


本文的开始源于落地页项目中遇到的 Chrome 控制台 warn 提示,担心影响页面渲染,特此弄个究竟。提示如下,
Cross-Origin Read Blocking (CORB) blocked cross-origin response https://www.example.com/example.html with MIME type text/html. See https://www.chromestatus.com/feature/5629709824032768 for more details.
除非特殊说明,否则本文中的浏览器均指 Chrome Browser。
前言
本文将从以下几个方面对 CORB 进行探讨,
- 什么是 CORB
- 为什么会产生 CORB
- 什么情况下会出现 CORB
- 出现 CORB 时,我们可以如何看待
CORB 发生时浏览器表现
CORB 是一种判断是否要在跨站资源数据到达页面之前阻断其到达当前站点进程中的算法,降低了敏感数据暴露的风险。
- Chrome 浏览器提示
当请求发生 CORB 时,浏览器控制台会打印如下警告内容,

Cross-Origin Read Blocking (CORB) blocked cross-origin response https://www.example.com/example.html with MIME type text/html. See https://www.chromestatus.com/feature/5629709824032768 for more details
在 chrome 66或这个版本之前,提示信息有细微不同,
Blocked current origin from receiving cross-site document at https://www.example.com/example.html with MIME type text/html
当请求的响应结果本身就出错或为空时,早期版本 Chrome 依旧会出现上述提示,但 Chrome 69 之后的版本不再出现上述提示。下文实验一和实验二验证了该描述。
- Chrome 浏览器行为
The response body is replaced with an empty body. // 响应数据置为空
The response headers are removed. // 移除响应请求头
CORB 启动时,虽然响应结果会被置空,但是请求的服务仍然成功,`status: 200`。比如:使用 `img` 标签上报页面监控数据,尽管响应结果为空,但请求依旧发送成功,服务器亦正常响应。下文实验一已验证。
为什么会有 CORB 的出现?
简单来说,就是出现了一些网络安全漏洞,为防止漏洞肆虐,便出现了站点隔离(Site Isolation),CORB 则是其中的一种实现策略。
Spectre 和 Meltdown 漏洞
当恶意代码和正常站点存在于同一个进程时,恶意代码便可以访问进程内的内存,进行一系列访问攻击,此时,恶意代码窃取数据的唯一难点在于不知道敏感数据的具体存储位置,但通过 CPU 预执行 和 SCA 可以一步步 试探 出来。详细了解可参看: zhuanlan.zhihu.com/p/32784852
什么是 CPU 预执行?
if(condition)
do_sth();
CPU 执行速度大于内存读取速度,为了提升 CPU 使用率,在从内存中读取 condition 完成之前,CPU 就已经开始执行下文内容。即不管 if 条件是否返回 true,CPU 都会提前执行里面的语句do_sth()。 CPU 预执行是芯片制造者决定的,为了提升 CPU 使用速度和效率而建的,预执行红利不是轻易就能放弃的,因此,目前或短期来看基本没可能改变。
普通浏览器中,不同的站点可能共享同一个进程
在某些情况下,没有实现 Site Isolution 的普通浏览器会出现一个进程里面同时运行多个站点的代码,这就让恶意站点有机可乘。比如恶意站点 a.dd.com 在自己的代码中嵌入 <iframe src="https://v.qq.com" frameborder="0"></iframe>,这时,普通浏览器就会把带有恶意站点 a.dd.com 的恶意代码 和 v.qq.com 放在同一个内存中运行。
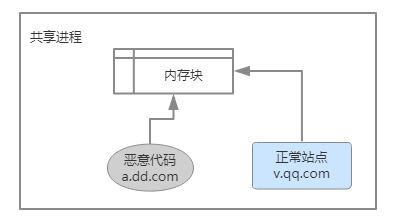
SCA(Side-Channel Attacks) 旁道攻击
简单来说,就是利用程序运行时,系统产生的一些物理特征(如:时延,能耗,电磁,错误消息,频率等)进行推测型攻击。看起来有点不可思议,但早在 1956 年,英国已经利用 SCA 获取了埃及驻伦敦的加密机。
缓冲时延(Cache Timing)旁路是通过内存访问时间的不同来产生的旁路。假设访问一个变量,这个变量在内存中,这需要上百个时钟周期才能完成,但如果变量访问过一次,这个变量被加载到缓冲(Cache)中了,下次再访问,可能几个时钟周期就可以完成了,可根据这种访问速度窃取特定数据。Spectre 和 Meltdown 漏洞便是利用了这种特性。
如何预防 Spectre 和 Meltdown 漏洞呢?
