格的模块边界,一个模块只有一个统一的'出口'。例如一个复杂的组件:
ComplexPage/
components/
Foo.tsx
Bar.tsx
constants.ts
reducers.ts
style.css
types.ts
index.tsx # 出口
可以认为一个‘目录’就是一个模块边界. 你不应该这样子导入模块:
import ComplexPage from '../ComplexPage';
import Foo from '../ComplexPage/components/Foo';
import Foo from '../ComplexPage/components/Bar';
import { XXX } from '../ComplexPage/components/constants';
import { User, ComplexPageProps } from '../ComplexPage/components/type';
一个模块/目录应该由一个‘出口’文件来统一管理模块的导出,限定模块的可见性. 比如上面的模块,components/Foo、 components/Bar和constants.ts这些文件其实是 ComplexPage 组件的'实现细节'. 这些是外部模块不应该去耦合实现细节,但这个在语言层面并没有一个限定机制,只能依靠规范约定.
当其他模块依赖某个模块的'细节'时, 可能是一种重构的信号: 比如依赖一个模块的一个工具函数或者是一个对象类型声明, 这时候可能应该将其抬升到父级模块, 让兄弟模块共享它.
在前端项目中 index 文件最适合作为一个'出口'文件, 当导入一个目录时,模块查找器会查找该目录下是否存在的 index 文件. 开发者设计一个模块的 API 时, 需要考虑模块各种使用方式, 并使用 index 文件控制模块可见性:
// 导入外部模块需要使用的类型
export * from './type';
export * from './constants';
export * from './reducers';
// 不暴露外部不需要关心的实现细节
// export * from './components/Foo'
// export * from './components/Bar'
// 模块的默认导出
export { ComplexPage as default } from './ComplexPage';
现在导入语句可以更加简洁:
import ComplexPage, { ComplexPageProps, User, XXX } from '../ComplexPage';
这条规则也可以用于组件库. 在 webpack 的 Tree-shaking 特性还不成熟之前, 我们都使用了各种各样的技巧来实现按需导入. 例如babel-plugin-import或直接子路径导入:
import TextField from '~/components/TextField';
import SelectField from '~/components/SelectField';
import RaisedButton from '~/components/RaisedButton';
现在可以使用Named import直接导入,让 webpack 来帮你优化:
import { TextField, SelectField, RaisedButton } from '~/components';
但不是所有目录都有出口文件, 这时候目录就不是模块的边界了. 典型的有utils/, utils 只是一个模块命名空间, utils 下面的文件都是一些互不相关或者不同类型的文件:
utils/
common.ts
dom.ts
sdk.ts
我们习惯直接引用这些文件, 而不是通过一个入口文件, 这样可以更明确导入的是什么类型的:
import { hide } from './utils/dom'; // 通过文件名可以知道, 这可能是隐藏某个DOM元素
import { hide } from './utils/sdk'; // webview sdk 提供的的某个方法
最后再总结一下:
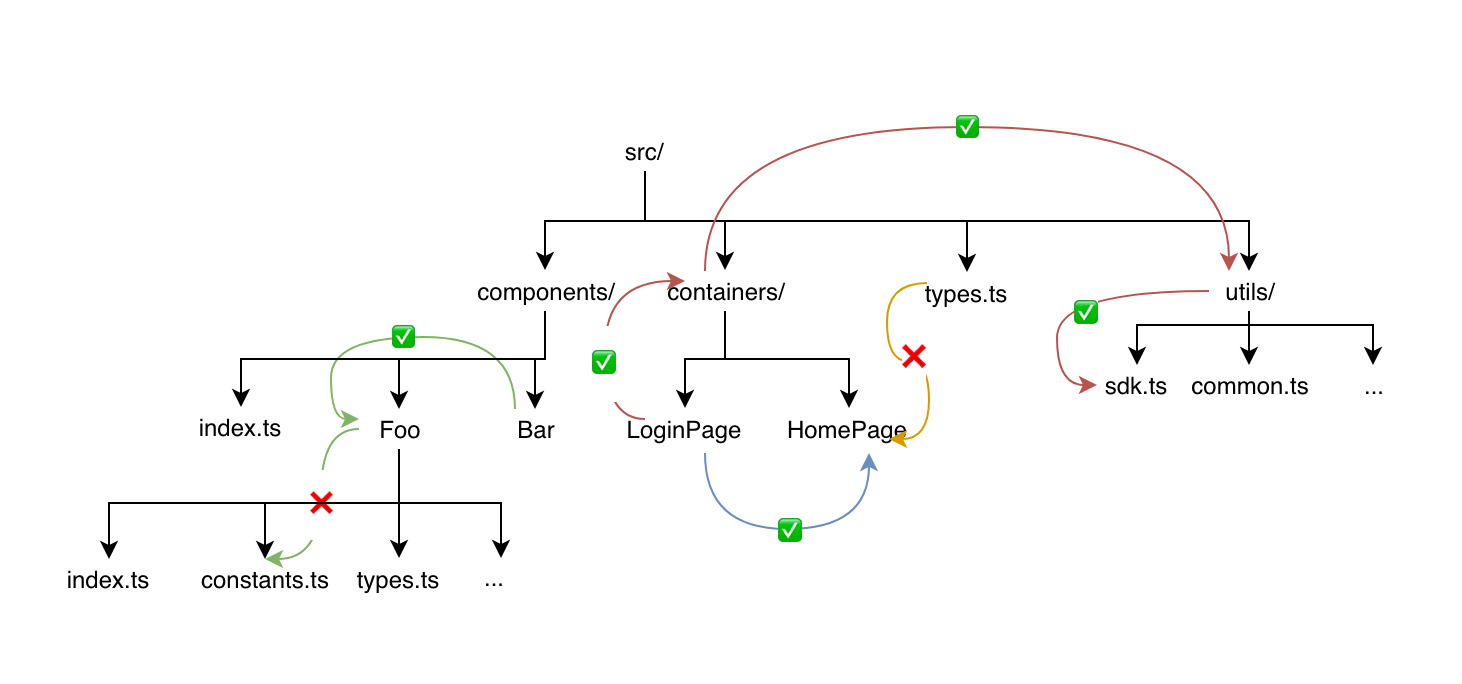
根据模块边界原则(如上图): 一个模块可以访问兄弟(同个作用域下)、 祖先及祖先的兄弟模块. 例如:
- Bar 可以访问 Foo, 但不能再向下访问它的细节, 即不能访问
