梯度交换是现代多机训练常用的通讯方式(分布式训练,联邦学习)。长期以来,人们认为梯度是可以安全共享的,即训练数据不会因梯度交换而泄漏。但是 MIT 的一项研究表明,隐私的训练数据可以通过共享的梯度来获取。
机器之心发布,作者:Ligeng Zhu等。
该论文已经被 NeurIPS 2019 接受。研究者希望通过这篇工作引起大家的警惕并重新考虑梯度的安全性。他们还在论文中讨论了防止这种深度泄漏的几种可能策略,其中最有效的防御方法是梯度压缩。

网站:https://dlg.mit.edu
论文:https://arxiv.org/abs/1906.08935
此外,他们还将在 NeurIPS 2019 大会上介绍这项工作。
背景
然而,「梯度共享」方案是否真的可以保护参与者的私人数据?在大多数情况下,人们认为梯度是可以安全共享的:因为数值形式的梯度并没有直接包含有意义的训练数据。最近的一些研究指出,梯度揭示了训练数据的某些属性(例如是否戴眼镜)。在这篇文章中,研究者考虑了一个更具挑战性的案例:我们可以从梯度中窃取完整训练数据吗?传统观点认为答案是否定的,但 MIT 的研究表明这实际上是可行的。
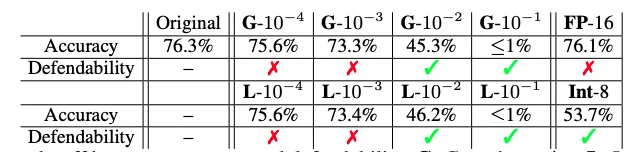
与之前研究中的弱攻击(使用类标签的属性推断和生成模型)相比,这种深度梯度泄漏是第一次被讨论并给现有的多节点机器学习系统带来了挑战。如果是带参数服务器(Parameter server)的训练(下图左侧),中心服务器能够窃取所有参与者的隐私数据。对于无参数服务器的训练(下图右侧),情况甚至更糟,因为任何参与者都可以窃取其相邻节点的训练数据。研究者在视觉(图像分类)和语言任务(隐蔽语言模型)上的验证了攻击的有效性。在各种数据集和任务上,DLG 只需几个梯度步骤即可完全恢复训练数据。