漏洞三大关键点是 CPU 预执行、SCA 和 共享进程。预防就得从这三个方面着手。先看 SCA,算法运行时间的变化本质就是源于数据处理,根据时间变化推测运算操作和数据存储位置,因此 SCA 可预防性极低。再看 CPU 预执行,性能至少提高 10%,一片可观的红利,芯片厂商如何舍得放弃。如此,只能针对共享进程下手了,Site Isolation 便是剥离共享进程的一项技术,采用独立站点独立进程的方式实现,降低漏洞的威胁。
Site Isolation
站点隔离保证了不同站点页面始终被放入不同的进程,每个进程运行在一个有限制的沙箱环境中,在该环境中可能会阻止进程接收其它站点返回的某些特殊类型敏感信息,恶意站点不再和正常站点共享进程,这就让恶意站点窃取其它站点的信息变得更加困难。从 Chrome 67 开始,已默认启用 Site Isolation。
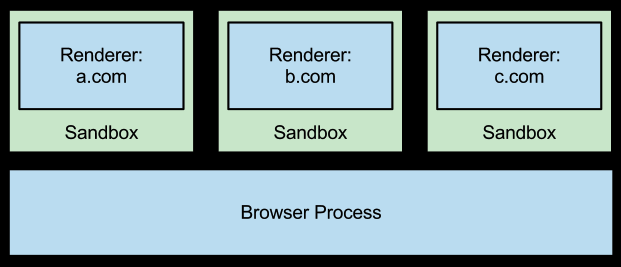
经验证,Site Isolation 关于进程独立的原则是 只要一级域名一样,站点实例就共享一个进程,无论子域名是否一样。如果使用 iframe 嵌入了一级域名不一样的跨域站点,则会生成一个新的进程维护该跨域站点运行,这一点同前文介绍的普通浏览器共享进程不同。更详细的内容参看 www.yaoyanhuo.com/blog/site_i…
这是 Site Isolation 的进程设计,那么其中的 CORB 扮演了什么角色呢?
在同源策略下,Site Isolation 已经很好地隔离了站点,只是还有跨域标签这样的东西存在,敏感数据依旧会暴露,依旧会进驻恶意站点内存空间。
有这样一个场景,用户登录某站点 some.qq.com后,又访问了 bad.dd.com 恶意站点,恶意站点有如下代码,<script src="some.qq.com/login">,跨域请求了原站点的登录请求,此时,普通浏览器会正常返回登录后的敏感信息,且敏感信息会进驻 bad.dd.com 内存空间。好不容易站点隔离把各个站点信息分开了,这因为跨域又在一起了。咋整?CORB 来了。CORB 会在敏感信息到达 web apge 之前,将其拦截掉,如此,敏感信息既不会暴露于浏览器,也不会进驻内存空间,得到了很好的保护。
CORB 发生时机
当跨域请求回来的数据 MIME type 同跨域标签应有的 MIME 类型不匹配时,浏览器会启动 CORB 保护数据不被泄漏,被保护的数据类型只有 html xml 和 json。很明显 <script> 和 <img> 等跨域标签应有的 MIME type 和 html、xml、json 不一样。
MIME type (Multipurpose Internet Mail Extensions)
MIME type 同 CORB 有着相当紧密的关系,可以说 CORB 的产生直接依附 MIME 类型。因此,阅读本文前,有必要先理解一下什么是 MIME type。
MIME 是一个互联网标准,扩展了电子邮件标准,使其可以支持更多的消息类型。常见 MIME 类型如:text/html text/plain image/png application/javascript ,用于标识返回消息属于哪一种文档类型。写法为 type/subtype。
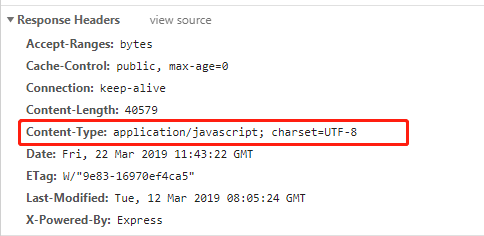
在 HTTP 请求的响应头中,以 Content-Type: application/javascript; charset=UTF-8 的形式出现,MIME type 是 Content-Type 值的一部分。如下图,
内容嗅探技术(MIME sniffing)
内容嗅探技术是指 当响应头没有指明 MIME type 或 浏览器认为指定类型有误时,浏览器会对内容资源进行检查并执行,来猜测内容的正确MIME类型。嗅探技术的实现细节,不同的浏览器在不同的场景下有不同的方式,本文不做详述。详细内容参见:www.keycdn.com/support/wha…
如何禁用 MIME sniffing 呢?