../Foo/types.ts, 但可以访问它的出口文件../Foo - src/types.ts 不能访问 containers/HomePage
- LoginPage 和访问 HomePage
- LoginPage 可以访问 utils/sdk
2️⃣ Named export vs default export
这两种导出方式都有各自的适用场景,这里不应该一棒子打死就不使用某种导出方式. 首先看一下named export 有什么优点:
-
命名确定
-
方便 Typescript 进行重构
-
方便智能提醒和自动导入(auto-import)识别
-
方便 reexport
// named export * from './named-export'; // default export { default as Foo } from './default-export';
-
-
一个模块支持多个
named export
再看一下default export有什么优点?:
-
default export一般代表‘模块本身’, 当我们使用‘默认导入’导入一个模块时, 开发者是自然而然知道这个默认导入的是一个什么对象。例如 react 导出的是一个 React 对象; LoginPage 导出的是一个登录页面; somg.png 导入的是一张图片. 这类模块总有一个确定的'主体对象'. 所以默认导入的名称和模块的名称一般是保持一致的(Typescript 的 auto-import 就是基于文件名).
当然'主体对象'是一种隐式的概念, 你只能通过规范去约束它
-
default export的导入语句更加简洁。例如lazy(import('./MyPage'))
default export也有一些缺点:
- 和其他模块机制(commonjs)互操作时比较难以理解. 例如我们会这样子导入
default export:require('./xx').default named import优点就是default export的缺点
所以总结一下:
- 对于'主体对象'明确的模块需要有默认导出, 例如页面组件,类
- 对于'主体对象'不明确的模块不应该使用默认导出,例如组件库、utils(放置各种工具方法)、contants 常量
按照这个规则可以这样子组织 components 目录:
components/
Foo/
Foo.tsx
types.ts
constants.ts
index.ts # 导出Foo组件
Bar/
Bar.tsx
index.tsx
index.ts # 导出所有组件
对于 Foo 模块来说, 存在一个主体对象即 Foo 组件, 所以这里使用default export导出的 Foo 组件, 代码为:
// index.tsx
// 这三个文件全部使用named export导出
export * from './contants';
export * from './types';
export * from './Foo';
// 导入主体对象
export { Foo as default } from './Foo';
现在假设 Bar 组件依赖于 Foo:
// components/Bar/Bar.tsx
import React from 'react';
// 导入Foo组件, 根据模块边界规则, 不能直接引用../Foo/Foo.tsx
import Foo from '../Foo';
export const Bar = () => {
return (
<div>
<Foo />
</div>
);
};
export default Bar;
对于components模块来说,它的所有子模块都是平等的,所以不存在一个主体对象,default export在这里不适用。 components/index.ts代码:
// components/index.ts
export * from './Foo';
export * from './Bar';
3️⃣ 避免循环依赖
循环依赖是模块糟糕设计的一个表现, 这时候你需要考虑拆分和设计模块文件, 例如
// --- Foo.tsx ---
import Bar from './Bar';
export interface SomeType {}
export const Foo = () => {};
Foo.Bar = Bar;
// --- Bar.tsx ----
import { SomeType } from './Foo';
...
