

二维数据,Series容器,既有行索引,又有列索引

1. 创建DataFrame
1.1 通过list 创建DataFrame
需要指定 data,index 行,columns 列
指定data和index/columns是list类型或者 np.arange
df1 = pd.DataFrame(data=[[1, 2, 3], [11, 12, 13]], index=['r_1', 'r_2'], columns=['A', 'B', 'C'])
df2 = pd.DataFrame(data=[[1], [11]], index=['r_1', 'r_2'], columns=['A'])
df3 = pd.DataFrame(data=np.arange(12).reshape(3, 4), index=list("abc"), columns=list("ABCD"))
A B C
r_1 1 2 3 r_2 11 12 13
A r_1 1 r_2 11
A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11
1.2 通过字典,创建DataFrame
1.2.1 方式一:传入单个字典, 注意必须是一键多值(单值的时候,也必须加上[])
dict = {"name": ["jack", "HanMeimei"], "age": ["100", "100"]}
# dict = {"name": "jack", "age": "100"}#这样写是会报错的
# dict = {"name":["jack"], "age": ["100"]}#如果是单值,必须加[]
df3 = pd.DataFrame(dict, index=list("ab"))
age age1 name
a 100.0 NaN MaYun1 b 100.0 NaN MaYun2 c NaN 100.0 MaYun3
1.2.2 方式二: 传入字典列表,每一个字典是一行数据,缺少的列会补充nan
dict = [{"name": "MaYun1", "age": 100}, {"name": "MaYun2", "age": 100}, {"name": "MaYun3", "age1": 100}]
# dict = {"name": "jack", "age": "100"}
df4 = pd.DataFrame(dict, index=list("abc"))
2. DataFrame基本属性

dict = {"name": ["jack", "HanMeimei", "Lucy"], "age": ["100", "90","98"], "salary": [30000, 50000, 999000]}
df5 = pd.DataFrame(dict)
print(df5)
print(df5.head(1))
print(df5.tail(1))
print(df5.info())
print(df5.index)
print(df5.columns)
print(df5.values)
print(df5.describe())
3. 所有数据按照指定列排序
df5 = df5.sort_values(by='salary', ascending=True)
print(df5)

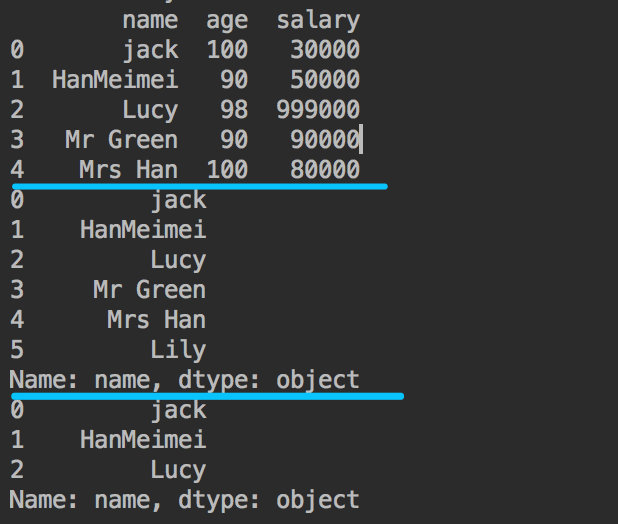
4. DataFrame简单行、列切片
dict = {"name": ["jack", "HanMeimei", "Lucy","Mr Green", "Mrs Han", "Lily"],
"age": [100, 90,98,90,100,30], "salary": [30000, 50000, 999000,90000,80000,75000]}
df6 = pd.DataFrame(dict)
print(df6)
# 取出前五行
print(df6[0:5])
# 取出name列
print(df6["name"])
# 取出前三行的name列
print(df6[0:3]["name"])
5. loc 行、列切片
5.1 啰嗦麻烦版+可以不看,只看5.2
5.1.1 综合