服务器在响应首部添加 X-Content-Type-Options: nosniff,用来告诉浏览器一定要相信 Content-Type 中指定的 MIME 类型,不要再使用内容嗅探技术探测响应内容类型。该方法仅对 <script> 和 <style> 有效。
官方解释:developer.mozilla.org/en-US/docs/…
浏览器如何判断响应内容是否需要 CORB 保护?
这可能是本文最需要关心的内容了,到底什么情况下会出现 CORB 。在满足跨域标签(如:<script>,<img>)请求的响应内容的 MIME type 是 HTML MIME type 、 XML MIME type、JSON MIME type 和 text/plain 时,以下三个条件任何一个满足,就享受 CORB 保护。(image/svg+xml 不在内,属图片类型)
- 响应头包含
X-Content-Type-Options: nosniff - 响应结果状态码是
206 Partial Content(developer.mozilla.org/zh-CN/docs/… - 浏览器嗅探响应内容的 MIME 类型结果就是 json/xml/html
这种嗅探用于防止某些内容因被错误标记 MIME 类型 而被 CORB 阻断不能正常响应返回,且该嗅探基于 Content-Type 进行,比如类型是 text/json,便只会对内容进行 json 类型检查,而不会进行 xml 或 html 的检查。
HTML MIME type 、 XML MIME type、JSON MIME type 的出现能理解,为什么 text/plain 类型也会在保护范围内?
因为 当 Content-Type 缺失的时候,响应内容 MIME type 有可能就是 text/plain;且据可靠数据显示, HTML, JSON, or XML 有时候也会被标记为 text/palin。如,
data.txt
{
"ret_code": 0,
"msg": "请求成功!",
"data": [1, 2, 3, 4, 5]
}
server.js
app.get('/file', function getState(req,res,next){
// res.type('json')
res.sendfile(`${__dirname}/public/data.txt`)
})
如上代码,启动 server.js ,Chrome 浏览器访问 /file 时服务返回 data.txt 内容,尽管响应头是 Content-Type: text/plain; charset=UTF-8,响应内容依旧能被识别为 json。由此, text/plain 会作为 json 的标记也是一种常见现象。如果跨域访问 /file 就会出现 CORB,验证结果如下图,

如果使用 script 跨域请求本就是 js 资源,但该资源却被打上了错误的 Content-Type,还添加了 nosiniff,会发生什么?
