

?
面试被问到了这个问题, 恰好最近把个人博客的SEO问题解决了, 想来解决方案还算比较合理, 做个分享.
1. 单页应用常用SEO方案
1.1 服务端渲染重构
好处:
- 可以说是一劳永逸
坏处:
- 灵活性不足: 这类框架要改的话就要全部按照他的做法来改, 即便不需要SEO的页面, 也需要全部迁移过去
- 时间成本巨大: 新框架熟悉, 不断采坑会浪费太多时间
- 打包部署方案也得变
- 增加了服务器压力: 又要渲染页面了
总之就是: 侵入性强, 无法短时间内完成, 不适合中途切换, 在一开始确定是最好的, 除非你铁了心要重构.
1.2 预渲染
原理: 启动一个无头浏览器, 加载应用程序的路由, 将结果保存到静态HTML文件中
适合:
- 内容不会发生变化的页面: 例如营销页面以及广告页面
不适合:
- 内容会变化的页面: 像博客这种- -是不行的, 因为内容在编译后就确定了, 再修改内容, 也不会有变化
优点:
- 代码侵入少: 安装一个plugin, 指定路由即可
缺点:
- 覆盖范围少: 几乎只适合静态页面
- 路由(页面)较多时构建时间长
- 不科学上网phantomjs下不下来: 当时踩的坑, 转头就捣鼓梯子去了
总之就是: 能解决部分问题, 但还不够
1.3 给爬虫开小灶
这种方案灵活性比较强, 没有可以立马npm install就用的库, 只有大体的解决方向
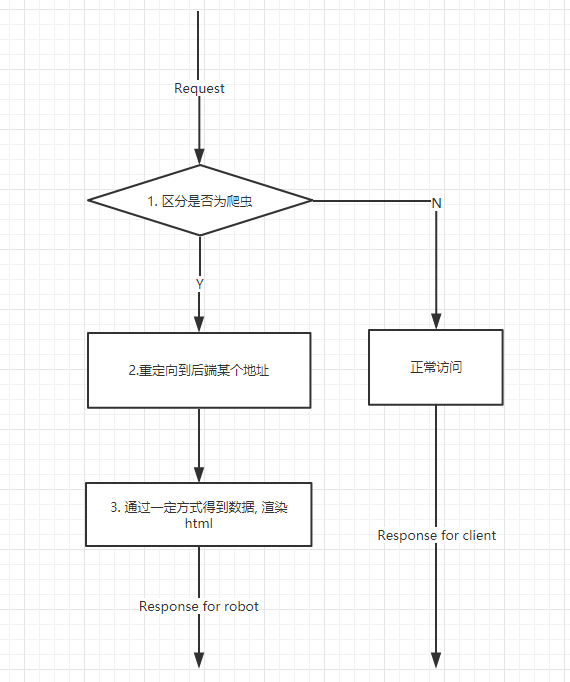
主要步骤见下
2. 实践给爬虫开小灶
2.1 在请求代理服务器中判断是否为爬虫
这一步至关重要的就是:
- 有调整
NginxorApache等请求代理服务器配置的权限 - 没有的话, 就需要有一个配合你的运维
- 实在不行你用
Node判断吧
再没有的话, 右上角点✖
以Nginx为例, 通常使用history API的项目部署的时候, 都会加上这样的配置
location / {
try_files $uri $uri/ /index.html;
}
正好, 判断是否为爬虫的代码也在此处~, 就只列出百度和谷歌的爬虫头了
location / {
if ($http_user_agent ~* "Baiduspider|Googlebot") {
rewrite ^(.*)$ /robot$1 break;
proxy_pass http://127.0.0.1:3000;
}
try_files $uri $uri/ /index.html;
}
可以看到对于爬虫请求, 改写了请求地址, 将其转发到后端接口
以博客为例, 爬虫请求文章地址为: /Calabash/articles/20190421145534, 实际处理这个请求的是宿主机127.0.0.1:3000/robot/Calabash/articles/20190421145534
代理地址就是后端开小灶的router地址
2.2 后端部分
示例代码为Express
注册一个router, 专门处理爬虫的请求
app.use('/robot', robotRouter)
在controller中自定义处理方案
// 对于文章的请求
router.get('/:userName/articles/:blogDate', robotController.renderArticle)
// 对于文章列表的请求
router.get('/:userName', robotController.renderIndex)
// default
router.use(robotController.renderIndex)
renderArticle中到底用什么方案来获得HTML, 就要根据需要来了~, 简单的就是查数据 -> 渲染模版啦
async renderArticle(req, res) {
const { userName: author, blogDate } = req.params
const blogInfo = await blogModel.findOne({ author, blogDate })
if (!blogInfo) return res.status(404).send('Sorry, we cannot find that!')
