

数组与链表
数组与链表对于每一门编程语言来说都是重要的数据结构之一。数组是一段内存连续的,有序的元素序列,大小固定,初始化时需要指定可承载的元素个数; 链表是非连续、非顺序的存储结构, 数据元素的顺序是通过指针链接实现的。
开发中选择数组还是链表,这就要结合场景和它们各自优缺点.
数组的优缺点
数组的内存是连续, 连续有什么意义,它内存地址是连续的, 比如创建一个new Object[5], 假如第一个内存地址是init_address, 第二个地址就是init_address + 1。所有数组随机访问很快,访问第某个元素,用初始的地址加上下标就能找到啦, 数组遍历也很快。 数组的大小固定, 数组在元素删除和添加就带来一点麻烦,在实际开发中通常使用数组容器,比如java的ArrayList,ArrayList有个默认数组容量, 为10。 ArrayList.add方法中当添加第11个元素时,需要扩容创建一个新的数组,还需要把原数组的元素复制到新的数组。假如 ArrayList当前有8个元素,当移除第5个元素时,并不是简单把第5个元素设置为null, 还要把第6 - 8 个元素都往前挪移1位。当ArrayList的元素是int等基本类型,会涉及到装箱和拆箱,相对与直接使用Int数组性能会稍微差一点,但是有时方便,牺牲一点性能也可以。
链表的优缺点
