

如需讲解视频,请关注我的个人微信公众号:小纸屑
麻烦大家给我点个赞,就是那种让我看起来,写的还不错的样子!😁😁😁😁😁
YOLOv1是继Faster R-CNN后,第一个one stage物体检测算法,开创了物体检测算法一个全新流派,自YOLOv1后,物体检测基本分为one stage和two stage两个流派。
下图是YOLO在整个物体检测算法历史上的坐标。
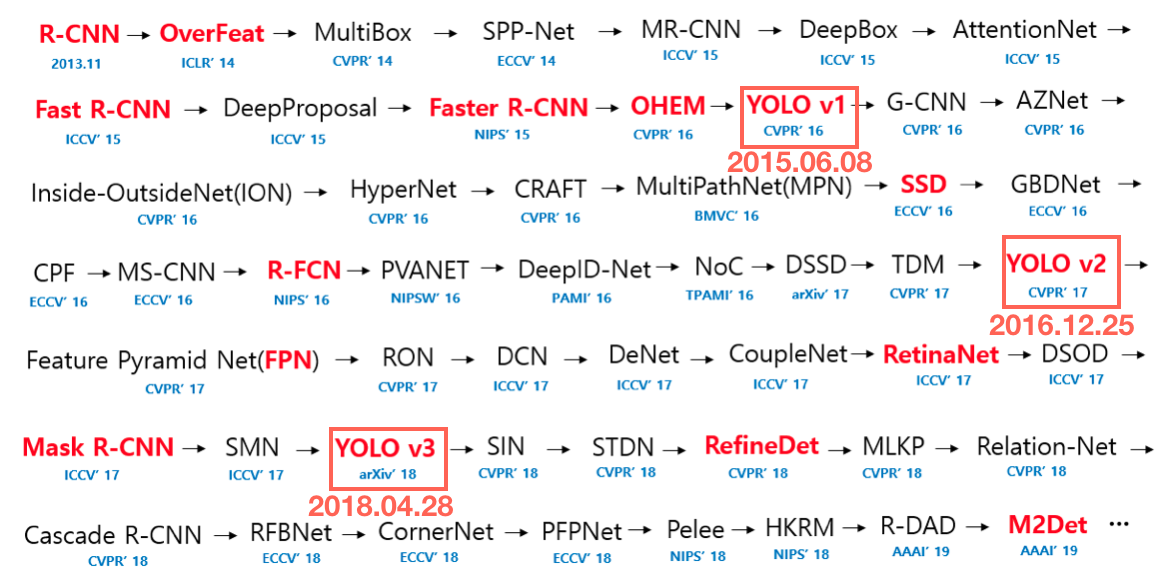
背景
可以看出,YOLOv1是在Faster R-CNN之后提出的,但查看首次上传arXiv的时间可知(见下图),YOLOv1和Faster R-CNN基本是同时提出的,因此YOLO作者动笔之时,Fast R-CNN是SOTA(state of the art),Faster R-CNN尚未出世,因此YOLO作者的主要对比对象是Fast R-CNN。当然,作者后续还是补充了与Faster R-CNN的对比结果做参考。
下面简单分析下Fast R-CNN的原理。
Fast R-CNN主要由四部分组成(如下图),首先是共用的Feature Extractor,然后是传统的Region Proposal算法,有了共用的Extracted Feature Map和ROI(Region Of Interest)后,将Extracted Feature Map上对应ROI部分截取出来,经过ROI Pooling,转成分辨率固定的Feature Map,输入到物体检测部分,以回归物体类别和bounding box,完成整个物体检测流程。
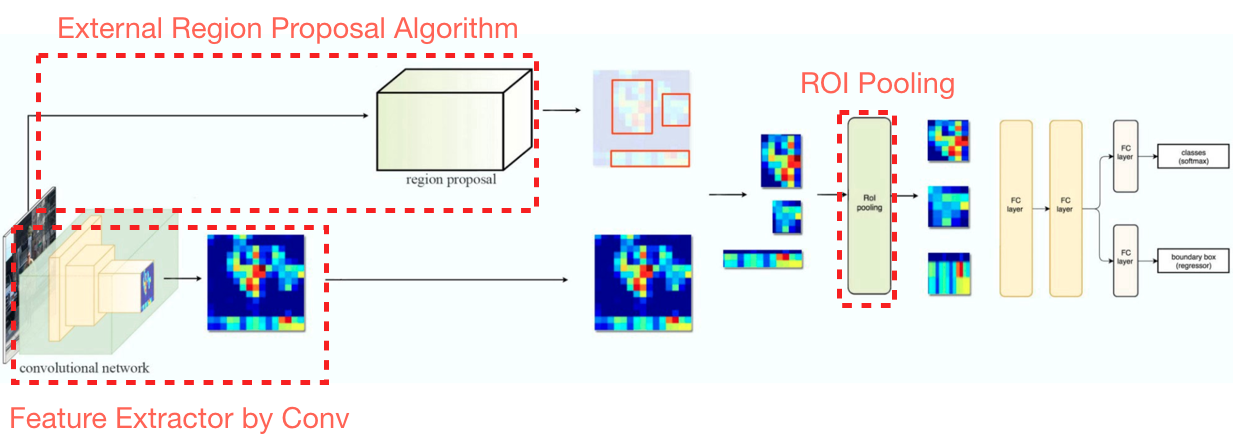
由于Fast R-CNN分为Extract Feature和Region Proposal两个过程,因此是two stage的,这导致了Fast R-CNN的常常准确度高,但速度做不到实时性。
YOLO的提出就是解决Fast R-CNN的缺点,将two stage合成为一个stage,从而达到实时性。
Idea
具体YOLO是如何将two stage合成为一个stage的呢?
1)首先,将输入图片划分为7x7的网格