dict = {"name": ["jack", "HanMeimei", "Lucy", "Mr Green", "Mrs Han", "Lily"],
"age": [100, 90, 98, 90, 100, 30], "salary": [30000, 50000, 999000, 90000, 80000, 75000]}
df7 = pd.DataFrame(dict, index=list("abcdef"))
print(df7)
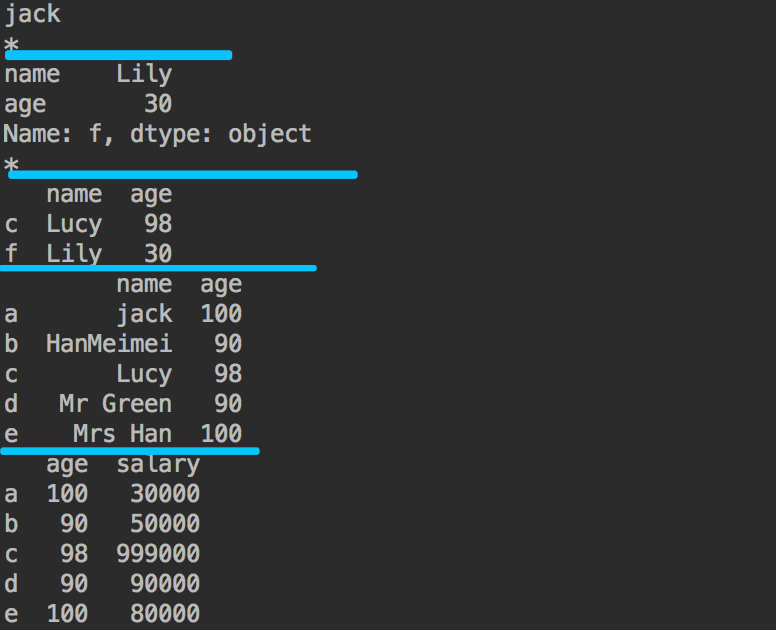
# 取出行标签为'a',列标签为'name'的元素
print(df7.loc['a', 'name'])
# 取出行标签为'f',列标签为['name','age']的元素
print(df7.loc['f', ['name', 'age']])
# 取出行标签为['c','f'],列标签为['name','age']的元素
print(df7.loc[['c', 'f'], ['name', 'age']])
# 切片+单选合并使用:取出行标签为 (切片'a':'e'),列标签为['name','age']的元素
# 注意切片闭合性
print(df7.loc['a':'e', ['name', 'age']])
# 切片使用:取出行标签为 (切片'a':'e'),列标签为['name','age']的元素
print(df7.loc['a':'e', 'age':'salary'])
5.1.2 取出单行 - 取出'a'行的所有数据
#以下的两种方式均可
df7.loc['a',:]
df7.loc['c']
name Lucy age 98 salary 999000
5.1.3 取出不连续多行 - 取出行标签为'a','c'的所有数据
df7.loc[['a','c']]#注意嵌套[]
5.1.4切片取出连续多行
df7['a':'c']
5.1.5 取出单列 - 取出列标签为'name'的所有数据
#以下的两种方式均可
print(df7.loc[:,'name'])
print(df7['name'])
a jack b HanMeimei c Lucy d Mr Green e Mrs Han f Lily
5.1.6 取出不连续多列 - 取出行标签为'name','age'的所有数据
df7.loc[:,['name','age']]
df7[['name', 'age']]

5.2 *记住下面的这一个就行了,记太多反而麻烦
基本格式为:
df7.loc[行,列]
如果取连续的行或者列---使用切片 :
如果取出来不连续的行或列—使用列表 [ ]
其中 切片和列表可以混合使用
举列:
5.5.1 连续多行多列
df7.loc['a':'c','name':'age']
注意:包含了b行,因为是行切片
> name age
a jack 100
b HanMeimei 90
c Lucy 98
5.5.2 不连续多行+连续多列
df7.loc[['a','c'],'name':'salary']
注意:行是不连续选择,只是a和c
列是连续切片,包含了中间的age
> name age salary
a jack 100 30000
c Lucy 98 999000
5.5.3 不连续多行+不连续多列
df7.loc[['a','c'],['name','salary']]
注意:行是不连续选择,只是a和c
列也是不连续选择,只是name和salary
> name salary
a jack 30000
c Lucy 999000
5.5.4 全部行+不连续多列(全部列同理)
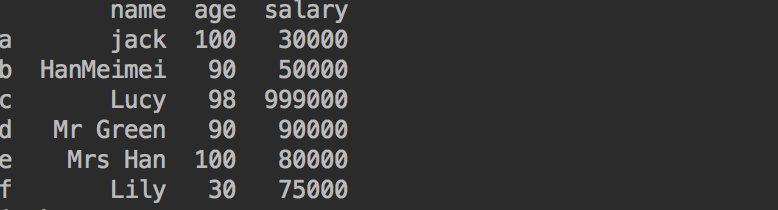
df7.loc[:,['name','salary']]
注意:只要把行写个空切片就行 :
> name salary
a jack 30000
b HanMeimei 50000
c Lucy 999000
d Mr Green 90000
e Mrs Han 80000
f Lily 75000
5.5.5 不连续多行+单列(单行同理)
df7.loc[['a','c'],'name']
注意:单列名没加[],结果是个Series
> a jack
c Lucy
Name: name, dtype: object
<class 'pandas.core.series.Series'>
df7.loc[['a','c'],['name']]
type(df7.loc[['a','c'],['name']])
注意:单列名加[],结果是个DataFrame
> name
a jack
c Lucy
<class 'pandas.core.frame.DataFrame'>
6. iloc 行、列切片
只是通过位置取值,原理与loc一样
只是注意,切片不包含最后一个数字,这点与loc不同