很多时候 script 文件被会打上 html xml json 这些 MIME 类型,如果 Chrome 浏览器直接 block,将相应内容置空,当前域下的网站便会 因为缺少 js 执行内容而不能正常运行。为避免这种情况出现,Chrome 浏览器在决定是否保护响应内容前,会先判断 script 的响应内容是否是受保护的 MIME 类型(html xml json )。如果检测结果是,则启动 CORB,如果无法检测会直接返回,不启用 CORB。
对于跨域请求 js 资源,如果已经存在 nosniff 的情况下,还把 js 资源设置成了其它类型(如:json),那么必定触发 CORB 保护机制,无法返回 js 资源内容,如果此时本域站点刚好需要这个 js 资源,就 GG 了。相当于 错误的 MIME type 加上 X-Content-Type-Options: nosniff 会触发 CORB ,即使资源真正的类型同跨域标签一致。
为了最佳安全策略,建议开发者
- 为响应内容标记正确的
Content-Type; - 使用
X-Content-Type-Options: nosniff禁止MIME sniffing,如此,可以让浏览器不进行内容 MIME 类型嗅探,从而更简单快速地保护资源或响应返回。
控制台出现 CORB 提示时,不用担心,一般不会对页面产生本质性的影响,可以直接忽略。
Chrome 发生 CORB 保护时的提示和行为验证
虽然该部分内容属于验证类,但想了解一项知识点,仅仅简单地阅读是不够的,实际操作试验后才能获得更深的印象和理解。
环境准备
Chrome 版本: Chrome 73。
Node 服务代码 index.js,
const express = require('express')
const path = require('path')
const app = express()
const port = process.argv[2] || 3002
app.get('/', function (req, res) {
res.send('<p>hello world!</p>')
})
app.get('/data', function (req, res) {
console.log('请求正常,只是浏览器将响应数据置空')
res.json({greeting: 'hello chrome!'})
})
app.listen(port, () => console.log(`app is listening at localhost:${port}`))
配置 host
127.0.0.1 a.dd.com
127.0.0.1 c.dd.com
127.0.0.1 test.pp.com
实验一:在test.pp.com中使用 img 标签跨域请求 c.dd.com 的数据,数据 MIME 类型为 json
