

前言
上一篇文章简单的介绍了一下通过docker搭建rabbitmq集群的过程。本文主要介绍一 下rabbitmq 集群针对网络分区的应对策略,主要针对以下几个问题展开:
- 什么是网络分区?
- 为什么会出现网络分区?如何模拟?
- 网络分区对rabbitmq的消费者,生产者有什么影响?
- rabbitmq 如何应对网络分区?
一.什么是网络分区?
在分布式系统中,不同的节点分布在不同的子网络中,由于一些特殊的原因,这些子节点之间出现了网络不通的状态,但他们的内部子网络是正常的。从而导致了整个系统的环境被切分成了若干个孤立的区域,这就是网络分区。针对rabbitmq 而言,出现网络分区时,处于子网中的节点会认为不处于自身分区的节点都down了,针对交换器,队列,绑定关系等操作都只对当前分区有效。
二.为什么会出现网络分区?
出现网络分区的原因有很多,比如网卡故障,网络闪断等等导致子网间网络不通。rabbitmq 内部节点默认会通过25672端口进行彼此间信息交换,如果每隔1/4的net_ticktime 时间进行一次应答时,连续4次出现应答不上,则会认为彼此间网络不通,就会出现部分节点被剥离出当前分区,进而形成网络分区;
默认配置文件第361行: %% {net_ticktime, 60}
docker 模拟网络分区
首先假设以及搭建起了由myrabbit1,myrabbit2,myrabbit3 3个节点构成的集群,如下所示:集群中包含3个disc 类型的节点
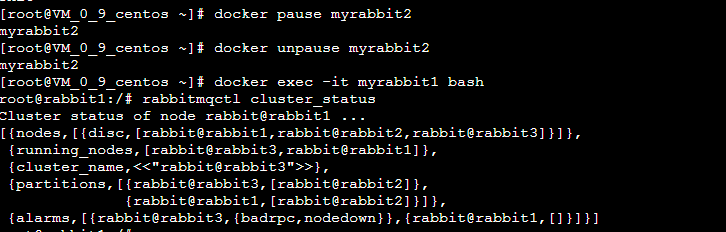
root@rabbit3:/# rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit3 ...
[{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
{running_nodes,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]},
{cluster_name,<<"rabbit@rabbit3">>},
{partitions,[]},
{alarms,[{rabbit@rabbit1,[]},{rabbit@rabbit2,[]},{rabbit@rabbit3,[]}]}]
通过docker pause 命令暂停其中的一个docker进程,过一段时间之后再unpause 该容器,模拟net_ticktime 超时.
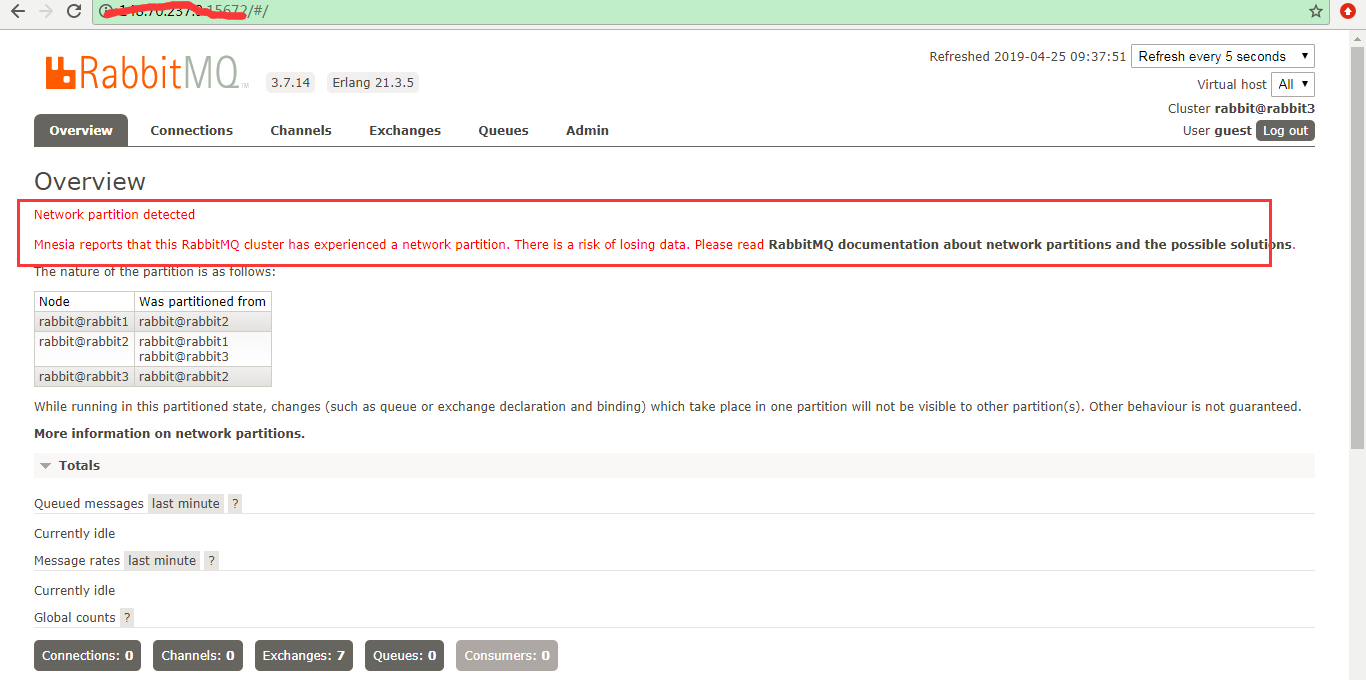
三.网络分区出现对消息的生产者和消费者会产生什么影响呢?