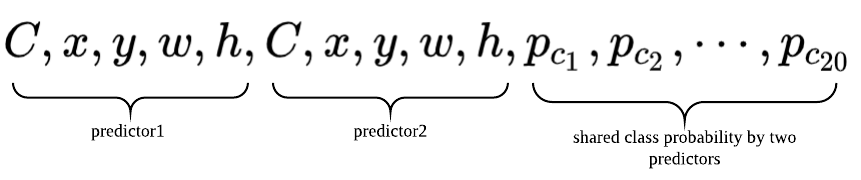
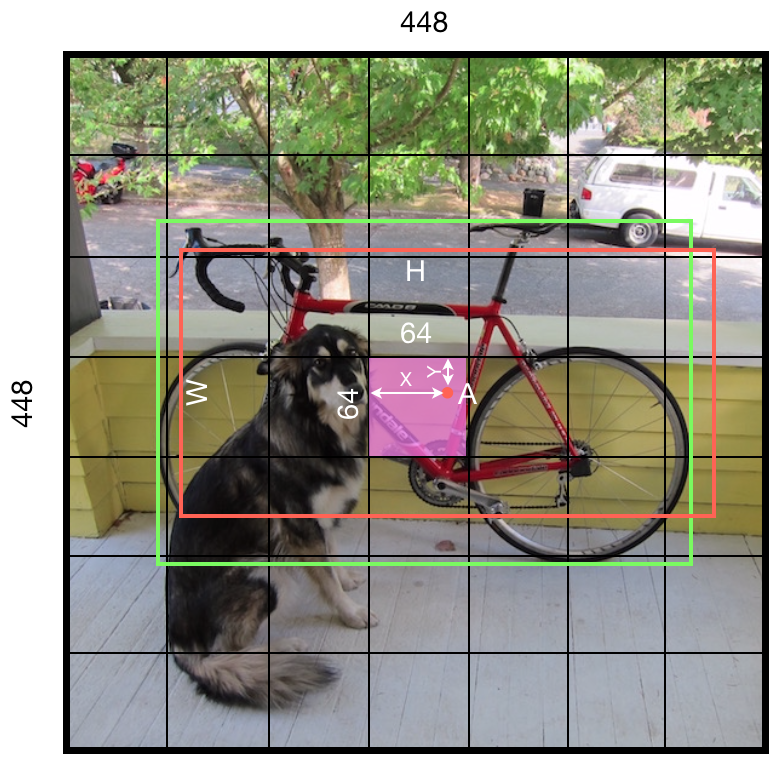
可以看出,一个cell预测两个框,但输出的时候只能输出一个预测结果,一般取置信度C值大的那个预测框作为这个cell的预测结果,框的类别取p_ci最大的类别。 3)既然一个cell有两个预测框,那每个预测框的Ground Truth怎么计算呢? 首先,一个Ground Truth框分配给其center所在的cell,如下图,自行车的绿色Ground Truth框分配给粉色的cell,

其次,在一个cell内部,Ground Truth会分配给与其IOU最大的predictor,如下图,粉色cell中的两个预测框是红色框,绿色GT框会分配给宽矮的红色预测框。

