

以下笔记以及实验皆出自于 中华石杉大佬的视频教学,我跟着做了实验,并且把课上的笔记整理了一下。
更多阅读
redis持久化对于灾难恢复的意义
redis有一个持久化的功能,在很多的视频和资料中都有对持久化的介绍,那么持久化对于什么样场景有着重大的意义呢?
故障发生的时候会怎么样
在实际的情况中有着这样的情况,redis突然挂掉了,进程死了,或者所在的机器没了,遇到了灾难性的故障,因为redis的数据存在内存中
这时候内存中的数据就都没有了,很重要的缓存数据等等,redis会重启,重启之后要费很大的劲去恢复,如果单单把数据放到内存中,
是没有任何办法应对一些灾难性的故障的,所以redis中的持久化是很重要的。再通过定期备份数据,是可以恢复一部分数据的。
意义
在企业级的redis集群架构中,持久化的主要意义就是做灾难恢复,数据恢复。
redis中RDB和AOF两种持久化的介绍
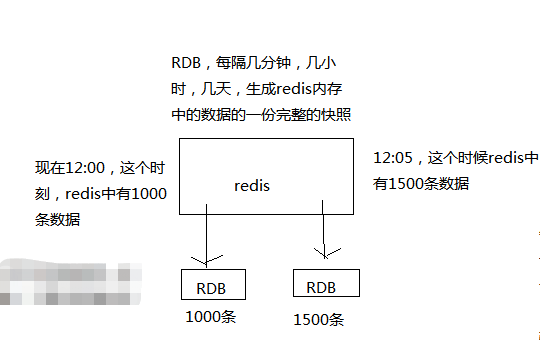
RDB持久化机制,对redis中的数据执行周期性的持久化存储,而且是完整的数据存储。 意思是假如每隔一个小时就存储一份现在redis内存中的全部数据。
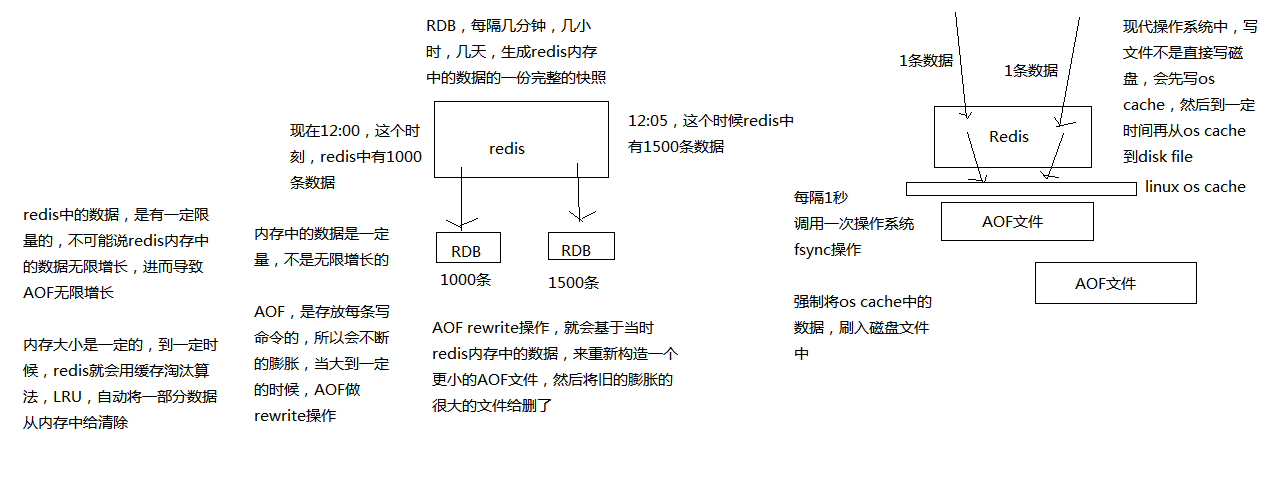
AOF机制对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在redis重启的时候,可以通过回放AOF日志中的写入指令来重新构建整个数据集
AOF的机制只对一个AOF日志文件做写入(仅追加 append-only)操作,在liunx系统中,中间会经过os cache然后才会写入磁盘中,AOF文件存放的是redis的写入指令。
假如内存中的数据最多存放1G,那么AOF文件的大小也将会被控制在1G范围之内,当内存中的数据超过1G的时候,AOF会利用一种缓存淘汰算法(LRU) 将最不常用的数据清除,而AOF的rewrite操作会基于redis清除后的内存中的数据重新构造一个更小的AOF文件,然后将旧的文件删除。
如果redis挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录中,然后重新启动redis,redis就会自动根据持久化数据文件中的数据,去恢复内存中的数据,继续对外提供服务 如果同时使用RDB和AOF两种持久化机制,那么在redis重启的时候,会使用AOF来重新构建数据,因为AOF中的数据更加完整。
RDB持久化机制的优点
-
RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说Amazon的S3云服务上去, 在国内可以是阿里云的ODPS分布式存储上,以预定好的备份策略来定期备份redis中的数据
-
RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可
-
相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复redis进程,更加快速
RDB持久化机制的缺点
-
如果想要在redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据
-
RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒,所以一般不要间隔太长时间进行持久化操作。
AOF持久化机制的优点
-
AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据
-
AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复
-
AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在rewrite log的时候,会对其中的指导进行压缩,创建出一份需要恢复数据的最小日志出来。再创建新日志文件的时候,老的日志文件还是照常写入。 当新的merge后的日志文件ready的时候,再交换新老日志文件即可。
-
AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件, 将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