上面 Foo 和 Bar 组件就形成了一个简单循环依赖, 尽管它不会造成什么运行时问题. 解决方案就是将 SomeType 抽取到单独的文件:
// --- types.ts ---
export interface SomeType {}
// --- Foo.tsx ---
import Bar from './Bar';
import {SomeType} from './types'
export const Foo = () => {};
...
Foo.Bar = Bar;
// --- Bar.tsx ----
import {SomeType} from './types'
...
4️⃣ 相对路径不要超过两级
当项目越来越复杂, 目录可能会越来越深, 这时候会出现这样的导入路径:
import { hide } from '../../../utils/dom';
首先这种导入语句非常不优雅, 而且可读性很差. 当你在不清楚当前文件的目录上下文时, 你不知道具体模块在哪; 即使你知道当前文件的位置, 你也需要跟随导入路径在目录树中向上追溯在能定位到具体模块. 所以这种相对路径是比较反人类的.
另外这种导入路径不方便模块迁移(尽管 Vscode 支持移动文件时重构导入路径), 文件迁移需要重写这些相对导入路径.
所以一般推荐相对路径导入不应该超过两级, 即只能是../和./. 可以尝试将相对路径转换成绝对路径形式, 例如webpack中可以配置resolve.alias属性来实现:
...
resolve: {
...
alias: {
// 可以直接使用~访问相对于src目录的模块
// 如 ~/components/Button
'~': context,
},
}
现在我们可以这样子导入相对于src的模块:
import { hide } from '~/utils/dom';
扩展
- 对于 Typescript 可以配置paths选项;
- 对于 babel 可以使用
babel-plugin-module-resolver插件来转换为相对路径
6. 拆分
1️⃣ 拆分 render 方法
当 render 方法的 JSX 结构非常复杂的时候, 首先应该尝试分离这些 JSX, 最简单的做法的就是拆分为多个子 render 方法:
当然这种方式只是暂时让 render 方法看起来没有那么复杂, 它并没有拆分组件本身, 所有输入和状态依然聚集在一个组件下面. 所以通常拆分 render 方法只是重构的第一步: 随着组件越来越复杂, 表现为文件越来越长, 笔者一般将 300 行作为一个阈值, 超过 300 行则说明需要对这个组件进进一步拆分
2️⃣ 拆分为组件
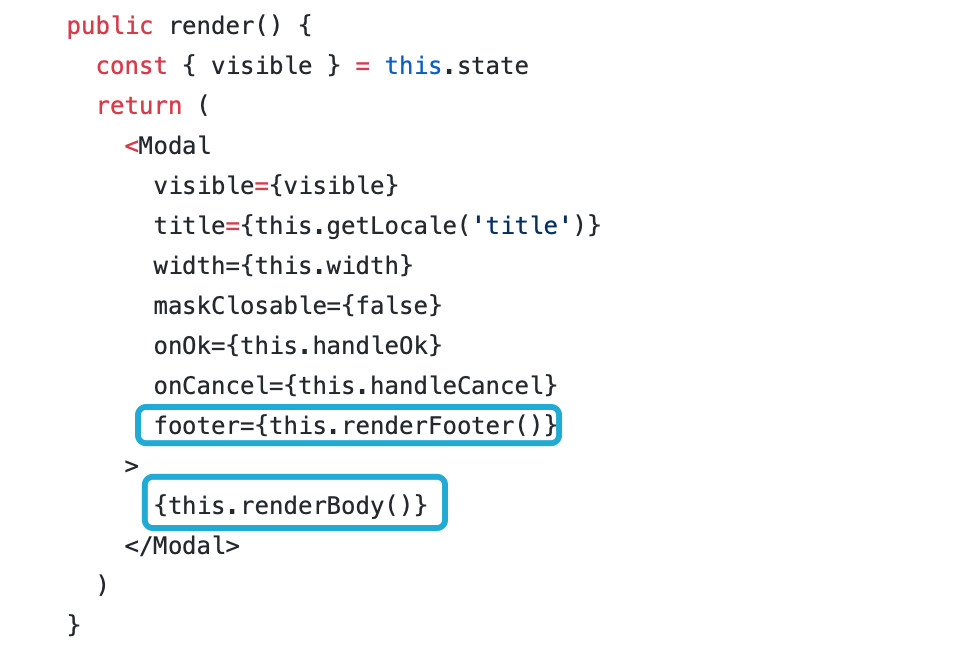
如果已经按照 👆 上述方法对组件的 render 拆分为多个子 render, 当一个组件变得臃肿时, 就可以方便地将这些子 render 方法拆分为组件. 一般组件抽离有以下几种方式:
- 纯渲染拆分: 子 render 方法一般是纯渲染的, 他们可以很直接地抽离为无状态组件
public render() {
const { visible } = this.state
return (
<Modal
visible={visible}
title={this.getLocale('title')}
width={this.width}
maskClosable={false}
onOk={this.handleOk}
onCancel={this.handleCancel}
footer={<Footer {...}></Footer>}
>
<Body {...}></Body>
</Modal>
)
}
- 纯逻辑拆分: 按照
逻辑和视图分离的原则, 将逻辑控制部分抽离到 hooks 或高阶组件中 - 逻辑和渲染拆分: 将相关的视图和逻辑抽取出去形成一个独立的组件, 这是更为彻底的拆分方式, 贯彻单一职责原则.