方法
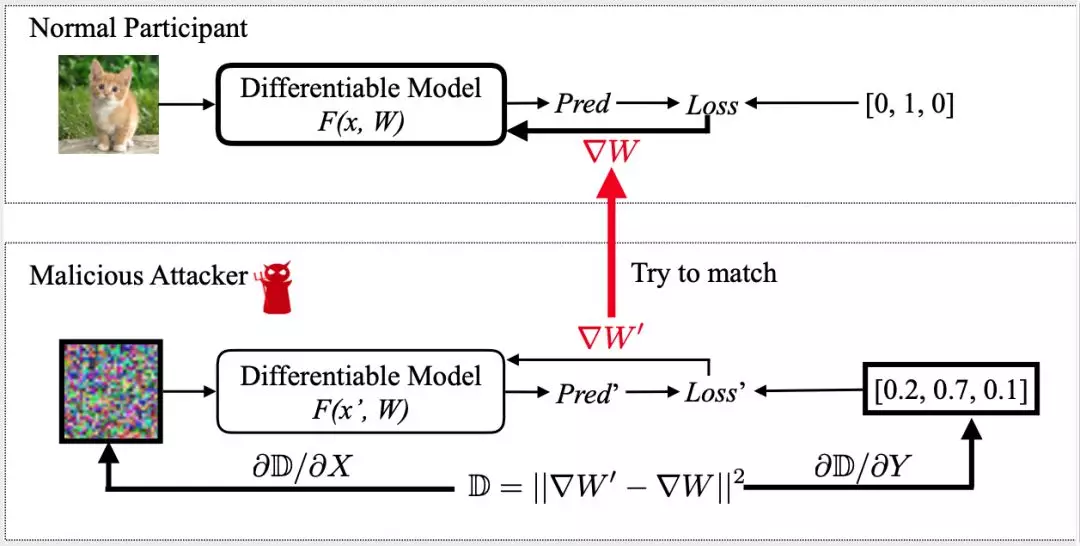
在这项工作中,研究者提出深度梯度泄漏算法(DLG):公开的梯度会泄漏个人的隐私数据。他们提出了一种优化算法,只需几次迭代即可从梯度中获得训练输入和标签。
为了进行攻击,研究者首先随机生成一对「虚拟的」输入和标签(dummy data and label),然后执行通常的前向传播和反向传播。从虚拟数据导出虚拟梯度之后,他们没有像传统优化那样更新模型权重,而是更新虚拟输入和标签,以最大程度地减小虚拟梯度和真实梯度之间的差异。当攻击结束后,私人数据便完全暴露了出来。值得注意的是,整个过程不需要训练数据集的任何额外信息。

研究者在常用的图片分类任务和语言模型上测试了该深度泄漏的效果。在图片分类任务上,他们观察到具有干净背景(MNIST)的单色图像最容易恢复,而像人脸这样的复杂图像则需要更多的迭代来恢复(下图)。优化完成后,尽管有一些可见的噪声点,但恢复结果基本与原始数据相同。

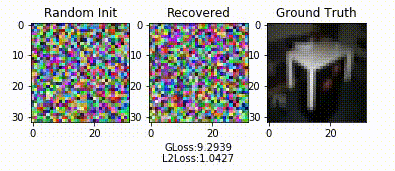
在视觉上,他们比较了其他泄漏算法与 DLG。先前方法 (Melis et al) 基于 GAN 模型。在 SVHN 上,虽然泄漏的结果还可依稀识别出是数字「9」,但这已不是原始训练图像。LFW 的情况更糟,CIFAR 上则完全失败。DLG 展现的泄漏程度远远强于以往的「浅」泄漏算法。