分2种情况讨论:
- 不存在镜像队列
- 存在镜像队列
不存在镜像队列的情况:
场景1:
生产者客户端 节点名称 交换器 绑定key 队列 client1 nodel ex key1 queue1 client2 node2 ex key2 queue2
说明一下:
> 这种场景表示生产者客户端1 连接到节点1上,通过路由key1 发送消息的exchange中,最终消息被路由到queue1(queue1也是定义在node1上);
> 生产者客户端2 连接到节点2上,通过路由key2 发送消息的exchange中,最终消息被路由到queue2(queue2也是定义在node2上)
在这种情况下,不管是否出现网络分区,对生产者,消费者而言都不会有影响;
场景2:
说明:还是上面的配置,生产者客户端1 还是连到节点1上,queue1也还是在节点1上, 但是客户端发送消息的时候,采用的路由键是key2, 也就是说消息会被路由到node2上的队列queue2里。同理,生产者客户端2 还是连在节点2上,queue2也还是在节点2上,但是消息发送的时候是通过key1路由到nodel1 上的queue1里。
这种场景下出现网络分区就有问题了:
出现网络分区之后,node1和node2 连不通了,这时候对于生产者客户端而言:发送出去的消息找不到对应的绑定队列了,消息会被退回或者丢弃; 对于消费者而言,消息消费之后,向对应的broker 发送确认ack消息的时候,也会发现找不到相应的节点了,这个时候消息消费端的确认机制也会有问题,可能会收到重复消息。
个人理解:出现这种问题的根本原因还是在于:rabbitmq的集群的节点间只是会同步元数据信息,消息只是放在对应的宿主队列里。
存在镜像队列的情况:
有镜像队列的情况,复杂的多,因为出现网络分区之后,对于镜像队列涉及到主从晋升,这块的场景后面再进一步详细分析。
四. rabbitmq 如何应对网络分区:
rabbitmq 针对网络分区提供了几种配置:
[
{rabbit,
[
{tcp_listeners,[5672]},
{cluster_partition_handling, ignore}
]
}
].
配置项分为以下几种:
-
ignore 默认类型,不处理。要求你所在的网络环境非常可靠。当出现网络分区的时候需要人工介入。
-
pause_minority:
rabbitmq节点感知集群中其他节点down掉时,会判断自己在集群中处于多数派还是少数派,也就是判断与自己形成集群的节点个数在整个集群中的比例是否超过一半。如果是多数派,则正常工作,如果是少数派,则会停止rabbit应用并不断检测直到自己成为多数派的一员后再次启动rabbit应用。注意:这种处理方式集群通常由奇数个节点组成。 -
autoheal 你的网络环境可能是不可靠的。你会更加关心服务的可持续性,而非数据完整性。 一般针对包含2个节点的集群,当网络分区恢复后,rabbitmq各分区彼此进行协商,分区中客户端连接数最多的为胜者,其余的全部会进行重启,恢复到同步状态。
总结
本文只是简单介绍了一下rabbitmq的网络分区,以及相应的配置策略。由于更多的偏运维层面,实践经验较少,可能谈的不够深入,后续在实践中经过沉淀后再进一步补充。
参考书籍《rabbitmq 实战》