7. 组件划分示例
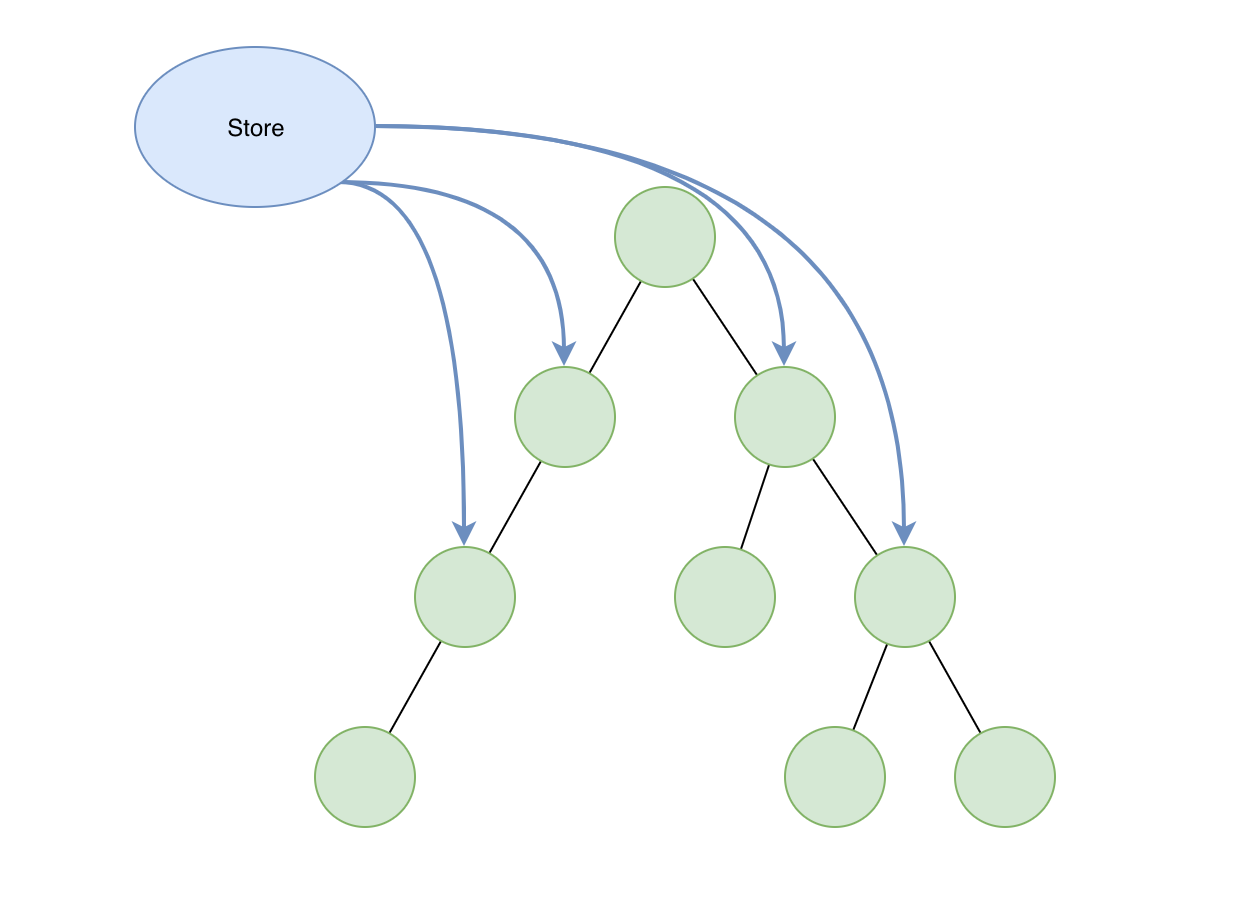
我们一般会从 UI 原型图中分析和划分组件, 在 React 官方的Thinking in react也提到通过 UI 来划分组件层级: "这是因为 UI 和数据模型往往遵循着相同的信息架构,这意味着将 UI 划分成组件的工作往往是很容易的。只要把它划分成能准确表示你数据模型的一部分的组件就可以". 组件划分除了需要遵循上文 👆 提到的一些原则, 他还依赖于你的开发经验.