// 文章内容为markdown格式
const { blogContent, blogTitle: title } = blogInfo
const content = marked(blogContent)
return res.render('article', { title, content, author })
},
渲染模版
html
head
meta(charset="utf-8")
meta(name="description" content="前端技术博客")
meta(name="author" content=author)
title= title
body
h1= title
article !{content}
2.3 方案小结
优点
- 前端代码, 构建, 部署不需要改动: 仅需要修改一点配置文件 + 后端处理
- 覆盖范围广: 不管页面是否常变动, 都可用
- 变动的内容通常请求接口, 然后渲染模版
- 不变动内容, 直接拿模版
- 时间耗费少: 顺理成章哦
缺点
- 需要SEO页面较多的时候, 需要设定的模版也不少: 会增加一些工作量, 当然和全部重构比还好
不确定搜索引擎的防作弊机制是否会制裁: 爬虫内容与正常访问内容差异会比较大, 没找到具体规则, 看见有这个说法.
2.4 效果对比
before
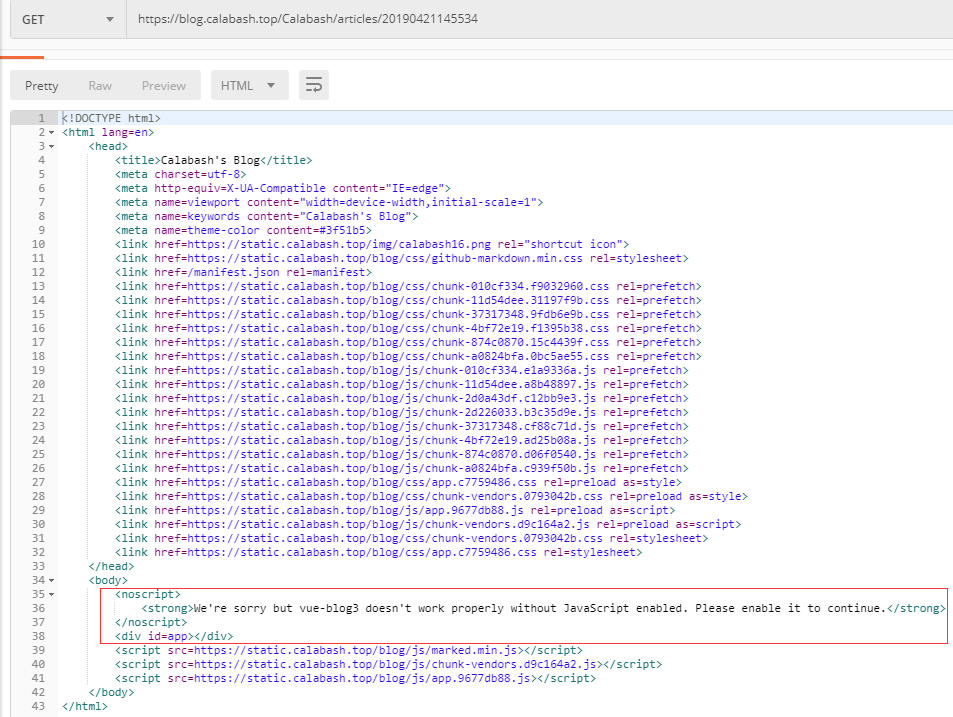
after
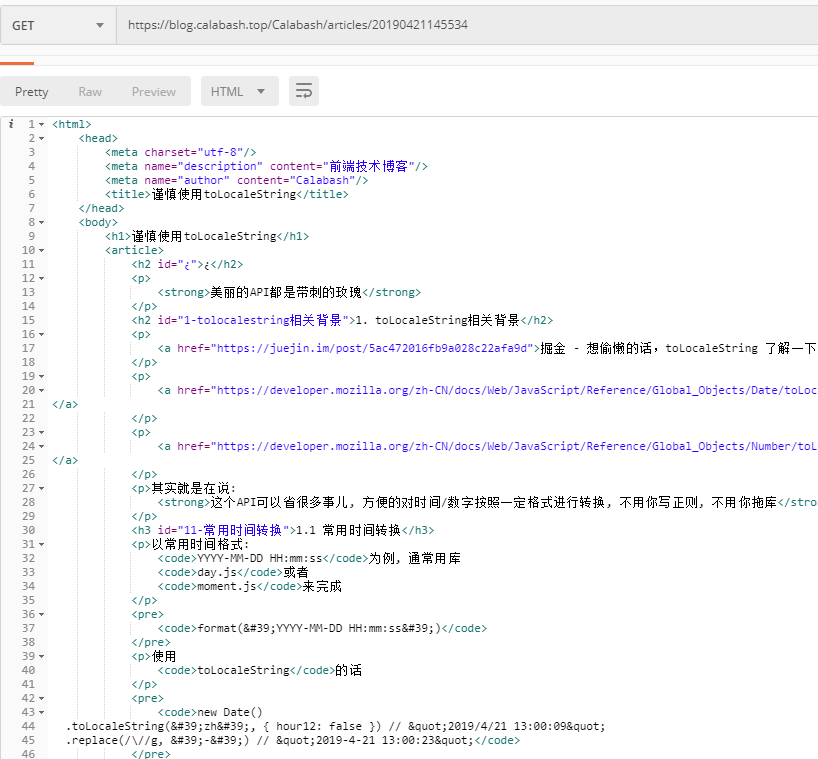
3. 总结
一开始就上SSR当然美滋滋, 中途切换开发成本就太高了, 个人认为参考覆盖范围和开发时间两个因素, 给爬虫开小灶是性价比最高的~