- 执行
npm init和npm install安装服务依赖包 - 执行
node index.js启动服务 - 浏览器中访问
test.pp.com:3002并打开 开发者工具 - 开发者工具
Elements中插入<img src="http://c.dd.com:3002/data"/>(选中 body 元素,再按 F2 即可进入 html 编辑模式)
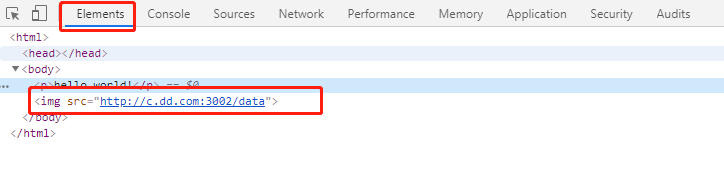
- 查看控制台
console即可见,CORB 提示。
- 删掉
app.get('/data')方法返回的数据{greeting: 'hello chrome!'},即 将服务本身返回的数据本身置空,CORB 提示消失,但依旧看不到请求头 和 响应结果。
实验结果:1. 使用 `img` 跨域请求 json 类型的数据确实会出现 CORB;2. 当服务本身返回数据为空时,CORB 提示会消失,但其行为依然保持。
实验二:在test.pp.com 中使用 script 跨域请求 c.dd.com 的数据,数据 MIME 类型为 json
- 补回实验一删掉的代码
{greeting: 'hello chrome!'},浏览器中访问 test.pp.com 并 打开开发者工具。 - 在开发者工具
console栏中执行下方代码,即可插入 js 标签并发送跨域请求。
s = document.createElement('script')
s.src = 'http://c.dd.com:3002/data'
document.head.appendChild(s)
效果如图,

同 img 表现一致,出现了 CORB 提示。清除{greeting: 'hello chrome!'},将服务返回数据置空,效果同 img 方式表现一致,CROB 提示消失。其它行为也同 img 。
实验结果:同 `img` 行为效果一模一样。
看了浏览器中 请求的响应 情况,现在看看,两次实验的 请求执行 情况,
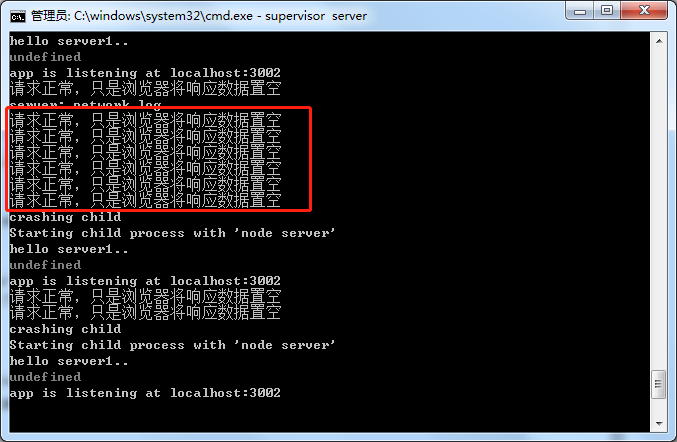
可以看到尽管产生了 CORB 保护,让响应结果变为空,也隐藏了请求头,但服务请求本身始终正常接收请求并进行处理。由此,看到 CORB 后,一般可以直接忽略该提示。
如果跨域请求 http://a.dd.com:3002/data 本身发生错误,则完全无需 CORB 的保护,本身就已经不能正常返回了。因此,更不需要 CORB 的提示和行为。
实验三:在 test.pp.com 中跨域请求 c.dd.com 服务的 server.js 文件
本实验旨在验证 在某站点跨域请求 js 文件,而该 js 文件被设置了不同的 MIME 类型 和 nosniff 时,Chrome 是否会出现 CORB 。