AOF持久化机制的缺点
-
对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
-
AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
-
以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似AOF这种较为复杂的基于命令日志/merge/回放的方式,比基于RDB每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有bug。 不过AOF就是为了避免rewrite过程导致的bug,因此每次rewrite并不是基于旧的指令日志进行merge的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
RDB和AOF到底该如何选择
-
不要仅仅使用RDB,因为那样会导致你丢失很多数据
-
也不要仅仅使用AOF,因为那样有两个问题,第一,你通过AOF做冷备,没有RDB做冷备,来的恢复速度更快; 第二,RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug
-
综合使用AOF和RDB两种持久化机制,用AOF来保证数据不丢失,作为数据恢复的第一选择; 用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复
实现redis持久化
首先实现Redis中的两种持久化,并且做一些实验来测试一下两种持久化是否生效。 AOF持久化,默认是关闭的,默认是打开RDB持久化
配置文件路径以及后面的所有路径都是以我自己的为主。自己的配置文件在哪里自己就在哪去配就可以了,下面的所有的路径都按自己的路径走,不要盲目按照我的来,除非你按照我的环境来搭建的。
RDB持久化
如何配置RDB持久化机制
redis.conf文件,也就是/etc/redis/6379.conf,去配置持久化,
找到以下类似配置项,在vi中使用/save即可查找指定的save字符,:noh取消高亮
save 60 1000
每隔60s,如果有超过1000个key发生了变更,那么就生成一个新的dump.rdb文件,就是当前redis内存中完整的数据快照, 这个操作也被称之为snapshotting(快照)
也可以手动调用save或者bgsave命令,同步或异步执行rdb快照生成
save可以设置多个,就是多个snapshotting检查点,每到一个检查点,就会去check一下,是否有指定的key数量发生了变更,如果有, 就生成一个新的dump.rdb文件
RDB持久化机制的工作流程
- redis根据配置自己尝试去生成rdb快照文件
- fork一个子进程出来
- 子进程尝试将数据dump到临时的rdb快照文件中
- 完成rdb快照文件的生成之后,就替换之前的旧的快照文件
dump.rdb,每次生成一个新的快照,都会覆盖之前的老快照
基于RDB持久化机制的数据恢复实验
- 实验1,首先使用命令 redis-cli 进入redis命令行,保存几条数据并且重启redis,看刚刚的数据是否还能查询的到。
$ redis-cli
$ set k1 v1
$ set k2 v2
$ exit
$ redis-cli SHUTDOWN
# 进入/etc/init.d文件下,使用redis_6379脚本重启redis
$ cd /etc/init.d
$ ./redis_6379 start
$ redis-cli
$ get k1
"v1"
$ get k2
"v2"
执行以上命令后,可以看到如果正常退出的redis,数据还在,这是因为通过redis-cli SHUTDOWN这种方式去停掉redis,其实是一种安全退出的模式, redis在退出的时候会将内存中的数据立即生成一份完整的rdb快照
- 实验2,再次在redis中存入几条数据,这次我们使用kill -9 暴力杀死redis的进程并且删除/var/run/redis_6379.pid文件后,看是否还能查询到数据
$ set k3 v3
$ set k4 v4
$ exit
# 通过ps -ef | grep redis 查看redis的进程
$ ps -ef | grep redis
