

在上一篇文章 大猪 已经介绍了日志存储设计方案 ,我们数据已经落地到数据中心上了,那接下来如何ETL呢?毕竟可是生产环境级别的,可不能乱来。其实只要解决几个问题即可,不必要引入很大级别的组件来做,当然了各有各的千秋,本文主要从 易懂、小巧 、简洁、 高性能 这三个方面去设计出发点,顺便还实现了一个精巧的 Filebeat。
设计
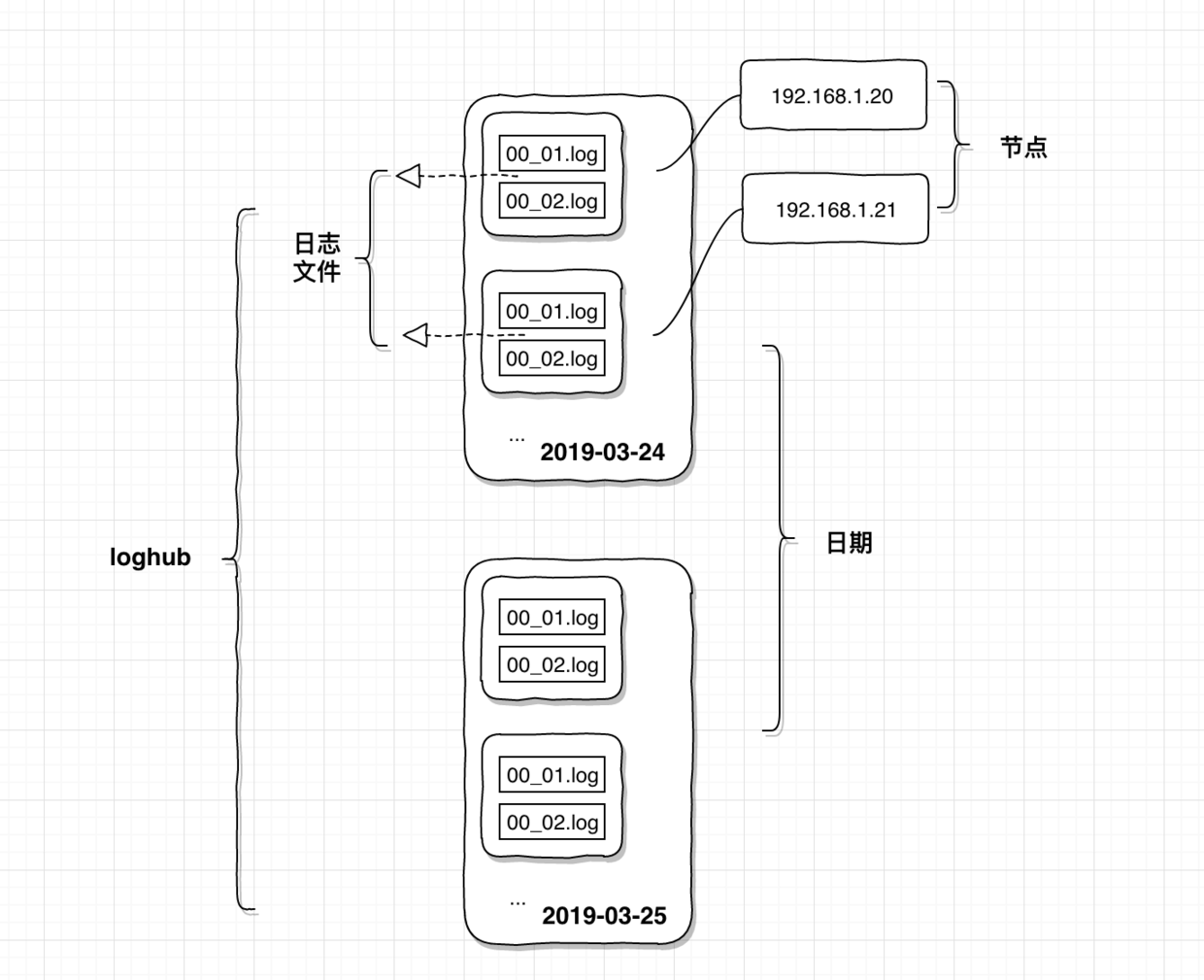
loghub功能 要实现的功能就是扫描每天的增量日志并写入Hbase中
需要攻克如下几个小难题
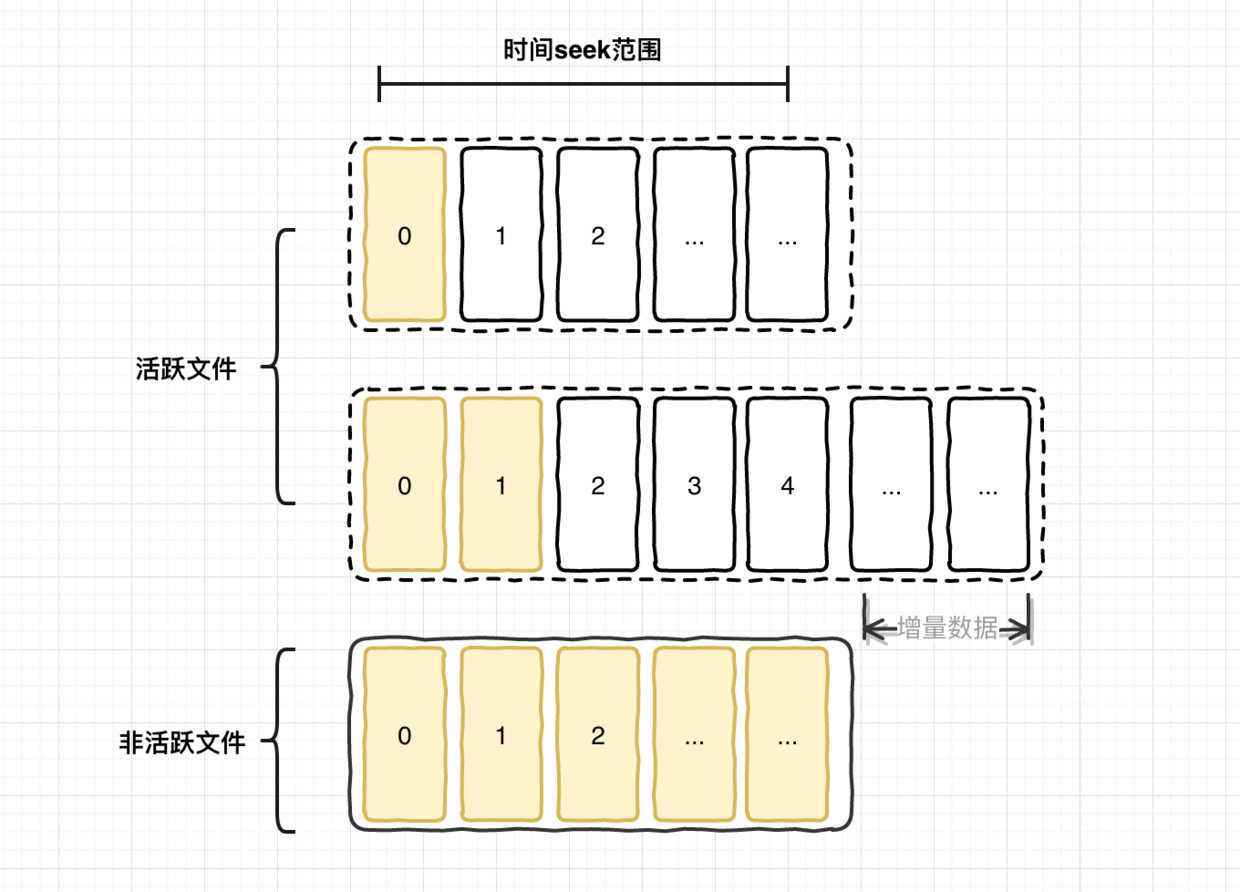
- 需要把文件中的每一行数据都取出来
- 能处理超过10G以上的大日志文件,并且只能占用机器一定的内存,越小越好
- 从上图可以看到 标黄 的是已经写入Hbase的数据,不能重复读取
- 非活跃文件不能扫,因为文件过多会影响整体读取IO性能
- 读取中的过程要保证增量数据不能录入,因为要保证offset的时候写入mysql稳定不跳跃
实现
大猪 根据线上的生产环境一一把上面的功能重新分析给实现一下。
从第一点看还是比较简单的嘛?但是我们要结合上面的 5 个问题来看才行。