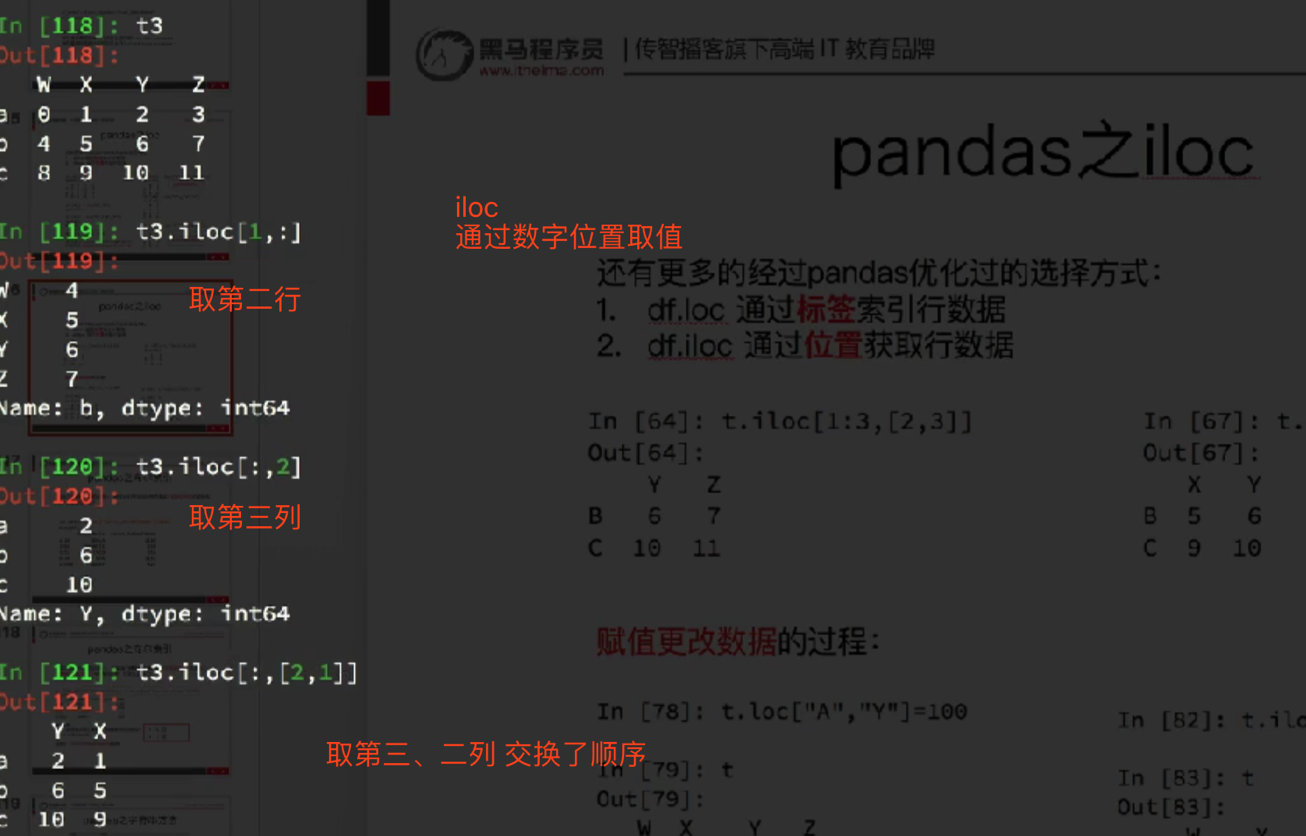
df7.iloc[[1,3],[0]]
> 取得不连续的行列
name
b HanMeimei
d Mr Green
df7.iloc[1:3,0:1]
> 没包含3的d ,没包含1的age
name
b HanMeimei
c Lucy
7. 赋值更改数据
可以使用loc,也可以使用iloc

df7.iloc[1:3,1:3]=99999999
print(df7)
> name age salary
a jack 100 30000
b HanMeimei 99999999 99999999
c Lucy 99999999 99999999
d Mr Green 90 90000
e Mrs Han 100 80000
f Lily 30 75000
8.布尔索引
一起看个例子吧
创建一个dataframe
Score = {"姓名": ["张无忌", "赵敏", "小乔", "大乔", "杨玉环", "貂蝉", "西施", "王子", "姜子牙", "李白", "杜甫", "王伟","李晓雨"],
"语文": [78, 90, 87, 88, 56, 94, 92, 85, 93, 91, 59, 100,100],
"数学": [91, 59, 100, 75, 30, 95, 91, 59, 100, 10, 95, 85,100],
"英语": [91, 59, 100, 75, 30, 95, 10, 95, 85, 75, 30, 95,100]}
df_score = pd.DataFrame(Score)
print(df_score)

