

前言
项目地址:Crawler-for-Github-Trending
项目中基本每一个操作都写有注释,适合对 Node 爬虫感兴趣的同学对其有基础的了解。
介绍
50 lines, minimalist node crawler for Github Trending.
一个50行的 node 爬虫,一个简单的 axios, express, cheerio 体验项目。
体验
首先保证电脑已存在 node10.0+ 环境,然后
1.拉取本项目
git clone https://github.com/poozhu/Crawler-for-Github-Trending.git
cd Crawler-for-Github-Trending
npm i
node index.js
2.或者下载本项目压缩包,解压
cd Crawler-for-Github-Trending-master // 进入项目文件夹
npm i
node index.js
示例
当启动项目后,可以看到控制台输出
Listening on port 3000!
此时打开浏览器,进入本地服务 http://localhost:3000/
http://localhost:3000/time-language // time 表示周期,language 代表语言 例如:
http://localhost:3000/ // 默认抓取今日全部语言的情况
http://localhost:3000/daily // 代表今日 可选参数:weekly,monthly
http://localhost:3000/daily-JavaScript // 代表今日的 JavaScript 分类 可选参数:任意语言
稍微等待即可看到爬取完毕的返回数据示例:
[
{
"title": "lib-pku / libpku",
"links": "https://github.com/lib-pku/libpku",
"description": "贵校课程资料民间整理",
"language": "JavaScript",
"stars": "14,297",
"forks": "4,360",
"info": "3,121 stars this week"
},
{
"title": "SqueezerIO / squeezer",
"links": "https://github.com/SqueezerIO/squeezer",
"description": "Squeezer Framework - Build serverless dApps",
"language": "JavaScript",
"stars": "3,212",
"forks": "80",
"info": "2,807 stars this week"
},
...
]
解析
首先引入爬虫所需要的依赖包
const cheerio = require('cheerio') //页面抓取模块,可以像 JQ 一样获取页面的内容
const axios = require('axios'); //请求处理
const express = require('express') //服务器模块
拼接请求地址
function getData(time, language) {
//确定好爬取函数所需要的参数后,通过参数的判断来做好请求地址的拼接
let url = 'https://github.com/trending' + (!!language ? '/' + language : '') + '?since=' + time;
}
发起一个简单的get请求
function getData(time, language) {
let url = 'https://github.com/trending' + (!!language ? '/' + language : '') + '?since=' + time;
axios.get(url)
.then(function (response) {
let html_string = response.data.toString();
const $ = cheerio.load(html_string); // 传递页面到模块
//此时我们已经可以像用 JQ 一样对获取到的页面 $ 进行元素获取了
});
})
.catch(function (error) {
console.log(error);
})
}
分析Github Trending页面结构,编写数据提取部分
可以发现列表存在于 Box 这一个元素之下,所以根据此结构,像 JQ 一样获取对应位置的数据即可:
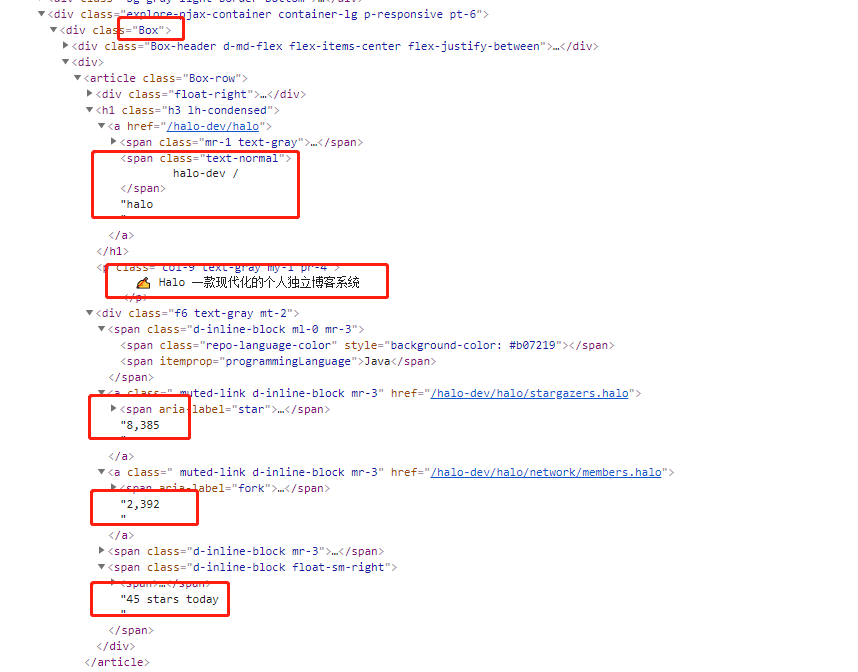
$('.Box .Box-row').each(function () { // 像 jQuery 一样获取对应节点值
let obj = {};
obj.title = $(this).find('h1').text().trimStart().trimEnd(); // 获取标题
obj.links = 'https://github.com/' + obj.title.replace(/\s/g, ""); // 拼接链接
obj.description = $(this).find('p').text().trimStart().trimEnd(); // 获取获取描述
obj.language = $(this).find('>.f6 .repo-language-color').siblings().text().trimStart().trimEnd(); // 获取语言
obj.stars = $(this).find('>.f6 a').eq(0).text().trimStart().trimEnd(); // 获取 start 数
obj.forks = $(this).find('>.f6 a').eq(1).text().trimStart().trimEnd(); // 获取分支数
obj.info = $(this).find('>.f6 .float-sm-right').text().trimStart().trimEnd(); // 获取对应时期 star 信息
obj.avatar = $(this).find('>.f6 img').eq(0).attr('src'); // 获取首位作者头像
}
路由配置
在完成了核心函数后,接下来只要配置一下对应路由即可抓取相应的数据并返回:
const app = express()
//默认抓取页配置
app.get('/', (req, res) => {
let promise = getData('daily'); // 发起抓取
promise.then(response => {
res.json(response); // 数据返回
});
})
//存在两个参数时
app.get('/:time-:language', (req, res) => {
const {
time, // 获取排序时间
language // 获取对应语言
} = req.params;
let promise = getData(time, language); // 发起抓取
promise.then(response => {
res.json(response); // 数据返回
});
})
//存在时间参数时
app.get('/:time', (req, res) => {
const {
time, // 获取排序时间
} = req.params;
let promise = getData(time); // 发起抓取
promise.then(response => {
res.json(response); // 数据返回
});
})
app.listen(3000, () => console.log('Listening on port 3000!')) // 监听3000端口
结语
本项目每次访问都会实时爬取数据,所以数据返回速度会非常慢,期望作为接口数据请定时爬取到数据库。
但了解项目代码可以带来以上各个 node 模块和爬虫最基础的用法和概念,希望可以帮到大家。 😀