总结一句话就是:要实现一个高性能而且能随时重启继续工作的 loghub ETL 程序。
实际也必需这样做,因为生产环境容不得马虎,不然就等着被BOSS

实现过程
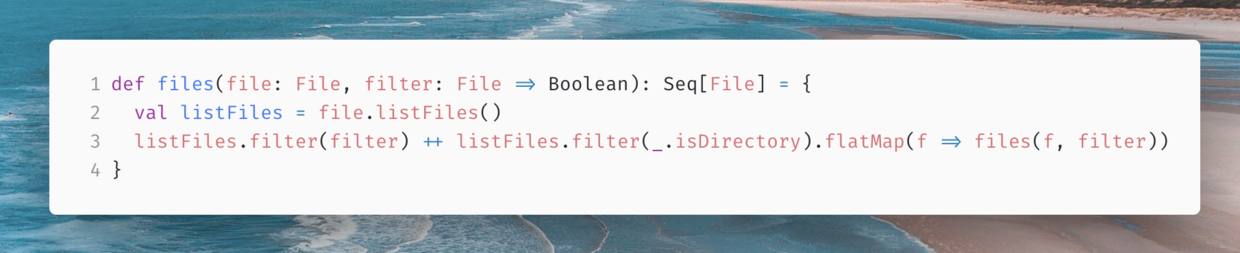
需要有一个读取所有日志文件方法
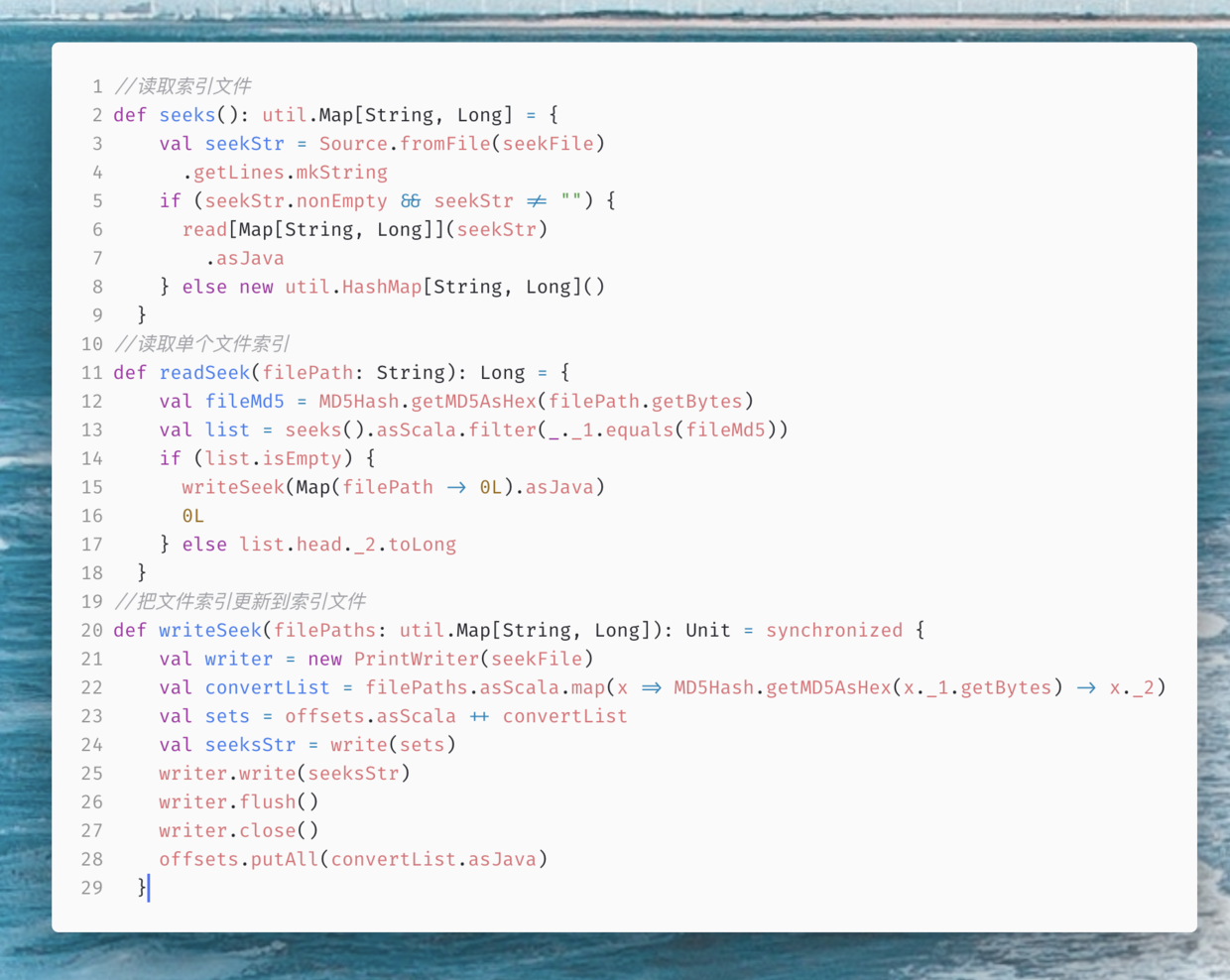
还要实现一个保存并读取文件进度的方法
由于不能把一个日志文件全部读入内存进行处理 所以还需要一个能根据索引一行一行接着读取数据的方法
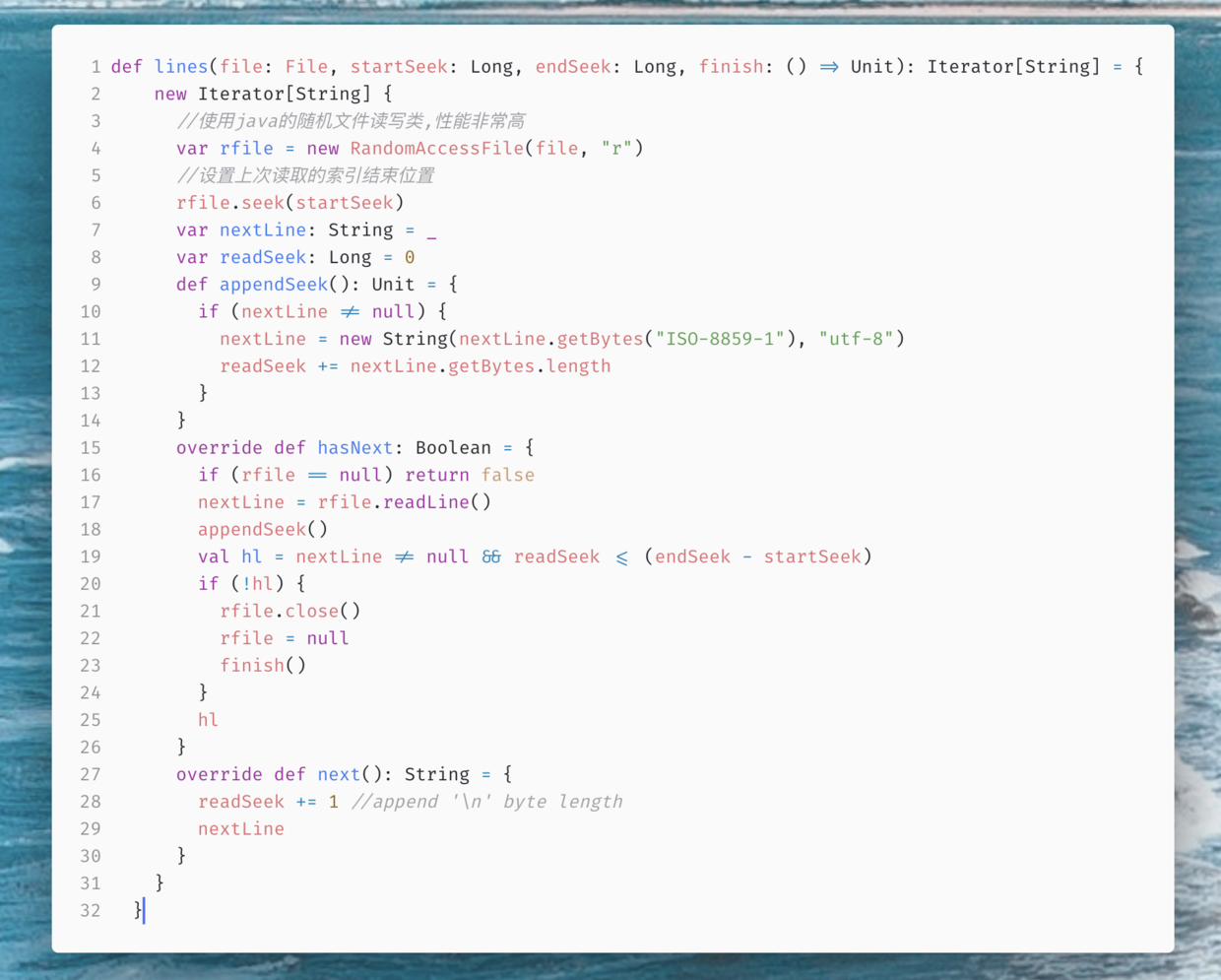
最后剩下一个Hbase的连接池小工具
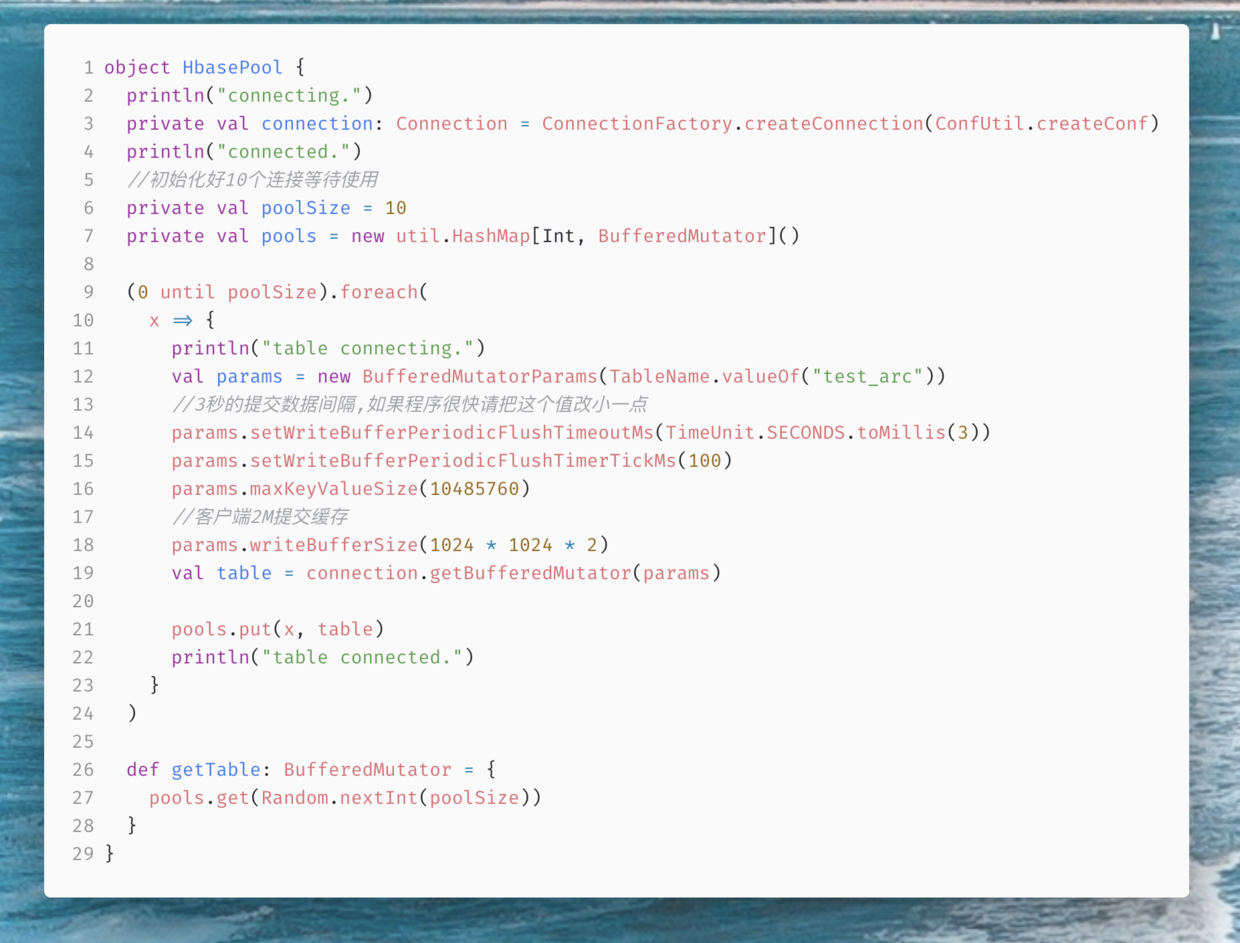
几个核心方法已经写完了,接着是我们的主程序
def run(logPath: File, defaultOffsetDay: String): Unit = {
val sdfstr = Source.fromFile(seekDayFile).getLines().mkString