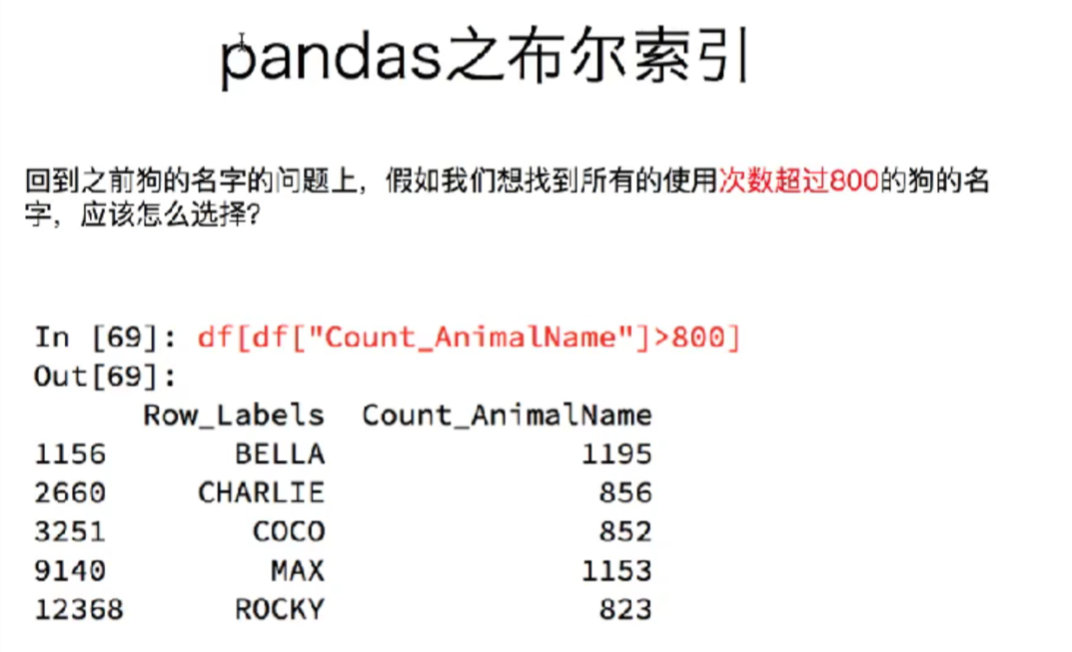
8.1 取出所有英语成绩大于90的人的数据
# 得到的是一个Series
loc_ = df_score.loc[:,"英语"] > 90
print(loc_)
print(type(loc_))# <class 'pandas.core.series.Series'>
# dataframe 布尔索引,会筛选出所有值为true的行
print(df_score[loc_])
# 也可以简写为
print(df_score[df_score.loc[:,"英语"]>90])


8.2 取出所有英语成绩小于90的人的数据(~)
注意:加 ~ 取反
print(df_score[~(df_score.loc[:, "英语"] > 90)])

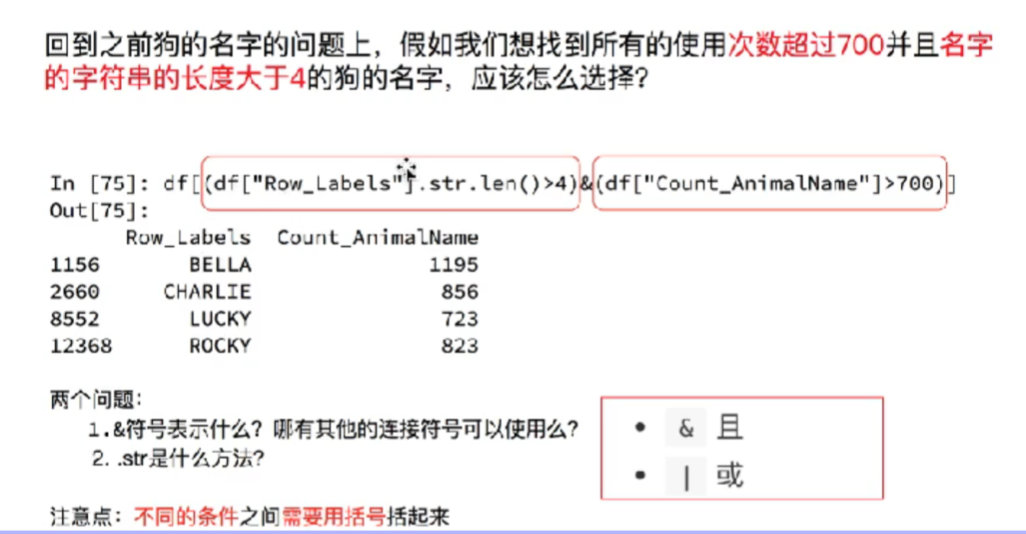
8.3 取出所有英语成绩大于90并且语文大于80人的数据
print(df_score[(df_score.loc[:, "英语"] > 90)&(df_score.loc[:, "语文"] < 80)])

