

如果将应用的所有数据简单地放在一台 MySQL 服务器实例上,就不用谈什么扩展性了。但是业务能稳定持续的增长,那么应用肯定会碰到性能瓶颈。
对于很多类型的应用而言,购买更高性能的机器能解决一大部分性能问题,这也是我们常说的 “垂直扩展” 或者 “向上扩展”。
另一个与之相反的方法是将任务分配的多台机器上,这通常被称为 “水平扩展” 或者 “向外扩展”。
接下来,我们将讨论如何联合使用向上扩展和向外扩展,以及如何使用集群方案来进行扩展。
最后,大部分应用还会有一些很少或者从不需要的数据,这些数据可以被清理或归档,我们可以称这种方案为 “向内扩展”。
1 向上扩展
向上扩展(也叫垂直扩展)意味着购买更多性能强悍的机器。这种策略有较多优点:
- 更容易维护和开发,显著节约开销;
- 单台服务器备份和恢复较为简单,无需关心一致性;
因此,从复杂性的成本来说,大多时候,向上扩展比向外扩展更简单。
另外,不要觉得向上扩展很快就走到“尽头”,要相信科技的进步速度。现在,拥有 0.5TB 内存、32 核(或者更多)CPU 以及更强悍 I/O 性能的商用服务器很容易获得。优秀的应用和数据库设计,再加上很好的性能优化技能,已经可以满足绝大多数商业应用。
不过遗憾的,虽然高性能服务器比较容易获得,但是 MySQL 并不能扩展到对应的规模。为了更好地在大型服务器上运行 MySQL,一定要尽量选择最新的版本。即使如此,当前合理的 “收益递减点” 的机器配置大约是:
- 256G RAM
- 32 核 CPU
- PCIe flash 驱动器
如果继续提升硬件配置,MySQL 性能虽然还能有所提升,但性价比就会降低。
因此,我们建议,如果系统确实有可能碰到可规划性的天花板,并且会导致严重的业务问题,那就不要无限制的做向上扩展的规划。对于庞大的应用,可以短期内购买更优的服务器,但最终还是需要向外扩展的。
2 向外扩展
向外扩展(也叫横向扩展或水平扩展)策略通常分为三个部分:复制、拆分和数据分片。
最常见的向外扩展就是读写分离。通过复制将数据分发到多个服务器上,然后将备库用于读查询。这种技术对于以读为主的应用很有效。
另一个比较常见的向外扩展方法是将工作负载分布到多个 “节点”。接下来我们要了解的主要是这种扩展方法。
在此之前,我们先明确下节点的概念。在 MySQL 架构中,一个节点就是一个功能部件。一般的,我们会将一台服务器作为一个几点。但如果我们考虑到节点的高可用性,那么一个节点通常可能是下面的几种:
- 一个主 - 主 复制双机结构,拥有一个主动服务器和被动服务器。
- 一个主库和多个备库。
- 一个主动服务器,并使用分布式复制块设备(DRBD)作为备用服务器。
- 一个基于存储区域网络(SAN)的 “集群”。
2.1 按功能拆分
按功能拆分,或者说按职责拆分,意味着不同的节点执行不同的任务。
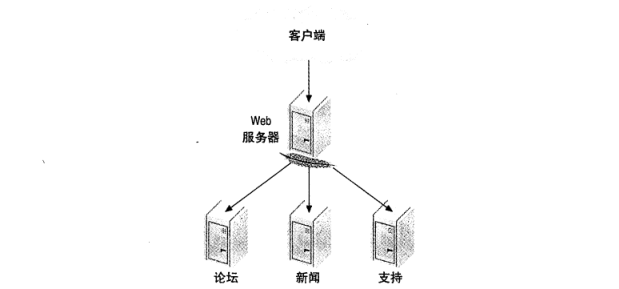
例如,如果有一个网站,各个部分无需共享数据,那么可以按照网站的功能区域进行划分。像我们常见的门户网站,一般都是把不同栏目放在一起,但实际上可以将网站新闻、论坛、寻求支持等功能放到专用的 MySQL 服务器。如图 2-1
2.2 数据分片
在目前用于扩展大型 MySQL 应用的方案中,数据分片是最通用且最成功的方法。它把数据分割成一小片,或者说一块,然后存储到不同的节点中。
在使用分片前,要牢记一个通用原则:如非必要,尽量不分片。
除此之前,对于分片,我们只会对需要的数据做分片。这里 “需要的数据” 通常是那些增长非常庞大的数据。而像对于用户信息这些全局数据,一般是存储在单个节点上,通常保存在类似 redis 这样的缓存中。
对于分片,我们通常要考虑下列问题:
- 选择合适的分区键(partition key)。
- 是否需要多个分区键?
- 跨分片查询如何处理?
- 如何分片数据、分片和节点?
- 如何在节点上部署分片?
- 如何生成全局唯一 ID?
2.3 通过多实例扩展
上面提到过,MySQL 不能完全发挥现代硬件的性能。当扩展到超过 24 个 CPU 核心时,MySQL 的性能开始趋于平缓,不再上升。当内存超过 128G 时也同样如此。对于此种情况,我们可以通过多实例策略充分发挥硬件的性能。
多实例策略的基本思路是:
- 数据分片足够小,可以使得在每台机器上都能放置多个分片;
- 每台服务器运行多个实例;
- 给每个实例划分服务器的硬件资源;
可以看出,这是一种向上扩展和向外扩展的组合方案。这种方案还可以通过将每个 MySQL 实例绑定到特定的 CPU 核心上来优化性能。这种优化,主要有两个好处:
- 由于 MySQL 内部的可扩展性限制,当核心数较少时,能够在每个核心上获得更好的性能;
- 当实例在多个核心上运行线程时,由于需要在多核心上同步共享数据,因而会有额外的开销。
而我们把实例和 CPU 核心绑定后,可以减少 CPU 核心直接的切换和交互。要注意的,将进程绑定到具有相同物理套接字的核心上可以获得最优的效果。
3 向内扩展
对于不断增长的数据和负载,最简单的方法是对不再需要的数据进行归档和清理。这种操作可能会带来显著的效果。这种做法并不能代替其他策略,但可以作为争取时间的短期策略,也可以作为处理大数据量的长期计划之一。
在设计归档和清理策略时需要考虑如下几点:
- 对应用的影响。设计良好的归档系统能够在不影响事务处理的情况下,从一个高负债的 OLTP 服务器上移除数据。
- 要归档的行。考虑清楚哪些数据可以清理或归档。
- 维护数据一致性。数据间存在联系时,归档任务系统要能够保证数据的逻辑一致性。
- 避免数据丢失。归档时要保证归档数据已经成功保存,再讲源数据删除。
- 解除归档。考虑清楚归档系统中的解除归档策略。可以通过设置一些检查点让系统检查是否有需要归档的数据。
如果不能及时的把老数据归档和清理时,我们也可以通过以下隔离冷热数据的方式来提高性能:
- 将表划分为几个部分。分割大表中的冷热数据,保证加载到内存中的数据中,热数据的比例;
- MySQL 分区。使用MySQL 自带的分区的功能,可以帮助我们把最近的数据留在内存中;
- 基于时间的数据分区。如果应用不断有新数据尽量,一般新数据总是比旧数据更加活跃。因此,我们可以将新数据完整的保留在内存中,同时使用复制来保证主库失效时有一份可以的备份,而旧数据就而言放到别的地方。
总结
- 向上氪金,向外氪脑。三思而后行。
- 能不分片,就尽量不分片。