val offsetDay = Option(if (sdfstr == "") null else sdfstr)
//读取设置读取日期的倒数一天之后的日期文件夹
val noneOffsetFold = logPath
.listFiles()
.filter(_.getName >= LocalDate.parse(offsetDay.getOrElse(defaultOffsetDay)).minusDays(1).toString)
.sortBy(f => LocalDate.parse(f.getName).toEpochDay)
//读取文件夹中的所有日志文件,并取出索引进行匹配
val filesPar = noneOffsetFold
.flatMap(files(_, file => file.getName.endsWith(".log")))
.map(file => (file, seeks().getOrDefault(MD5Hash.getMD5AsHex(file.getAbsolutePath.getBytes()), 0), file.length()))
.filter(tp2 => {
//过滤出新文件,与有增量的日志文件
val fileMd5 = MD5Hash.getMD5AsHex(tp2._1.getAbsolutePath.getBytes())
val result = offsets.asScala.filter(m => fileMd5.equals(m._1))
result.isEmpty || tp2._3 > result.head._2
})
.par
filesPar.tasksupport = pool
val willUpdateOffset = new util.HashMap[String, Long]()
val formatter = DateTimeFormatter.ofPattern("yyyyMMddHHmmssSSS")
var logTime:String = null
filesPar
.foreach(tp3 => {
val hbaseClient = HbasePool.getTable
//因为不能全量读取数据,所有只能一条一条读取,批量提出交给HbaseClient的客户端的mutate方式优雅处理
//foreach 里面的部分就是我们的业务处理部分
