

在《理解交叉验证》一文中,我们谈到了使用 AUC 来对比不同模型的好坏,那么 AUC 是什么?它是如何衡量一个模型的好坏的呢?除了 AUC 以外,还有其他评估手段吗?本文我们就来探讨下这几个问题。
混淆矩阵
要了解 AUC,我们需要从另外一个概念——混淆矩阵(Confusion Matrix)说起,混淆矩阵是一个 2 维方阵,它主要用于评估二分类问题(例如:预测患或未患心脏病、股票涨或跌等这种只有两类情况的问题)的好坏。你可能会问多分类问题怎么办?实际上,多分类问题依然可以转换为二分类问题进行处理。下图是一个用于评判是否患有心脏病的混淆矩阵:
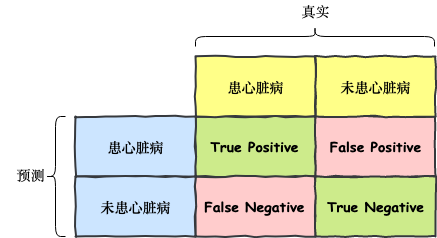
纵向看混淆矩阵,它体现了真实情况下,患病和未患病的人数,上图中,真实患心脏病的人数为 True Positive + False Negative,未患心脏病的人数为 False Positive + True Negative;类似的,横向看混淆矩阵,它体现了模型预测出来患心脏病的人数为 True Positive + False Positive,而预测未患心脏病的人数为 False Negative + True Negative。
两个方向一起看,预测患病且实际也患病,我们称它为真阳性 (True Positive),预测未患病且实际也未患病,被称为真阴性 (True Negative),这两个区域是模型预测正确的部分;模型预测错误也分两种情况,假阳性 (False Positive) 表示预测患病,但实际却未患病,假阴性 (False Negative) 表示预测未患病,但实际却患了病的情况。
概念有点多,但并不难记,可以看到,这些名词都是围绕着预测来命名的——预测患病时被称为「True/False Positive」,预测未患病时被称为 「True/False Negative」。
上图中,模型预测正确的部分用绿色填充,它所占的比例又被称为准确率 (Accuracy):
单靠准确率这一项,并不足以评估模型的好坏,例如下面这种情况,虽然准确率可以达到 80%,但在实际患病的人群中,该模型的预测成功率只有 50%,很明显它不是一个好模型。
| 患心脏病 | 未患心脏病 | |