8.4 知识点截图
9. 字符串方法
# 创建一个dataframe
student = {"姓名": ["张无忌", "赵敏", "小乔", "大乔", "杨玉环", "貂蝉", "西施", "王子", "姜子牙", "李白", "杜甫", "王伟", "李晓雨"],
"语文": [78, 90, 87, 88, 56, 94, 92, 85, 93, 91, 59, 100, 100],
"数学": [91, 59, 100, 75, 30, 95, 91, 59, 100, 10, 95, 85, 100],
"英语": [91, 59, 100, 75, 30, 95, 10, 95, 85, 75, 30, 95, 100],
"班级": ["一年级3班", "一年级1班", "二年级3班", "二年级1班", "一年级13班", "三年级7班", "五年级3班", "四年级3班", "一年级5班", "一年级7班", "一年级4班",
"一年级9班", "一年级10班"],
}
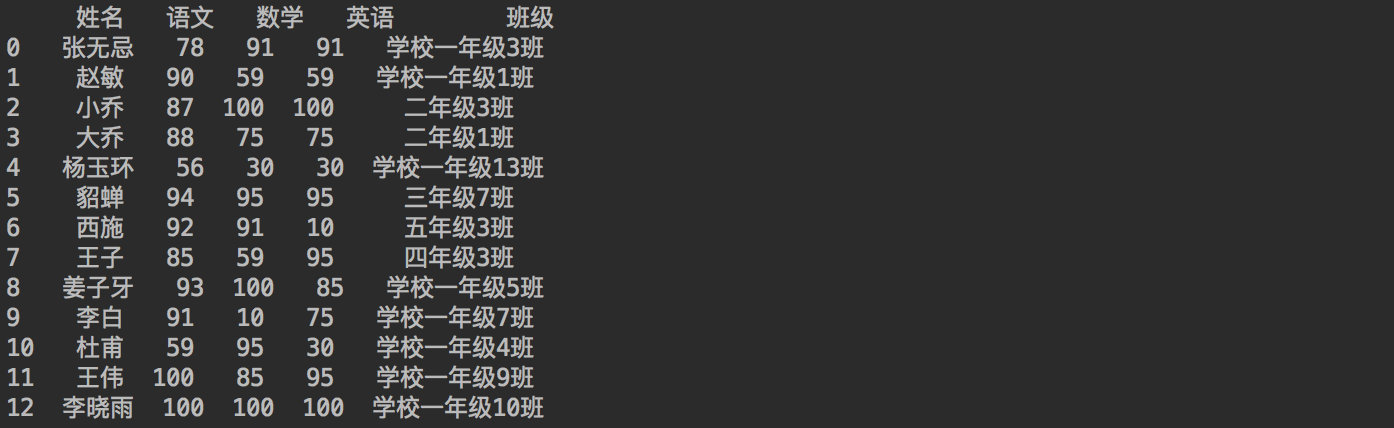
df_student = pd.DataFrame(student)
print(df_student)

9.1 len—选择【班级】列元素字符串长度大于5的数据
print(df_student[df_student["班级"].str.len() > 5])

9.2 replace—把【班级】列元素中的【年级】改为【学校一年级】
# 注意等号右侧返回一个Series,要把它赋值给原DataFrame对应的列
df_student["班级"] = df_student["班级"].str.replace("一年级", "学校一年级")
print(df_student)
# 下面是取列的loc用法
df_student.loc[:,"班级"] = df_student.loc[:,"班级"].str.replace("一年级", "学校一年级")
9.3 contains—筛选【班级】列包含“学校”和“1”的数据
print(df_student[
(df_student["班级"].str.contains("学校"))
&
(df_student["班级"].str.contains("1"))])

