

回顾
scrapy是一个非常强大的异步爬虫框架,组件丰富,我们只需要关注爬虫的逻辑即可。本文通过一个scrapy项目实战,来熟悉scrapy的使用
站点分析
目标站点:scrapy官方提供的抓取网站,主要是名人名言、作者标签之类的信息
流程框架
实现
进入命令行,切换到工程文件夹执行:
- scrapy startproject quote_tutorial
- cd quote_tutorial
- scrapy genspider quotes quotes.toscrape.com
- 打开pycharm,会发现如下图界面
其中一个文件的内容如下:
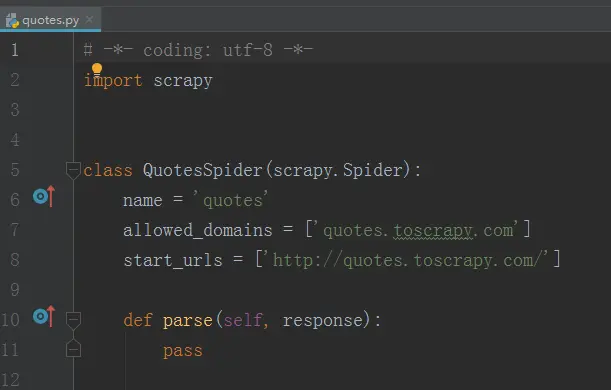
最主要的代码都会在spider目录下写
运行
网页分析和实现
我们需要的数据有:
- 名言内容
- 作者
- 标签
页面解析 数据结构定义好之后,我们需要进行页面解析也就是parse方法的编写:
scrapy调试 scrapy还提供了一个非常强大的根据:scrapy shell 可以从terminal输入:scrapy shell quotes.toscrape.com后面跟的是网址,之后就可以进入命令行交互模式下面,在这里进行一些调试
修改parse方法后运行 在修改parse方法后再在terminal中执行:scrapy crawl quotes 运行结果图:
翻页解析
上面已经完成了单个页面的解析,接下来就剩翻页问题了。翻页可以通过url来请求: quotes.toscrape.com/page/5/ 直接改变url中的页面数字即可完成翻页的请求,这个链接可以从response中获取:
加上翻页功能,完整的parse函数如下图所示:
如何保存结果呢?
scrapy crawl quotes -o quotes.json 在当前目录下会生成quotes.json文件,文件中就是爬取的数据:
- scrapy crawl quotes -o quotes.json:可以使用json.loads解析
- scrapy crawl quotes -o quotes.csv
- *scrapy crawl quotes -o quotes.txt
- *scrapy crawl quotes -o quotes.xml
- *scrapy crawl quotes -o quotes.jl:其实是json line格式:一行一行的存储
- 使用 -o输出结果到文件,通过文件名称后缀自动判断文件格式
- 另外还支持:pickle、marshal等后缀的文件格式
- 还支持远程保存:-o ftp://user:pass@ftp.example.com/path/quotes.csv
剩余工作
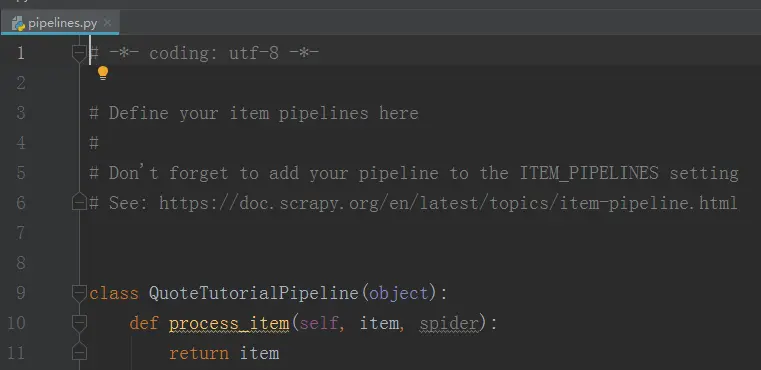
保存之前可以做一些其他操作,比如:过滤掉一些不合格的item数据。这个功能可以借助piplines.py文件完成。该文件的原始内容如下:
注意:可以定义多个pipline:比如写数据库之类的也可以使用pipline实现 pipline定义后需要在setting文件中配置,当前启用哪几个pipline
源码
上面给出了文章的核心代码分析,
扫描下方二维码,发送关键词“scrapy”即可获取本文的完整源码和详细程序注释
公众号专注:互联网求职面经、java、python、爬虫、大数据等技术、海量资料分享:公众号后台回复“csdn文库下载”即可免费领取【csdn】和【百度文库】下载服务;公众号后台回复“资料”:即可领取5T精品学习资料、java面试考点和java面经总结,以及几十个java、大数据项目,资料很全,你想找的几乎都有