$ kill -9 62789
# 一定要注意-rf不会提示你删除,确认好文件后在进行删除
$ rm -rf /var/run/redis_6379.pid
# 再次重启redis
$ cd /etc/init.d
$ ./redis_6379 start
$ redis-cli
$ get k3
(nil)
$ get k4
(nil)
这回保存的新数据都没有了,是因为还没有到配置的检查点的时候,出现了意外,这时候就无法保存rdb文件了,也就丢失了文件,所以这也是RDB的一个缺点。
- 实验3,设置间隔短的保存点,重启redis进程,并且重复实验2的步骤
$ vi /etc/redis/6379.conf
# 找到save 60 1000类似的设置后添加以下内容保存退出
save 5 1
# 表明每5秒检查一次,只有有一条插入的数据就生成快照文件rdb,即保存了数据。
$ redis-cli SHUTDOWN
$ /etc/init.d/redis_6379 start
# 重复实验2的步骤,插入新的数据
实验3表明RDB的持久化通过我们手动设置,确实保存了内存中的数据,做到了持久化,但是配置中不建议配置间隔这么短的检查点
AOF持久化
AOF持久化,默认是关闭的,默认是打开RDB持久化
如何配置AOF的持久化
在配置文件中找到 appendonly no,设置为 yes 可以打开AOF持久化机制,在生产环境里面,一般来说AOF都是要打开的, 除非你说随便丢个几分钟的数据也无所谓打开AOF持久化机制之后,redis每次接收到一条写命令,就会写入日志文件中,当然是先写入os cache的, 然后每隔一定时间再fsync一下,而且即使AOF和RDB都开启了,redis重启的时候,也是优先通过AOF进行数据恢复的,因为aof数据比较完整
AOF的fsync策略
在redis的配置文件中找到appendfsync everysec有三种策略提供给我们使用,默认everysec,也是我们经常使用的
-
always: 每次写入一条数据,立即将这个数据对应的写日志fsync到磁盘上去,性能非常非常差,吞吐量很低; 如果一定要确保说redis里的数据一条都不丢,那就只能这样了
-
everysec: 每秒将os cache中的数据fsync到磁盘,这个最常用的,生产环境一般都这么配置,性能很高,QPS还是可以上万的
-
no:仅仅redis负责将数据写入os cache就撒手不管了,然后后面os自己会时不时有自己的策略将数据刷入磁盘,不可控了
AOF持久化的数据恢复实验
-
实验1,先仅仅打开RDB,写入一些数据,然后kill -9杀掉redis进程并且删除/var/run/redis_6379.pid文件,接着重启redis,发现数据没了, 因为RDB快照还没生成,检查点不能太短,否则数据就被保存了,这个就不写命令了,按照上面的RDB实验即可。
-
实验2,打开AOF的开关,启用AOF的持久化,重启redis进程,写入一些数据,观察AOF文件中的日志内容,kill -9杀掉redis进程,重新启动redis进程, 发现数据被恢复回来了,就是从AOF文件中恢复回来的,它们其实就是先写入os cache的,然后1秒后才fsync到磁盘中,只有fsync到磁盘中了,才是安全的, 要不然光是在os cache中,机器只要重启,就什么都没了,持久化文件我们配置了在 /var/redis/6379 中
$ vi /etc/redis/6379.conf
appendonly yes
$ redis-cli SHUTDOWN
$ /etc/init.d/redis_6379 start
$ redis-cli
$ set mykey1 k1
$ set mykey2 k2
$ exit
$ ps -ef | grep redis
$ kill -9 32523
$ rm -rf /var/run/redis_6379.pid
$ /etc/init.d/redis_6379 start
$ redis-cli
$ get mykey1
"k1"
$ get mykey2
"k2"
实验证明了,在我们开启了AOF后,可以在意外发生的时候正常的保存我们的数据,而RDB因为没有到达检查点,并没有保存我们的数据, 所以生产环境中我们有必要把RDB和AOF两种持久化都开启
AOF rewrite操作