lines(tp3._1, tp3._2, tp3._3, () => {
willUpdateOffset.put(tp3._1.getAbsolutePath, tp3._3)
offsets.put(MD5Hash.getMD5AsHex(tp3._1.getAbsolutePath.getBytes), tp3._3)
})
.foreach(line => {
val jsonObject = parse(line)
val time = (jsonObject \ "time").extract[Long]
val data = jsonObject \ "data"
val dataMap = data.values.asInstanceOf[Map[String, Any]]
.filter(_._2 != null)
.map(x => x._1 -> x._2.toString)
val uid = dataMap("uid")
logTime = time.getLocalDateTime.toString
val rowkey = uid.take(2) + "|" + time.getLocalDateTime.format(formatter) + "|" + uid.substring(2, 8)
val row = new Put(Bytes.toBytes(rowkey))
dataMap.foreach(tp2 => row.addColumn(Bytes.toBytes("info"), Bytes.toBytes(tp2._1), Bytes.toBytes(tp2._2)))
hbaseClient.mutate(row)
})
hbaseClient.flush()
})
//更新索引到文件上
writeSeek(willUpdateOffset)
//更新索引日期到文件上
writeSeekDay(noneOffsetFold.last.getName)
//把 logTime offset 写到mysql中,方便Spark+Hbase程序读取并计算
}
程序很精简,没有任何没用的功能在里面,线上的生产环境就应该是这子的了。 大家还可以根据需求加入程序退出发邮件通知功能之类的。 真正去算了一下也就100行功能代码,而且占用极小的内存,都不到100M,很精很精。

传送门 完整ETL程序源码