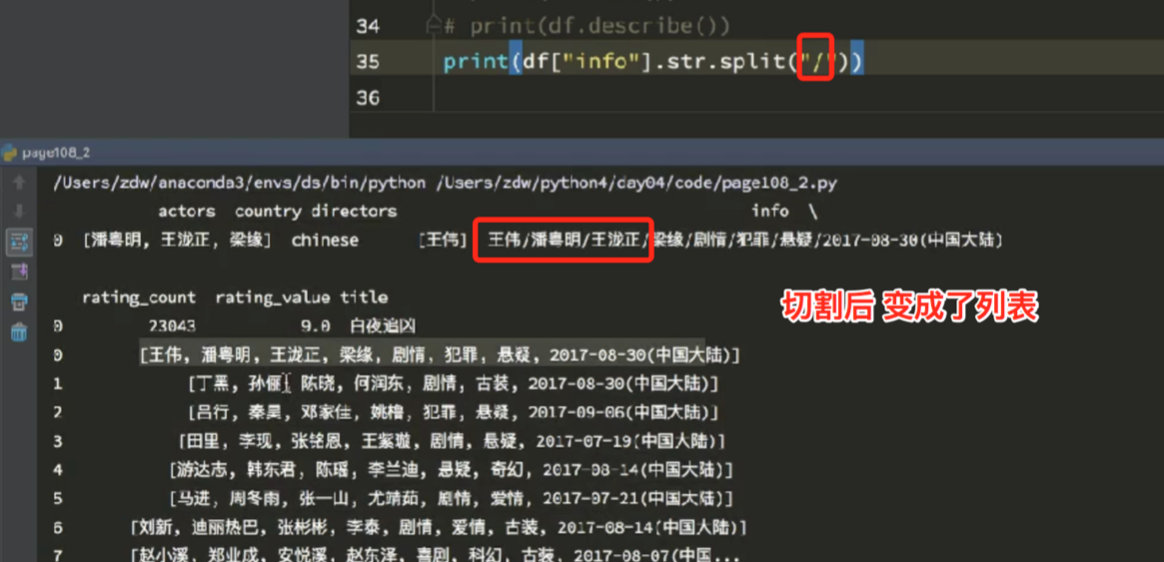
9.4 split—切割字符串
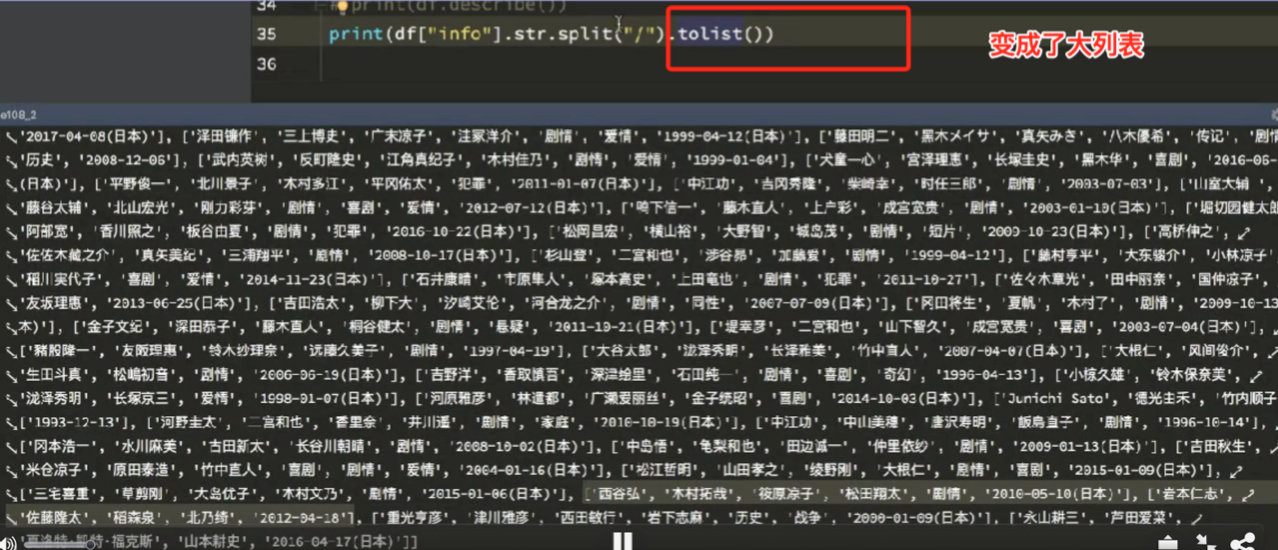
9.5 get—打印学生姓名的第一个字符(姓氏)
print((df_student["姓名"].str.get(0)))

9.6 match—正则表达式匹配,找出姓名包含'王|李'的数据
reg = '王|李'
print(df_student[df_student["姓名"].str.match(reg)])

9.7 pad—填充字符*
# 注意width=10表示,现在的字符+要填充的*,一起计算宽度为10
# 两侧都加*,最后得到的字符串长度为10,不足用*添加(也可以不写side,直接使用center函数)
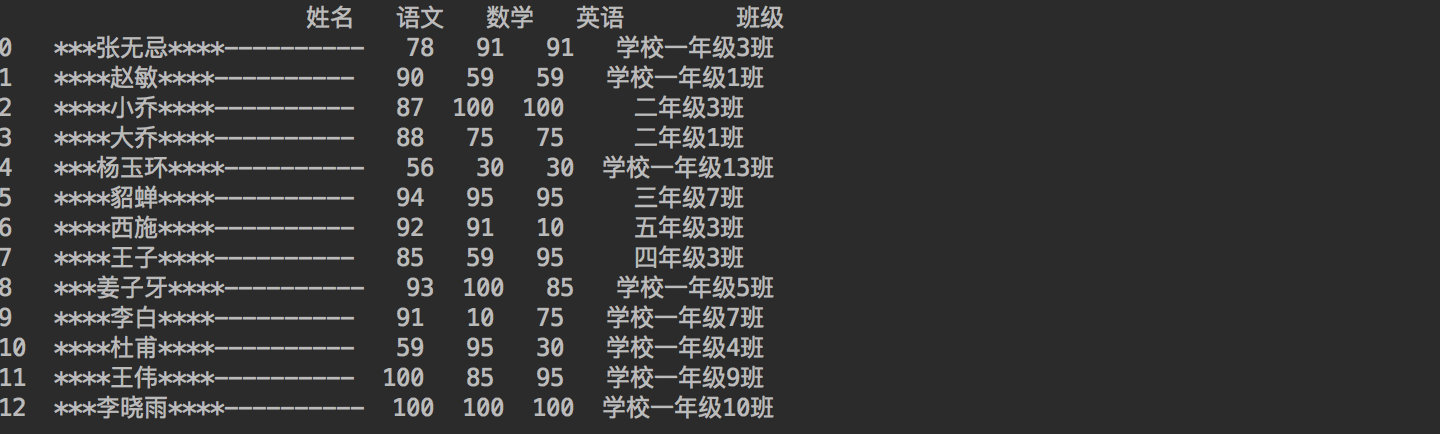
df_student["姓名"] = df_student["姓名"].str.pad(width=10, side='both', fillchar='*')
# 右侧都加—,最后得到的字符串长度为20,不足用-添加
df_student["姓名"] = df_student["姓名"].str.pad(width=20, side='right', fillchar='-')
print(df_student)
9.5 知识点截图