redis中的数据其实有限的,很多数据可能会自动过期,可能会被用户删除,可能会被redis用缓存清除的算法清理掉,redis中的数据会不断淘汰掉旧的, 就一部分常用的数据会被自动保留在redis内存中
所以可能很多之前的已经被清理掉的数据,对应的写日志还停留在AOF中,AOF日志文件就一个,会不断的膨胀,到很大很大
所以AOF会自动在后台每隔一定时间做rewrite操作,比如日志里已经存放了针对100w数据的写日志了; redis内存只剩下10万; 基于内存中当前的10万数据构建一套最新的日志,到AOF中; 覆盖之前的老日志; 确保AOF日志文件不会过大,保持跟redis内存数据量一致
redis 2.4之前,还需要手动,开发一些脚本,crontab,通过BGREWRITEAOF命令去执行AOF rewrite,但是redis 2.4之后,会自动进行rewrite操作
在redis的配置文件中我们可以配置rewrite的策略
- auto-aof-rewrite-percentage 100,这个属性代表着百分比,增长的百分比到达100%,就是一倍,基于上一次rewrite后文件的大小
- auto-aof-rewrite-min-size 64mb,这个属性代表增长后的总大小要大于64mb
举例
比如说上一次AOF rewrite之后,是128mb 然后就会接着128mb继续写AOF的日志,如果发现增长的比例,超过了之前的100%,256mb,就可能会去触发一次rewrite 但是此时还要去跟min-size,64mb去比较,256mb > 64mb,才会去触发rewrite
rewrite工作流程
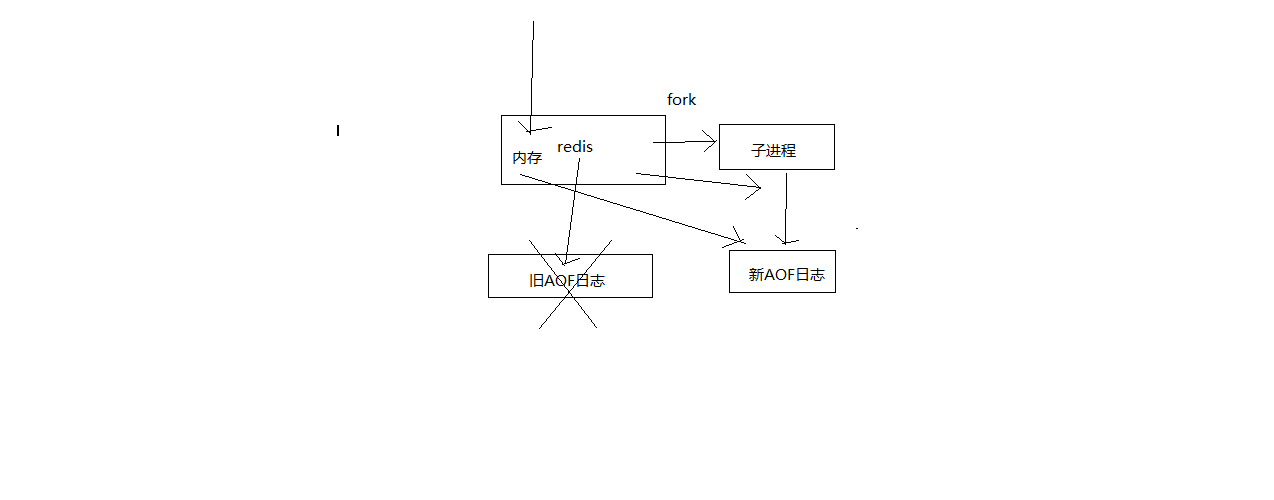
- redis fork一个子进程
- 子进程基于当前内存中的数据,构建日志,开始往一个新的临时的AOF文件中写入日志
- redis主进程,接收到client新的写操作之后,在内存中写入日志,同时新的日志也继续写入旧的AOF文件
- 子进程写完新的日志文件之后,redis主进程将内存中的新日志再次追加到新的AOF文件中
- 用新的日志文件替换掉旧的日志文件
AOF的破损文件的修复
如果redis在append数据到AOF文件时,机器宕机了,可能会导致AOF文件破损
用redis-check-aof --fix命令来修复破损的AOF文件,这个命令存在于redis的安装包下src文件中
这个破损文件的修复就是把文件中最后面不完整命令给删除掉,所以修复也会导致部分数据丢失,但是总好过所有数据全部丢失。
AOF和RDB同时工作
- 如果RDB在执行snapshotting操作,那么redis不会执行AOF rewrite; 如果redis再执行AOF rewrite,那么就不会执行RDB snapshotting
- 如果RDB在执行snapshotting,此时用户执行BGREWRITEAOF命令,那么等RDB快照生成之后,才会去执行AOF rewrite
- 同时有RDB snapshot文件和AOF日志文件,那么redis重启的时候,会优先使用AOF进行数据恢复,因为其中的日志更完整
- 实验3,
- 在有rdb的dump和aof的appendonly的同时,rdb里也有部分数据,aof里也有部分数据,这个时候其实会发现,rdb的数据不会恢复到内存中
- 我们模拟让aof破损,手动删除aof文件后面的指令变成不完整,然后fix,有一条数据会被fix删除
- 再次用fix修复后的aof文件去重启redis,发现数据只剩下一条了
为什么rdb不会恢复到内存中呢,这是因为redis会优先使用aof文件来恢复数据,所以在有aof文件的情况下,rdb文件是不会被恢复的
总结
总体来说redis在我们的项目中作为缓存是非常重要的,为我们的mysql等数据库分担了很多的压力,而缓存中的数据又是重中之重,所以redis中的持久化对我们来讲就是必须要会的一点知识
这章节讲述了以下几点
-
持久化的意义?
-
对于出现灾难性的意外如何应对?
采用持久化和周期性备份来应对灾难性的出现
- 两种持久化的优劣对比
通过上面的两种的持久化方式来看,数据恢复完全依赖于底层的磁盘的持久化,如果rdb和aof上都没有数据,或者这两个文件都丢了,那么就真的没有了 所以在有条件的情况下,需要对适合做冷备的rdb文件周期性的备份也算是做最后的防线吧