第一步,server.js 文件 MIME 类型为默认,不设置 nosniff。c.dd.com服务代码 index.js 中添加如下代码,
代码片段一,
app.get('/file', function getState(req,res,next){
res.sendfile(`${__dirname}/public/js/server.js`)
})
打开 Chrome test.pp.com 的开发者工具,并在开发者工具中执行如下代码,跨域请求 server.js
代码片段二,
s = document.createElement('script')
s.src = 'http://c.dd.com:3002/file'
document.head.appendChild(s)
运行结果如下图,
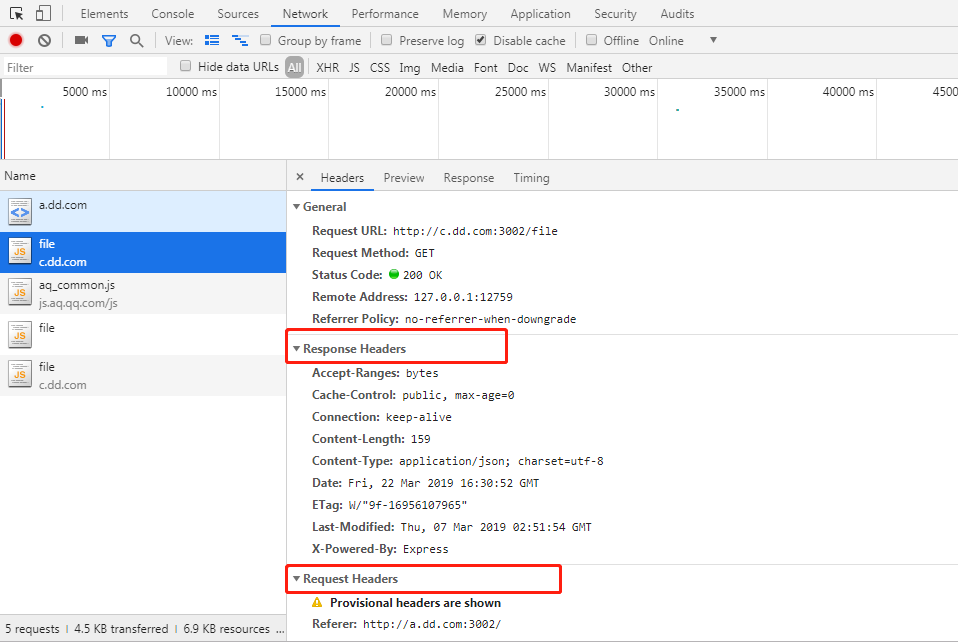
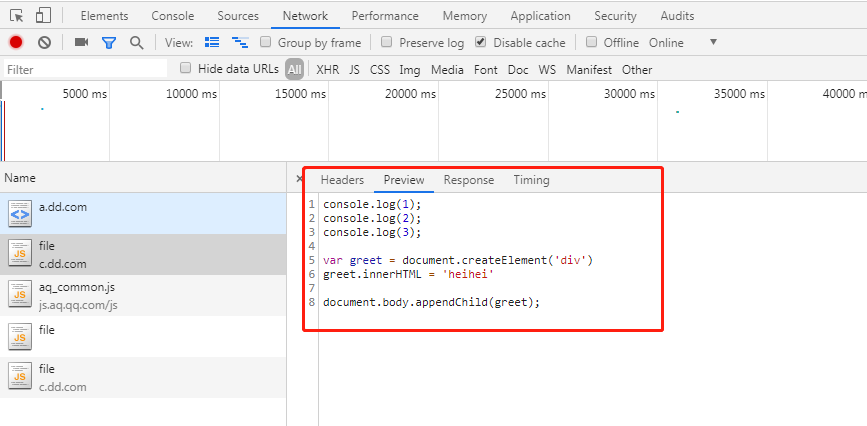
如图所示:真实请求头被隐藏,Provisional headers are shown;响应头可见;响应结果可见。
第二步,设置 MIME 类型为 json,即 Content-Type: application/json; charset=utf-8,不设置 nosniff。修改 index.js /file 部分代码如下,
代码片段三,
app.get('/file', function getState(req,res,next){
res.type('json')
res.sendfile(`${__dirname}/public/js/server.js`)
})
再次执行本实验 代码片段二,发现运行结果同第一步(即默认 MIME 类型)完全一样:真实请求头被隐藏,Provisional headers are shown;响应头可见;响应结果可见。
第三步,设置 MIME 类型为 json,即 Content-Type: application/json; charset=utf-8,并添加
'X-Content-Type-Options': 'nosniff' 响应头。(如果不理解该响应头的含义,请再次阅读文顶内容嗅探相关描述)
两个响应头加在一起的意思是,明明自己是 js ,却告诉浏览器 MIME 类型是 json,还非不让浏览器使用嗅探技术修正 MIME 类型。
修改 index.js /file部分代码如下。
代码片段四,
app.get('/file', function getState(req,res,next){
res.type('json')
res.set({
'X-Content-Type-Options': 'nosniff'
})
res.sendfile(`${__dirname}/public/js/server.js`)