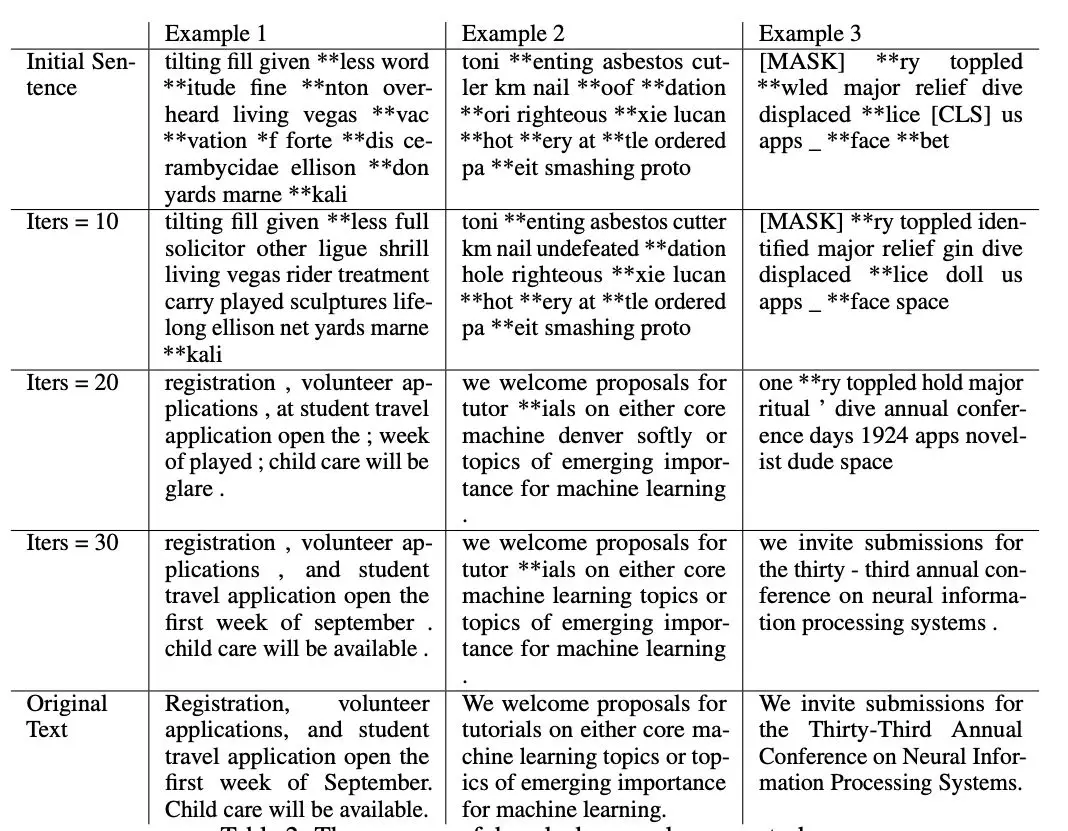
与视觉任务类似,他们从随机初始化的嵌入开始:迭代 0 处的反向查询结果毫无意义。在优化过程中,虚拟词条产生的梯度逐渐向原始词条产生的梯度靠拢。在之后的迭代中,部分原句中的单词逐渐出现。在下表的例 3 中,在第 20 轮迭代中,出现了「annual conference」,在第 30 轮迭代中,得到了与原始文本非常相似的句子。尽管有少部分由于分词本身歧义引起的不匹配,但是原始训练数据的主要内容已经完全泄漏。
深度梯度泄漏(DLG)的攻击程度是之前从未讨论过的。因此,MIT 的研究者也测试了几种防御的方法。
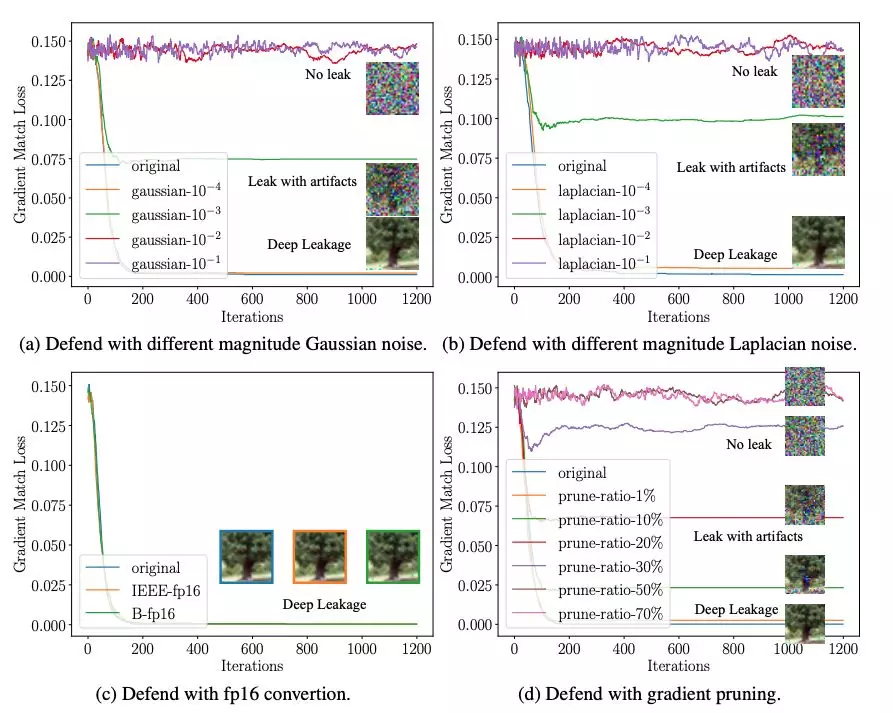
他们们首先实验了梯度扰动(Noisy gradients)并尝试了高斯噪声(Gaussian noise)和拉普拉斯噪声(Laplacian noise)。如下图所示,防御并不是很理想:只有在噪声大到使准确率降低时(> 10^-2),该策略才能够成功防御深度梯度泄漏(DLG)。
他们也测试了低精度梯度对于深度梯度泄漏(DLG)的防御效果。遗憾的是两种常用单精度格式(IEEE Float 16, B Float 16)都不能阻止泄漏。8-bit 数据虽然能阻止该泄漏,然而模型的性能却也明显降低。在多种尝试后,他们发现最有效的防御方法是梯度压缩,只要稀疏性大于 20% 即可成功防御。DGC(Lin 2017)的研究表明可以在梯度的稀疏性达到 99% 以上时,依旧训练出性能相近的模型。因此,压缩梯度是一种对抗深度梯度泄漏(DLG)的有效手段。