有了输出,有了GT,再设计设计网络结构,即输入到输出的映射,就可以利用梯度下降进行训练了。
Network
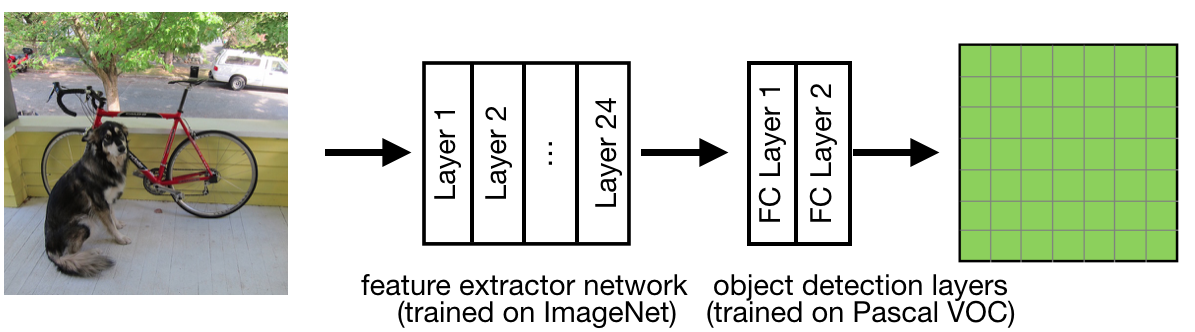
下图是简化版的网络结构,
下图是详细的网络结构,
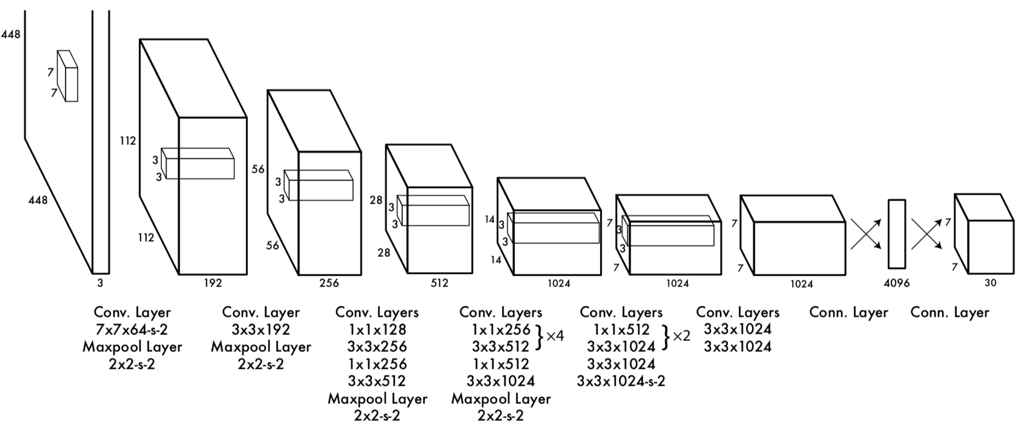
可以看出,图片先经由一个作者设计的24层的Feature Extractor,提取特征,然后再经过两个全连接层,就得到最后7x7x30的输出。
需要注意的是,这个7x7的输出的意义就是作者说的将网格划分为7x7的网格。
Loss
Loss主要分为三个部分,位置损失、置信度损失和类别损失。

1)位置损失
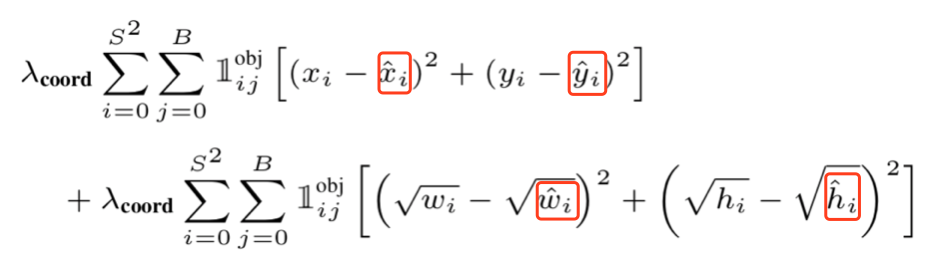
2)置信度损失

Ci预测的是Pr(object)*IOU,综合反映了预测框有object的概率和预测框与truth的IOU大小。 所以对于一个cell的C_i的标签的计算方法是:

3)类别损失
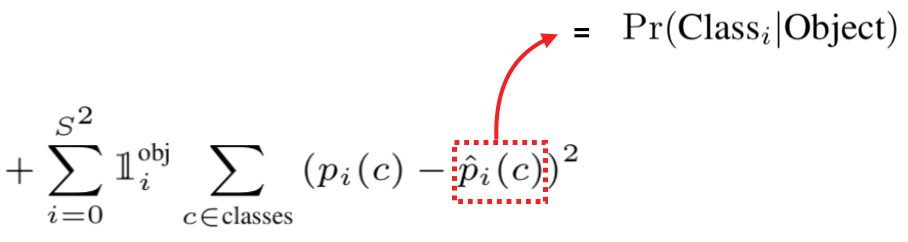
预测的p_ci是条件概率,即Object已知的情况下,Class_i的概率,如果GT的类别是ci,则p_ci的标签是1,其他p_ci的标签为0。
Training
YOLO模型训练采用了以下技巧: 1)数据增强 包括随机缩放,随机截取,随机调整曝光度和饱和度 2)dropout 估计是全连接层,使用了dropout,dropout rate取0.5 3)优化器 采用momentum优化器,超参数beta取0.9 4)weight decay 采用了权重衰减,系数为0.0005 5)batch size为64 6)learning rate

Experiments
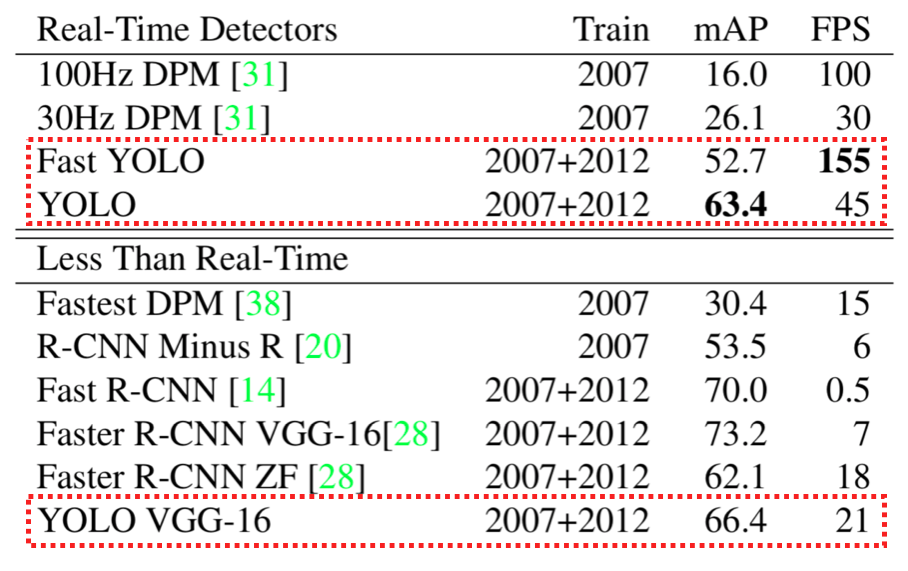
Error Analysis
作者还对YOLO进行了误差分析,对比了Fast R-CNN与YOLO的误差来源。 首先作者将识别结果分为五类:
- 正确分类:类别正确,IOU>0.5
- 位置错误:类别正确,0.1<IOU<0.5
- 近似错误:类别识别为近似类别,IOU>0.1
- 其他错误:类别错误,IOU>0.1
- 背景错误:IOU<0.1
Fast R-CNN与YOLO的误差组成如下图:
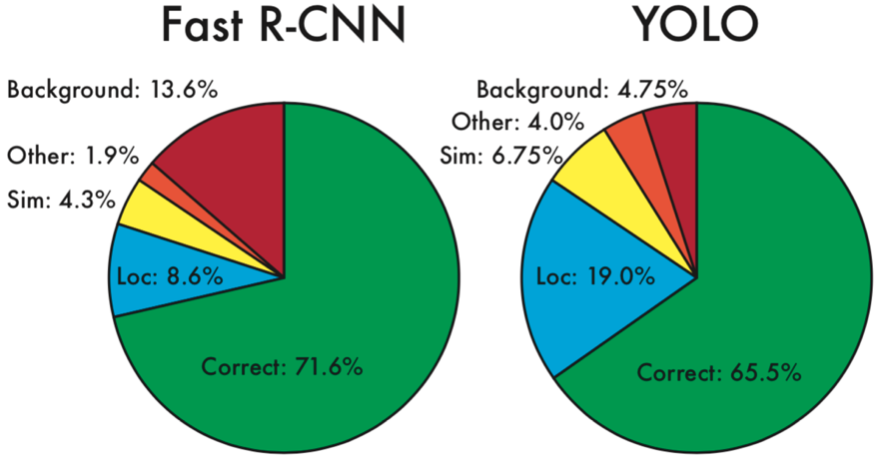
可以看出,Fast R-CNN以背景错误为主,YOLO以位置错误为主。
结论
YOLO开创性的提出了一步式算法,做到了实时检测和高准确率。
