闲来无事,边理解PR曲线和ROC曲线,边写了一下计算两个指标的代码。在python环境下,sklearn里有现成的函数计算ROC曲线坐标点,这里为了深入理解这两个指标,写代码的时候只用到numpy包。事实证明,实践是检验真理的唯一标准,在手写代码的过程中,才能真正体会到这两个评判标准的一些小细节,代码记录如下。
一、模拟一个预测结果
因为两个曲线都是用来判断一个分类器分类性能的,所以这里直接用随机数生成一组类别和对应的置信度。类别有0、1两个类别。置信度从0到1随机生成。
data_len = 50
label = np.random.randint(0, 2, size=data_len)
score = np.random.choice(np.arange(0.1, 1, 0.01), data_len)
生成结果如下:其中第一行代表真实的类别,第二行代表分类器判断目标是类别1的置信度。
| label | 1 | 0 | 1 | 0 | 0 | 1 | 1 | …… |
|---|---|---|---|---|---|---|---|---|
| score | 0.22 | 0.31 | 0.92 | 0.34 | 0.37 | 0.18 | 0.51 | …… |
因为我们的置信度是随机生成的,所以得到的结果等同于一个二分类器“瞎猜”的结果。
二、PR曲线
不管是PR曲线还是ROC曲线,首先要选定一个类别,然后针对这个类别具体计算。
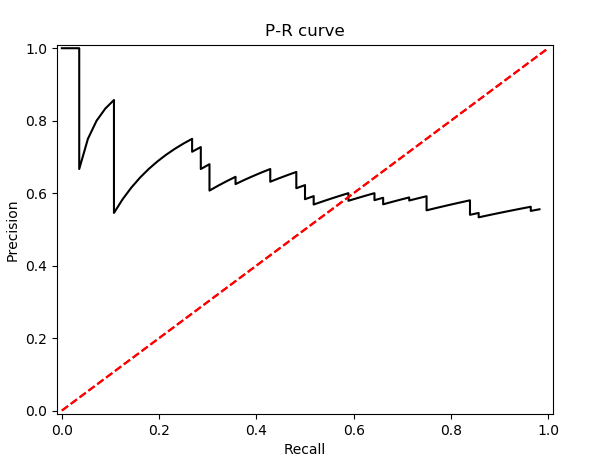
该曲线的横坐标是召回率(R),纵坐标是精确度(P),故命名为PR曲线。 举一个简单的例子来说明P和R的定义:假设一个二分类器需要预测100个样本,这些样本中有80个类别1,20个类别0。当把置信度取某一个值S时,假设此时分类器认为有60个样本是类别1,在预测的这60个人样本中,有50个样本预测正确,其余10个样本预测错误。那么,对于类别1的P、R值计算如下:
即有0.667的概率预测正确,对于80个类别1的样本,分类器好比可以召唤神兽的魔法师,养了80只神兽,只召唤回来50只。所以召回率就是62.5%,其他的就被无情丢弃了。
对于类别0来说,既然二分类器认为类别1的有60个,那么反过来其余40个都认为是类别0,通过上述可以推出这40个只有10个是类别0,其余的是类别1,所以对于类别0的P、R值计算如下:
根据以上说明代码实现如下:
def PR_curve(y,pred):
pos = np.sum(y == 1)
neg = np.sum(y == 0)
pred_sort = np.sort(pred)[::-1] # 从大到小排序
index = np.argsort(pred)[::-1] # 从大到小排序
y_sort = y[index]
print(y_sort)
Pre = []
Rec = []
for i, item in enumerate(pred_sort):
if i == 0:#因为计算precision的时候分母要用到i,当i为0时会出错,所以单独列出
Pre.append(1)
Rec.append(0)
else:
Pre.append(np.sum((y_sort[:i] == 1)) /i)
Rec.append(np.sum((y_sort[:i] == 1)) / pos)
print(Pre)
print(Rec)
## 画图
plt.plot(Rec, Pre, 'k')
# plt.legend(loc='lower right')
plt.title('Receiver Operating Characteristic')
plt.plot([(0, 0), (1, 1)], 'r--')
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 01.01])
plt.ylabel('Precision')
plt.xlabel('Recall')
plt.show()
画出的PR曲线:
三、ROC曲线
ROC曲线的纵坐标是TPR,横坐标是FPR(中文翻译太乱了,我还是习惯用英文表示)。TPR等同于PR曲线的召回率,FPR是所有被预测成正例的反例和真实反例的个数之比。
还是以上那个例子,对于·类别1,两者的计算如下:
def ROC_curve(y,pred):
pos = np.sum(y == 1)
neg = np.sum(y == 0)
pred_sort = np.sort(pred)[::-1] #从大到小排序
index = np.argsort(pred)[::-1]#从大到小排序
y_sort = y[index]
print(y_sort)
tpr = []
fpr = []
thr = []
for i,item in enumerate(pred_sort):
tpr.append(np.sum((y_sort[:i] == 1)) / pos)
fpr.append(np.sum((y_sort[:i] == 0)) / neg)
thr.append(item)
print(fpr)
print(tpr)
print(thr)
#画图
plt.plot(fpr, tpr, 'k')
plt.title('Receiver Operating Characteristic')
plt.plot([(0,0),(1,1)],'r--')
plt.xlim([-0.01,1.01])
plt.ylim([-0.01,01.01])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
结果如下:
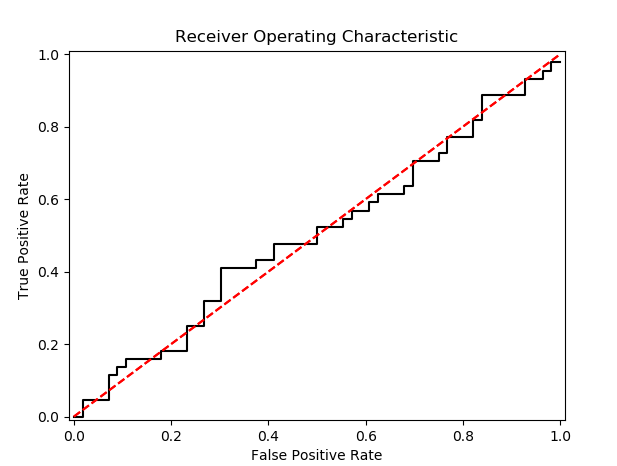
如果我们把随机生成的置信度只保留小数点后一位,那么数据里有很多相同置信度的值。这种方式每次计算出来的ROC曲线会稍微有些差异,取决于排序的结果。
附:
这几个值确实挺绕的,附一张公式表,便于搞混的时候查询:
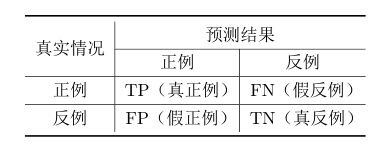
1)分类结果混淆矩阵