链表的元素通过指针链接, 故大小是无限,只要不爆内存,不需要像数组那样扩容。链表的添加和删除就相对简单点,下面以单链表为例,添加一个元素,把上一个元素的next指针指向一个新的元素即可; 假如该链表有3个元素,当删除第2个元素时,把第一个元素的next指针指向第3个元素。链表元素遍历相对数组慢一点,而且随机访问第某个元素也相对麻烦,需要遍历。
链表根据结构通常可以分为:单链表、双向链表、循环链表。
单链表:
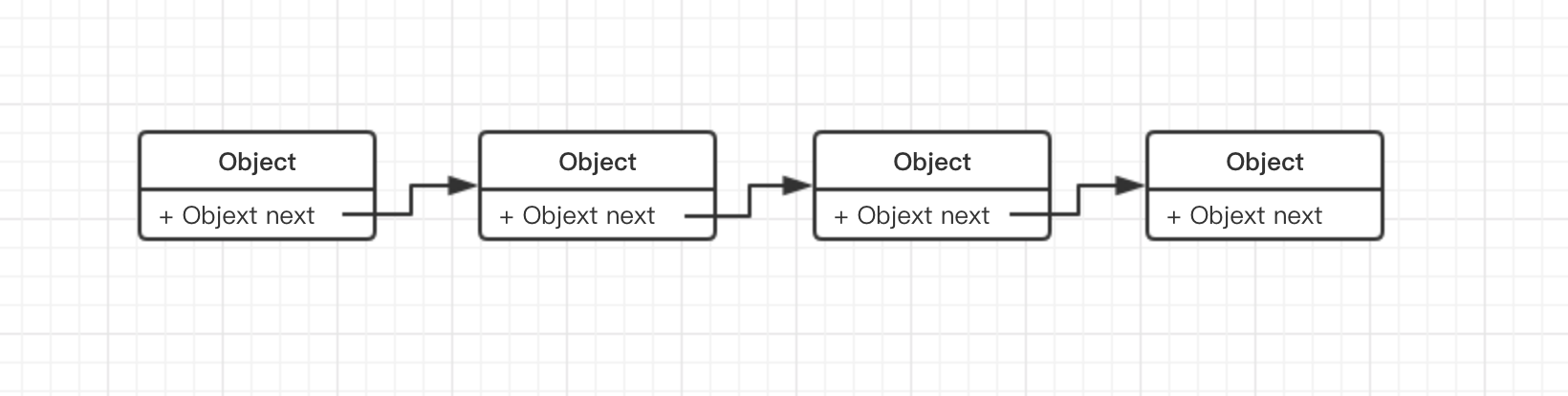
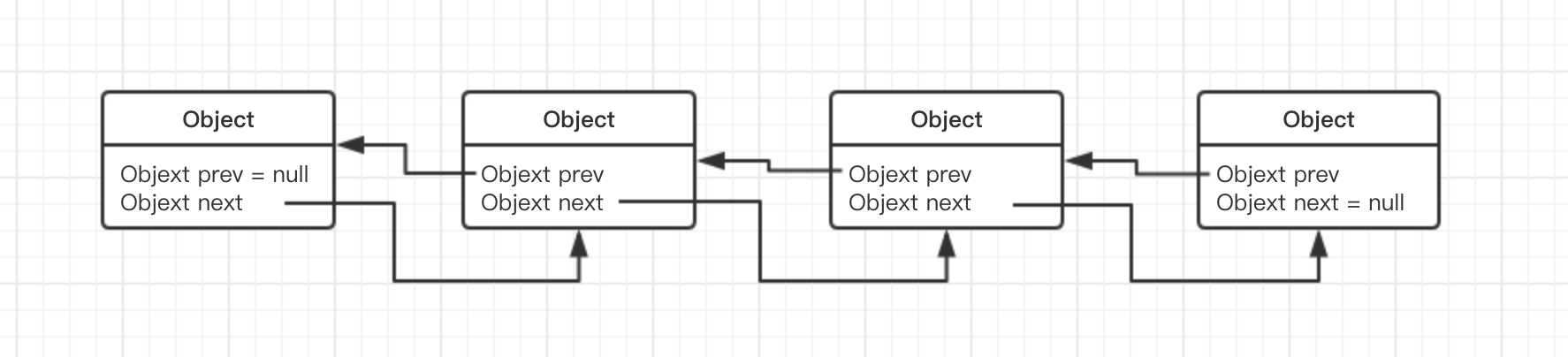
双向链表:
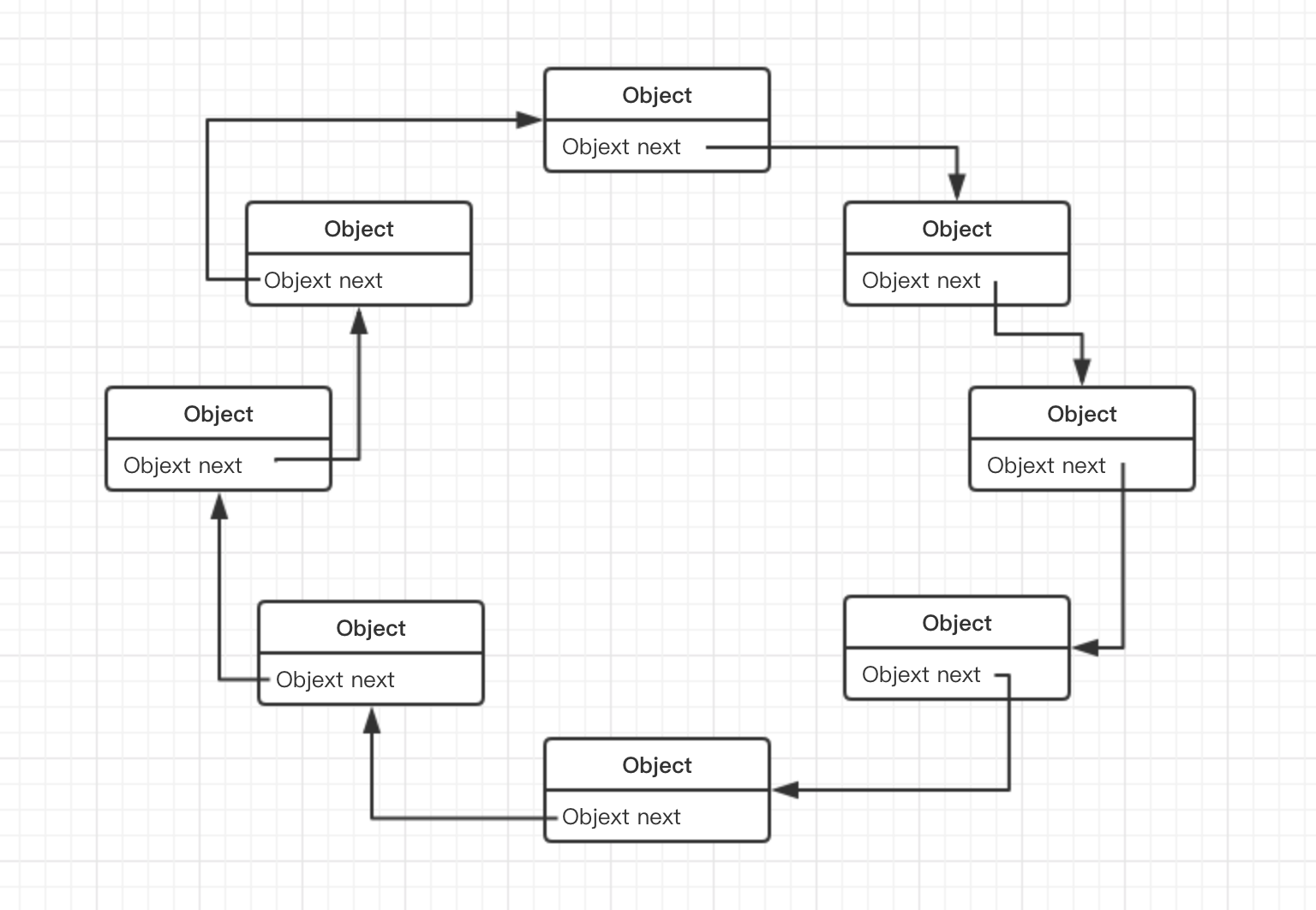
循环链表:
单链表中有环:
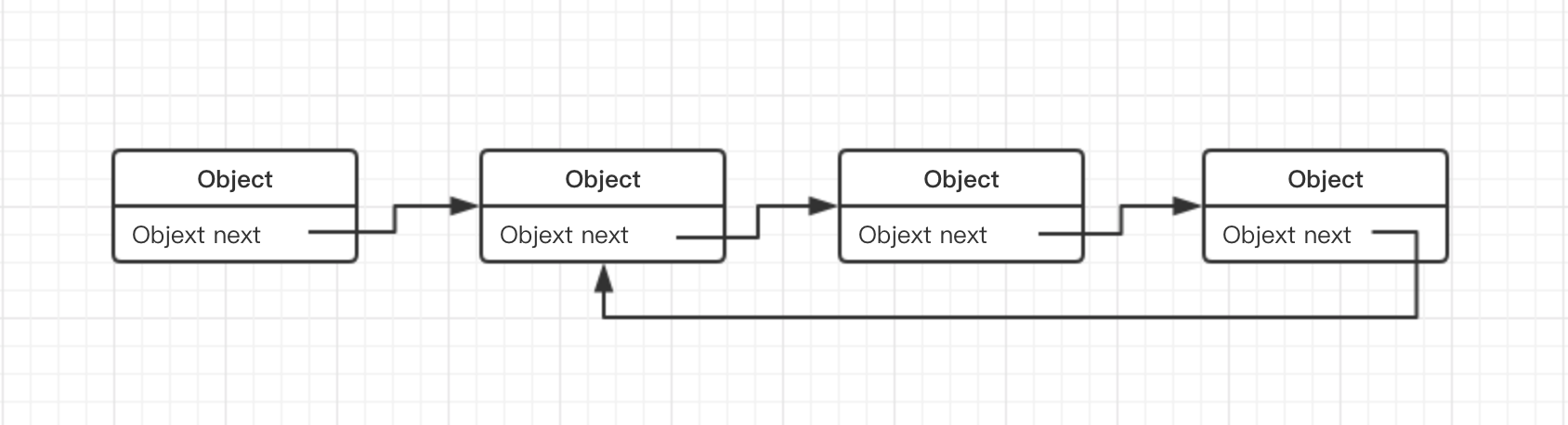
上面图中有个单链表中有环,需要注意一下,在使用单链表时,在遍历过程, 以最后元素的next指针为null作为结束的标志,但是如果出现如图的情况,就会出现死循环。对于链表的代码实现,不多说,可以看java中LinkedList类, LinkedList实现了双向链表。
栈与队列
栈是一种操作受限的线性表, 仅允许在一端进行插入和删除运算, 后进者先出,先进者后出。举个形象点的例子,有个硬币大的杯子,往杯子里一个个地放硬币, 所有取硬币只能从顶部一个个取出。(不能倒,杯子用502黏住啦) 这里的硬币就是程序里的元素,而这个杯子就是"栈"。