10. 新增一列统计总分 apply方法
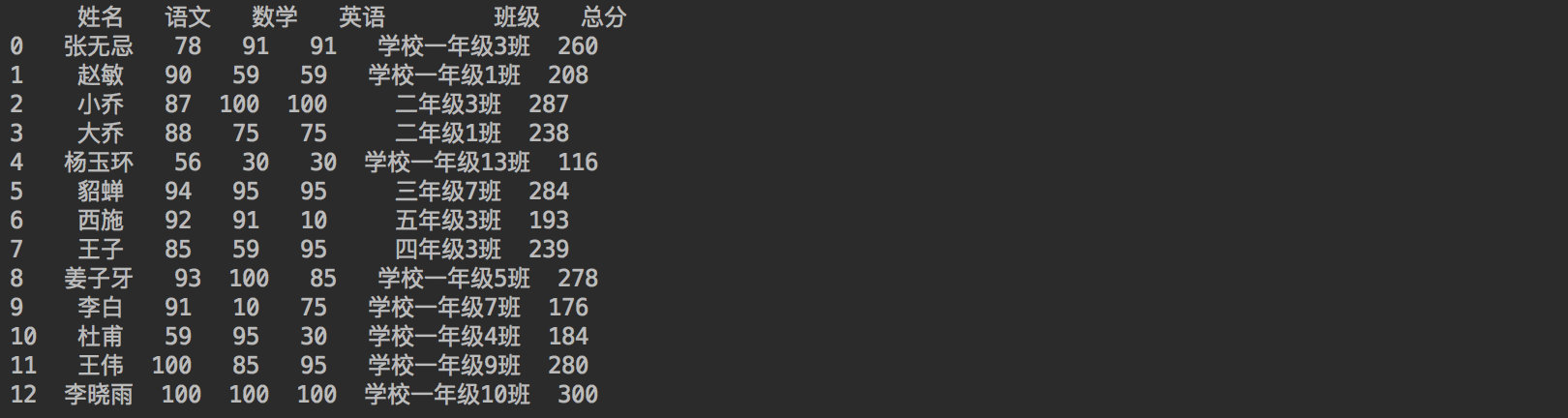
10.1 直接相加
df_student["总分"] = df_student["语文"] + df_student["数学"] + df_student["英语"]
10.2 使用Series的apply方法遍历(apply传入一个函数,更强大)
df_student['总分'] = pd.Series(df_student.index.tolist()).apply(
lambda i: df_student.loc[i, "语文"] + df_student.loc[i, "数学"] + df_student.loc[i, "英语"])
# 1.为了使用Series的apply方法,根据DataFrame的Index生成一个Series,
pd.Series(df_student.index.tolist())
# 2.后面是一个lambda表达式,也可以定义函数传递进去(写函数就可以做很多处理了),见下例
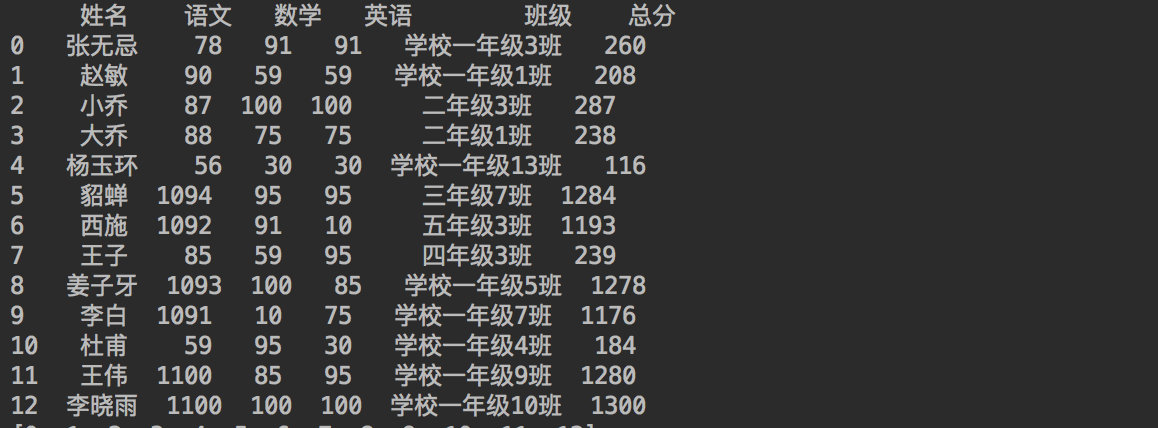
# 让语文大于90的人,让他的语文成绩再加上1000分,然后求总分
def sum1(i):
if df_student.loc[i, "语文"] > 90:
df_student.loc[i, "语文"] = df_student.loc[i, "语文"] + 1000
return df_student.loc[i, "语文"] + df_student.loc[i, "数学"] + df_student.loc[i, "英语"]