})
再次执行本实验 代码片段二,运行结果如下图,

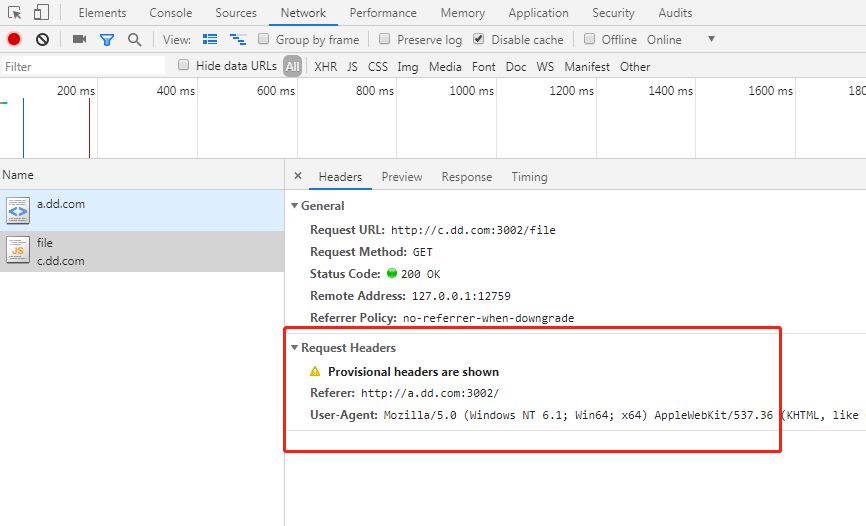
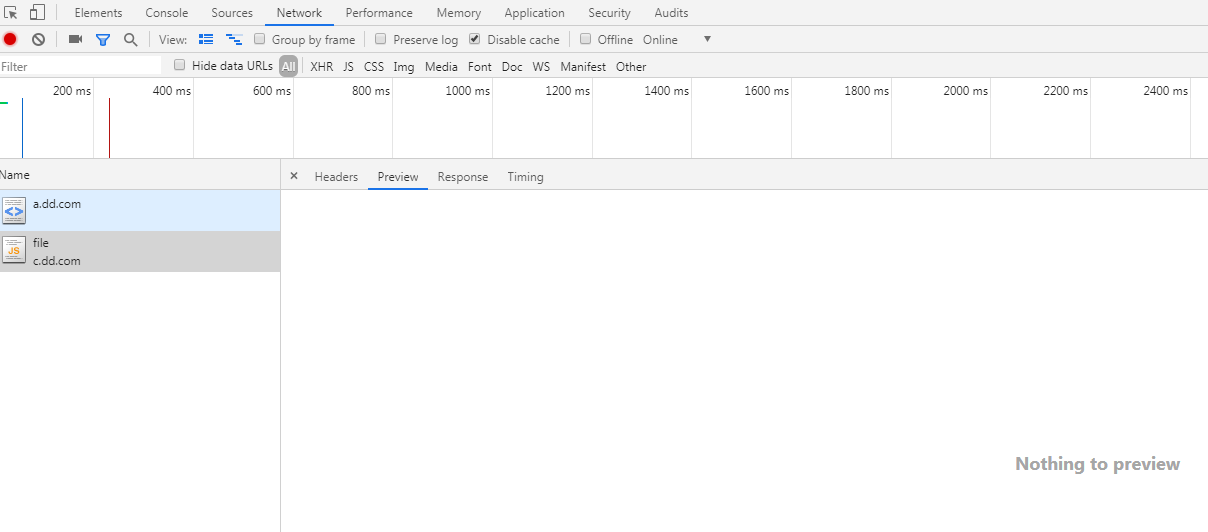
如图所示: 跨域请求 js 文件时,如果没有设置 nosniff,甭管 MIME 类型设置了什么,都只是请求头不显示,响应头和响应结果正常显示。如果设置了 nosniff 且 MIME 类型不是 js,则会触发 CORB 保护,跨域 js 无法正常加载。
因此,如果作为跨域站点 c.dd.com 和 本域站点 test.pp.com 合作时,如果为了 减少 MIME 类型嗅探时间 加上了 nosniff 请求头,同时,需务必保证设置的 MIME 类型同 js 文件一致!否则 本域站点 无法拿到 跨域站点 的 js 资源数据!
----------------- 关于 CORB , Chrome 表现和行为验证结束 -------------------
原文地址:www.yaoyanhuo.com/blog/corb
参考内容
- CORB 行为官方说明:www.chromium.org/Home/chromi…
- CORB Explainer:chromium.googlesource.com/chromium/sr…
- speculative side-channel attack techniques: security.googleblog.com/2018/01/tod…
- Chrome浏览器安全新功能 网站隔离:www.trustauth.cn/wiki/26052.…
- 30 分钟理解 CORB 是什么:www.cnblogs.com/oneasdf/p/9…
- X-Content-Type-Options:developer.mozilla.org/zh-CN/docs/…
- 浏览器 MIME 类型嗅探:www.keycdn.com/support/wha…
- 延伸阅读,曾经 IE 的一个内容嗅探技术漏洞:www.safebase.cn/article-131…
- 浏览器工作原理:www.infoq.cn/article/CS9…
- 给程序员解释 Spectre 和 Meltdown 漏洞:zhuanlan.zhihu.com/p/32784852
- 旁道攻击:zh.wikipedia.org/wiki/旁路攻击
- V8 引擎:zhuanlan.zhihu.com/p/27628685
- 一些还在讨论中的 CORB 行为:github.com/whatwg/fetc…
- fetch API:developers.google.com/web/updates…
作者博客主页:www.yaoyanhuo.com