怎么实现一个栈?
上面提到数组和链表都可以实现。以数组实现为例,简单描述一下,压栈(意思是放一个元素)过程只要按顺序依次放到数组的index里,从index=0开始; 数组可以访问任意index的元素,而出栈(意思是取一个元素)只能从顶部出, 所以需要限制数组里元素的访问,取出时只能从装有元素中最大index中取出即可。当然压栈时数组也可能需要扩容,一些细节就不多说啦, java中Stack类就是一个实现栈的例子。
队列也是一种操作受限的线性表, 只允许在表的一端进行删除操作,而在另一端进行插入操作,先进者先出。来个形象的例子,有个一根玻璃球大的水管, 倾斜着放(假设左边高右边低),在左边不停地放入球,球就会从右边出, 而这水管就可以简单理解为"队列"。队列也可以使用数组或者链表实现。
栈与队列应用场景
栈的应用场景很广泛,下面举一些例子:
-
浏览器的前进和后退可以用栈来实现, 一个标签页是一个栈,在打开一个网压栈,在网页中点一个链接,也就是前进,再压栈,后退对应就是出栈。 浏览器有新建一个标签或者在新的标签里打开页面,就是创建一个新的栈,并把打开链接压栈。
-
安卓应用的界面前进后退也是,有Activity栈,Fragment栈。
-