df_student['总分'] = pd.Series(df_student.index.tolist()).apply(
lambda i: sum1(i))
11. 缺失数据处理
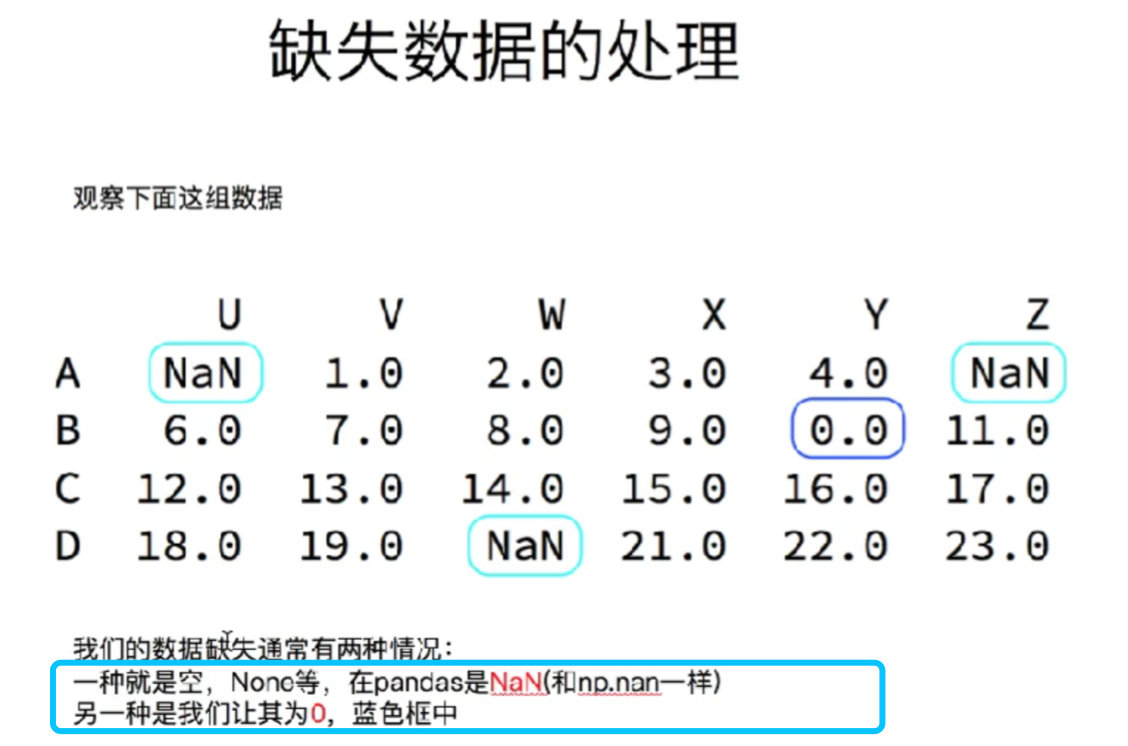
# 使用numpy生成一组随机整数(在0~100之间,形状为5行7列)
rand = np.random.randint(0, 100, (5, 7))
# 使用numpy上传的数据生成DataFrame
df = pd.DataFrame(rand, columns=list("ABCDEFG"))
# 定义一些NaN
df.loc[0:3, "A":"B"] = np.nan
print(df)

11.1 判断是不是NaN
11.1.1 判断整个df是不是Nan的情况
# 是null吗
print(pd.isnull(df))
结果是:DataFrame

# 不是null吗
print(pd.notnull(df))

11.1.2 判断df指定列是不是Nan的情况
# 打印A列里数据为NUll的数据
print(df[pd.isnull(df["A"])])

# 打印A列里数据不为NUll的数据
print(df[pd.notnull(df["A"])])

11.2 删除df里有nan的数据
# 不输入how参数,默认为any
# 只要有一个是NaN,就会删除该行
print(df.dropna(axis=0))

# 只有全部是NaN,才会删除该行
print(df.dropna(axis=0,how="all"))