本节通过一个简单的应用讲述划分组件的过程. 这是某政府部门的服务申报系统, 一共由四个页面组成:

1️⃣ 划分页面
页面通常是最顶层的组件单元, 划分页面非常简单, 我们根据原型图就可以划分四个页面: ListPage, CreatePage, PreviewPage, DetailPage
src/
containers/
ListPage/
CreatePage/
PreviewPage/
DetailPage/
index.tsx # 根组件, 一般在这里定义路由
2️⃣ 划分基础 UI 组件
首先看ListPage

ListPage 根据 UI 可以划分为下面这些组件:
ScrollView # 滚动视图, 提供下拉刷新, 无限加载等功能
List # 列表容器, 布局组件
Item # 列表项, 布局组件, 提供header, body等占位符
props - header
Title # 渲染标题
props - after
Time # 渲染时间
props - body
Status # 渲染列表项的状态
再看看CreatePage

这是一个表单填写页面, 为了提高表单填写体验, 这里划分为多个步骤; 每个步骤里有还有多个表单分组; 每个表单的结构都差不多, 左边是 label 展示, 右边是实际表单组件, 所以根据 UI 可以对组件进行这样的划分:
CreatePage
Steps # 步骤容器, 提供了步骤布局和步骤切换等功能
Step # 单一步骤容器
List # 表单分组
List.Item # 表单容器, 支持设置label
Input # 具体表单类型
Address
NumberInput
Select
FileUpload
组件命名的建议: 对于集合型组件, 一般会使用单复数命名, 例如上面的 Steps/Step; List/Item 这种形式也比较常见, 例如 Form/Form.Item, 这种形式比较适合作为子组件形式. 可以学习一下第三方组件库是怎么给组件命名的.
再看一下PreviewPage, PreviewPage 是创建后的数据预览页面, 数据结构和页面结构和 CreatePage 差不多. 将Steps 对应到 Preview 组件, Step 对应到 Preview.Item. Input 对应到 Input.Preview:

3️⃣ 设计组件的状态
对于 ListPage 来说状态比较简单, 这里主要讨论 CreatePage 的状态. CreatePage 的特点:
- 表单组件使用受控模式, 本身不会存储表单的状态. 另外表单之间的状态可能是联动的
- 状态需要在 CreatePage 和 PreviewPage 之间共享
- 需要对表单进行统一校验
- 草稿保存
由于需要在 CreatePage 和 PreviewPage 中共享数据, 表单的状态应该抽取和提升到父级. 在这个项目的实际开发中, 我的做法是创建一个 FormStore 的 Context 组件, 下级组件通过这个 context 来统一存储数据. 另外我决定使用配置的方式, 来渲染动态这些表单. 大概的结构如下:
// CreatePage/index.tsx
<FormStore defaultValue={draft} onChange={saveDraft}>
<Switch>
<Route path="/create/preview" component={Preview} />
<Route path="/create" component={Create} />
</Switch>
</FormStore>
// CreatePage/Create.tsx
<Steps>
{steps.map(i =>
<Step key={i.name}>
<FormRenderer forms={i.forms} /> {/* forms为表单配置, 根据配置的表单类型渲染表单组件, 从FormStore的获取和存储值 */}
</Step>
)}
</Steps>
8. 文档
组件的文档化推荐使用Storybook, 这是一个组件 Playground, 有以下特性
- 可交互的组件示例
- 可以用于展示组件的文档. 支持 props 生成和 markdown
- 可以用于组件测试. 支持组件结构测试, 交互测试, 可视化测试, 可访问性或者手动测试
- 丰富的插件生态
React 示例. 由于篇幅原因, Storybook 就不展开细节, 有兴趣的读者可以参考官方文档.