函数调用也可以用栈实现,在进入被调用函数的时候,分配一段栈空间给这个函数的变量,在函数运行结束的时候,将栈顶复位,正好回到调用函数的作用域内。
-
表达式求值中应用,比如 4 + (6 - 12 + 2* 2) * 2计算。
表达式运算过如下图所示:
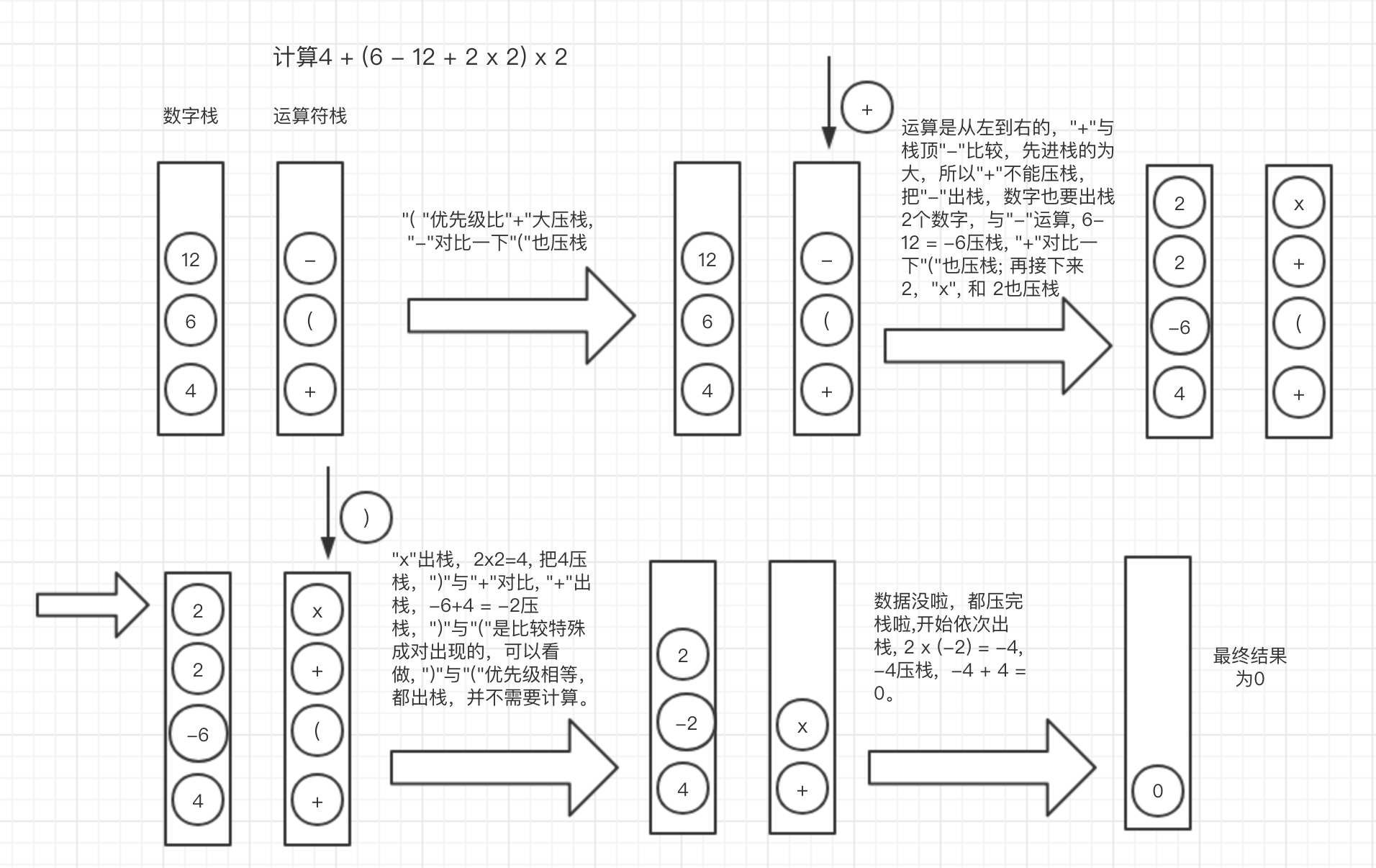
队列通常存在不同的类型,比如循环队列,并发队列,阻塞队列等, 不同的队列使用场景有所不同。
- 阻塞队列, 当队列为空的时候,从队头取数据会被阻塞, 直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作也会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。 阻塞队列通常用在生产者消费者模型中,生产数据和消费数据的速率不一致,如果生产数据速度快一些,消费者处理不过来,就可能会导致数据丢失。这时候我们就可以用阻塞队列来解决。
- 队列应用在线程池请求排队的场景, 当线程池没有空闲线程时,新的任务请求线程资源,线程池通常会使用队列来存储排队的请求,为什么用队列, 因为队列先进先出,可以比较公平处理排队的请求。如果是使用链表的实现方式,可以实现无限排队的无界队列, 但是可能会导致过多请求排队,造成处理响应时间慢。如果使用数组的实现方式,是有界队列, 当排队请求满了,接下来的请求会被拒绝。所有这两种策略可以看场景使用。