|---|---|---|
| 患心脏病 | 10 | 10 |
| 未患心脏病 | 10 | 70 |
Sensitivity 和 Specificity
所以,我们需要引入更多的衡量指标,Sensitivity (或 Recall) 表示实际患者中,预测患病成功的概率,同时 Sensitivity 这个词也有"过敏"的意思,和患病对应,这样关联起来比较好记:
既然有衡量患病(正样例)的指标,那肯定也有衡量未患病(负样例)的指标,Specificity 就是用来表示实际未患病的人群中,预测未患病成功的概率,即
Specificity 这个词有"免疫"的意思,能和未患病相关联,所以也很好记。
这两个指标的出现,能更好的帮你比较模型间的差异,并在其中做出取舍。例如当两个模型的 Accuracy 相近时,如果你更看重于预测患病的效果,你应该选 Sensitivity 值较高的;相反,如果你更看重于预测未患病的效果,你就应该选择 Specificity 较高的。
ROC 曲线、AUC 和 F1 Score
更进一步,我们还可以通过将这些指标图形化,以获得更直观的评估结果,ROC (Receiver Operating Characteristic) 曲线就是其中常用的一种。
我们知道,分类模型(例如"逻辑回归”)的结果是一个大于 0 且小于 1 的概率,此时我们还需要一个阈值,才能界定是否患病,通常我们把阈值设为 0.5,这样当结果大于 0.5 时可判定为患病,否则判定为未患病。
而阈值可以取 0 到 1 之间的任意一个值,对每一个阈值,都有一个混淆矩阵与之对应,有了混淆矩阵,我们就可以求出一对 Sensitivity 和 Specificity,通过这两个数,我们就可以在一个以 1-Specificity 为横坐标,Sensitivity 为纵坐标的坐标系上画一个点,把所有可能的阈值所产出的点连起来,就是 ROC 曲线。
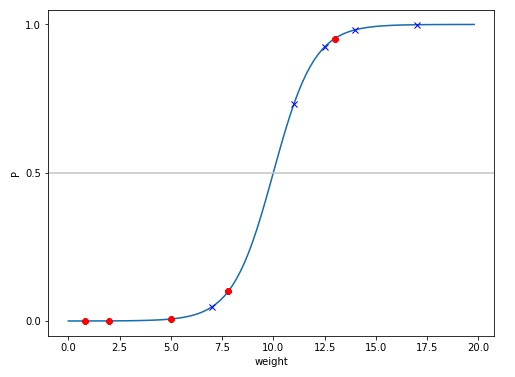
下面我们来看一个具体的例子,假设我们对老鼠做研究,希望通过老鼠的体重来预测其患心脏病的概率,我们采用逻辑回归算法来建模,下图是预测结果,图中有 10 个老鼠样本点,其中红色点代表实际健康的老鼠,蓝色点代表实际患病的老鼠,这些点用一条逻辑回归曲线拟合,图中还有一条 P=0.5 的直线用来表示阈值为 0.5,可以看出,高于 P=0.5 的 5 只老鼠被预测为患病,而其他 5 只老鼠被预测为健康,预测成功率(Accuracy)为 80%:
下面我们通过以上数据,来画一条 ROC 曲线。首先取阈值为 1,此时所有的老鼠都被预测为未患病,根据样本真实患病情况,我们可以得到如下混淆矩阵
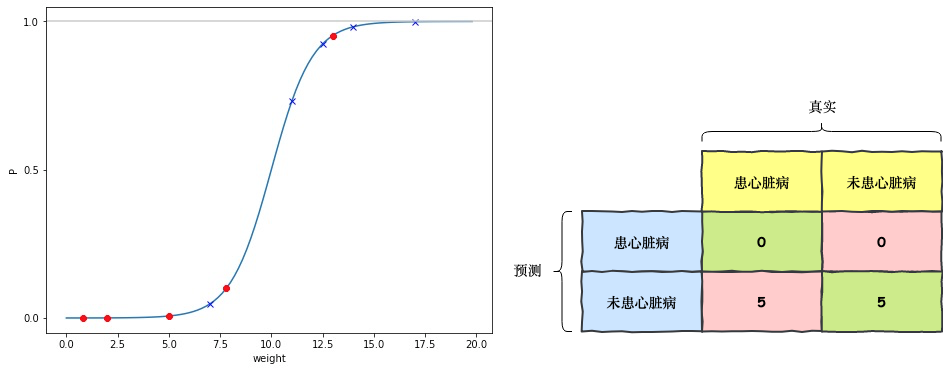
根据上述混淆矩阵,我们就可以算出一组 Sensitivity 和 Specificity 的值。接着我们不断调整阈值,以获得所有的 Sensitivity 和 Specificity 对,因为这里我们的样本点较少,所以让阈值根据样本点来采样即可,依然用横线表示阈值,则所有阈值的采样情况如下:
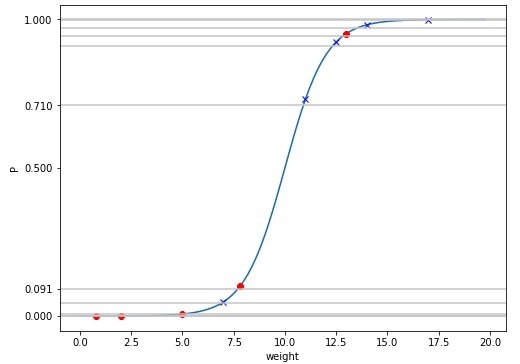
我们把这些阈值对应的混淆矩阵都列出来:
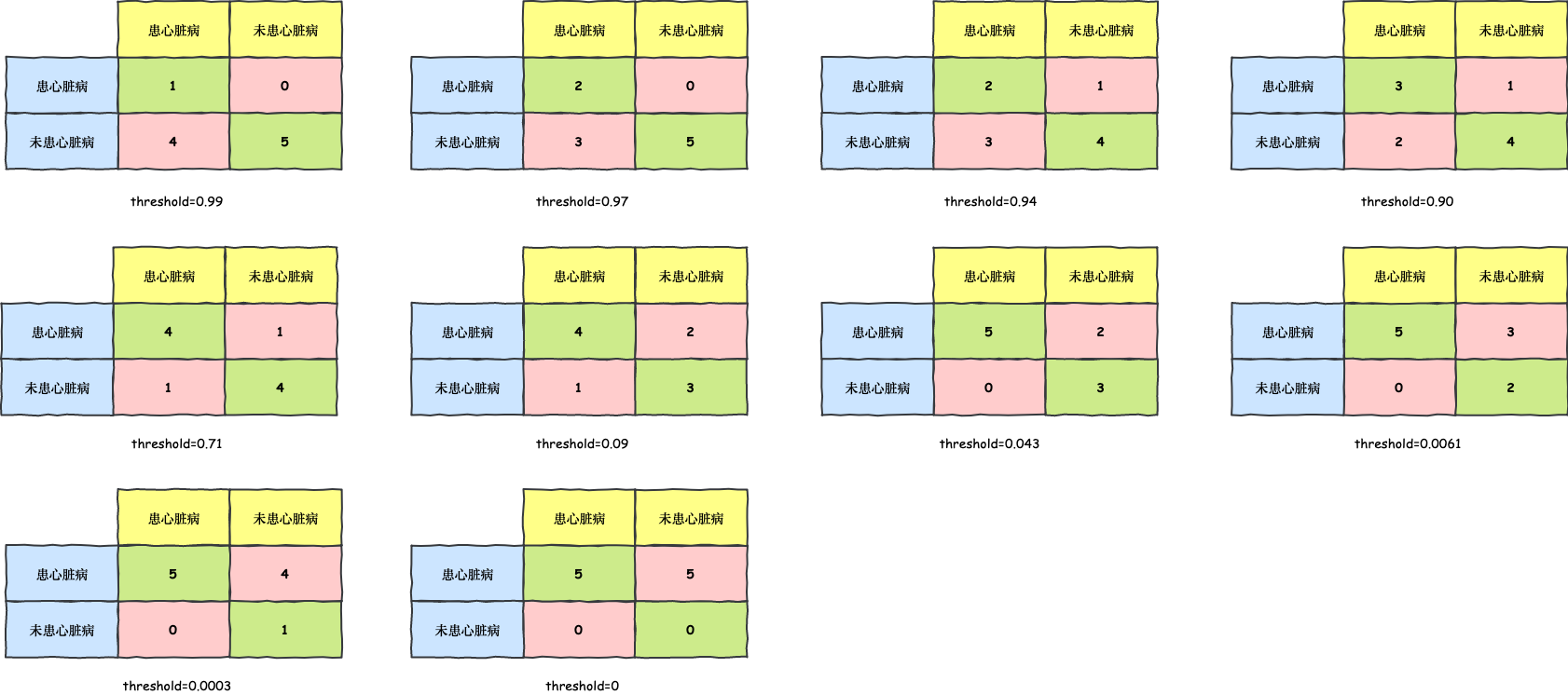
然后,计算这些混淆矩阵对应的 Sensitivity 和 1-Specificity:
| Threshold | Sensitivity | 1- Specificity |
|---|---|---|
| 1 | 0 | 0 |
| 0.99 | 0.2 | 0 |
| 0.97 | 0.4 | 0 |
| 0.94 | 0.4 | 0.2 |
| 0.90 | 0.6 | 0.2 |
| 0.71 | 0.8 | 0.2 |
| 0.09 | 0.8 | 0.4 |
| 0.043 | 1.0 | 0.4 |
| 0.0061 | 1.0 | 0.6 |
| 0.0003 | 1.0 | 0.8 |
| 0 | 1.0 | 1.0 |
根据该表格,以 1-Specificity 为横轴,Sensitivity 为纵轴作图,通常,在画 ROC 曲线时,我们把 1-Specificity 对应的坐标轴记为 FPR (False Positive Rate),把 Sensitivity 对应的坐标轴记为 TPR (True Positive Rate),如下:
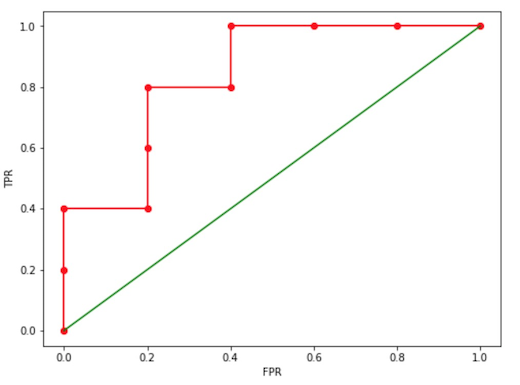
ROC 曲线有以下特点:
- 从 (0, 0) 点到 (1,1) 点的对角线上的每个点,意味着在患者中,预测患病成功的概率(TPR),与未患病者中,预测未患病失败的概率(FPR)相等,对于模型来说,TPR 越大越好,FPR 越小越好,所以我们需要尽可能的使 ROC 曲线沿左上角方向远离该对角线。
- ROC 曲线还可以帮助我们选择合适的阈值,即 TPR 相同的情况下,ROC 上的点越靠左,效果越好,因为越靠左,意味着 FPR 越小。
根据 ROC 曲线的第 1 个特点:「曲线越靠近左上角,模型的效果越好」,意味着一个更好模型,其曲线下方的面积更大,我们把 ROC 曲线下方的面积称为 AUC (Area Under Curve),有了这个概念后,只需一个数值就可以衡量模型的好坏了,上面示例模型的 AUC 如下:
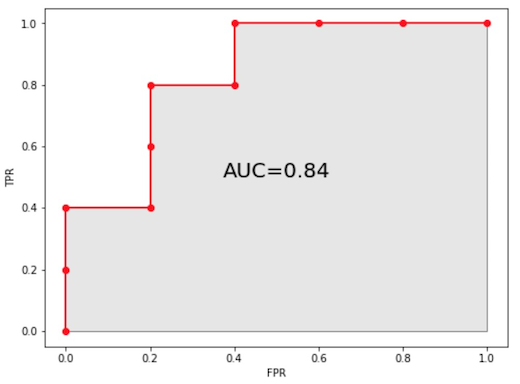
通常情况下我们都使用 AUC 来评估模型,既然是”通常”,那肯定就有例外:当患病率 (或正样本占比) 非常小时,Ture Negative 就会非常大,这个值就会使影响 FPR,使 FPR 较小,为了避免这种影响,我们可以将 FPR 用另一个指标代替:Precision
Precision 的含义是预测患病的样本中,实际也患病的比例;这样,将 Precision 和 Sensitivity 结合起来,会让我们更专注于患病 (正样本) 的预测效果,而机器学习中的另一个效果指标:F1 Score,就是专门负责这件事儿的
上面的公式中,Recall 等价于 Sensitivity,和 AUC 一样,两个模型互相比较,F1 Score 越大者,预测效果越好,而且 F1 Score 能更好的衡量正样本的预测效果。
总结
本文通过一个医学例子——是否患心脏病——来讲述什么是混淆矩阵、ROC 曲线、AUC 及 F1 Score,其中,我们还一起学习了 ROC 曲线是如何画出来的,最后,我们还谈到了 AUC 和 F1 Score 以及它们之间细微的差别。
需要注意的是,二分类评估并不限于对患病及未患病这两种情况的分类,考虑到通用性,你完全可以将本文中的患心脏病替换为正样本、把未患心脏病替换为负样本。
