

Introduction
「Producer-Consumer」问题是资工系很常用来解释讯息交换的一种范例,用生产者跟消费者间的关系来描述讯息的传递。生产者负责产生资料并放在有限或是无限的缓冲区让等待消费者来处理。串流资料(Streaming Data)本质上就是一端不断的丢出资料,另一端需要持续地进行处理,就像 Producer-Consumer 一样。
Kafka 是近期一个用来处理串流资料的热们框架,其概念的示意图如下:
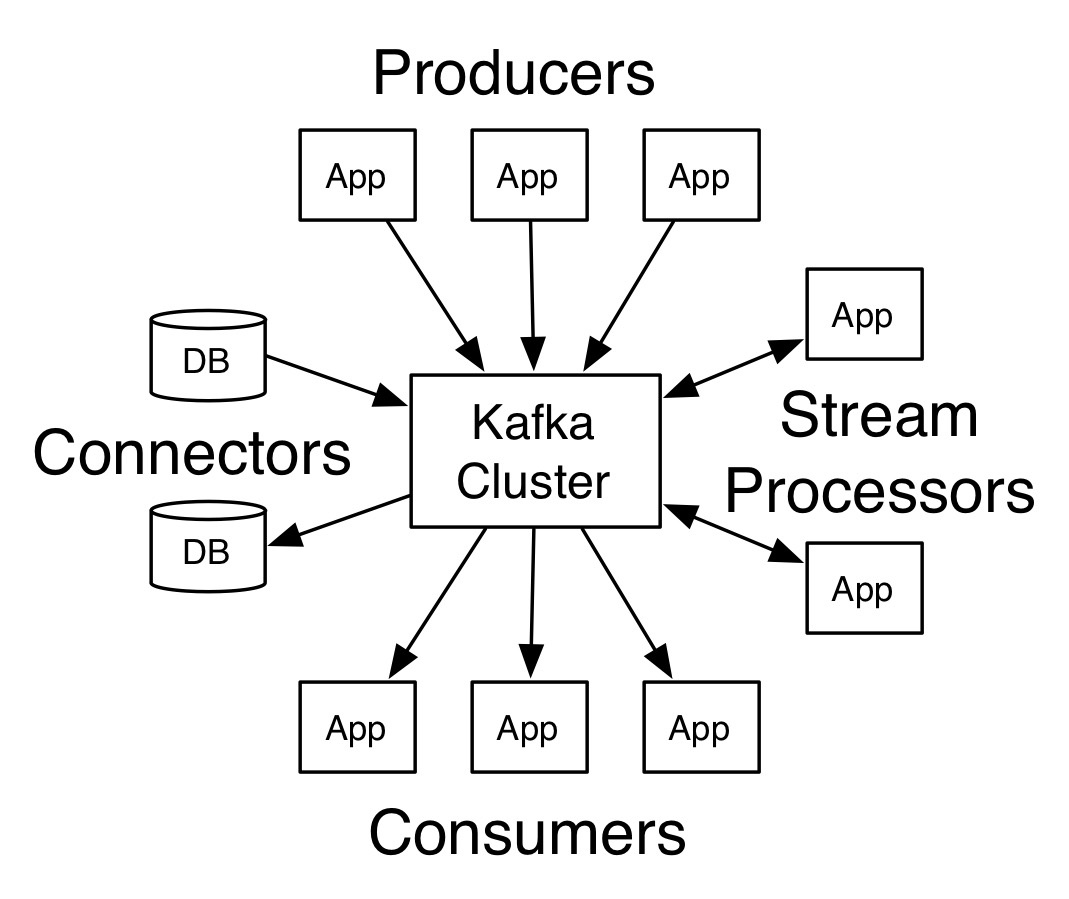
接到串流资料之后我们可以搭配 Spark 进行处理:
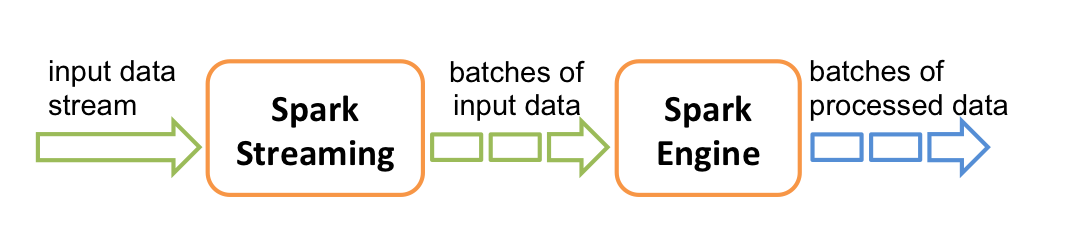
串起来之后,一个很典型的应用就像这样:
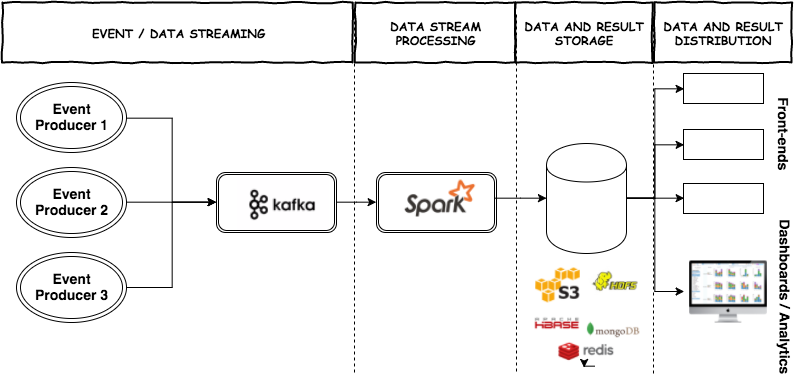
Kafka 是什么?
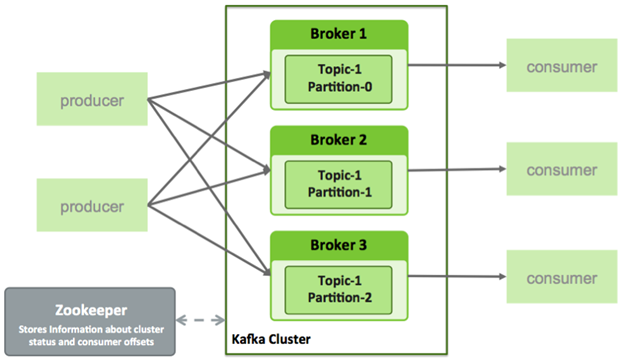
Kafka 是由 Apache 软体基金会开发的一个开源流处理平台,目标是为处理即时资料提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个「按照分散式事务纪录档架构的大规模发布订阅讯息伫列」。
相关的术语有:
- Topic:用来对讯息进行分类,每个进入到 Kafka 的资讯都会被放到一个 Topic 下
- Broker:用来实现资料储存的主机伺服器
- Partition:每个 Topic 中的讯息会被分为若干个 Partition ,以提高讯息的处理效率
Spark/PySpark 是什么?
Apache Spark 是一个延伸于 Hadoop MapReduce 的开源丛集运算框架,Spark 使用了记忆体内运算技术,能在资料尚未写入硬碟时即在记忆体内分析运算。简单来说就是一个利用分散式架构的资料运算工具,其主要的运算也是利用 Map - Reduce 的 运算逻辑。 Spark 原本是用 Java/Scala 做开发,PySpark 是一个封装后的介面,适合 Python 开发者使用。
环境准备
- kafka + zookeeper
我们直接用 brew kafka 比较方便,安装之后再到资料夹中确认使用设定档都存在。这边可以补充一下 ZooKeeper 是一个 Hadoop 的分散式资源管理工具,kafka 也可以用它来做资源的管理与分配。如果直接用 brew 安装的话,zookeeper 也会一并安装。
$ brew install kafka
$ ls /usr/local/etc/kafka # kafka 跟 zookeeper 设定档会放在此资料夹下
connect-console-sink.properties consumer.properties
connect-console-source.properties log4j.properties
connect-distributed.properties producer.properties
connect-file-sink.properties server.properties
connect-file-source.properties tools-log4j.properties
connect-log4j.properties trogdor.conf
connect-standalone.properties zookeeper.properties
- PySpark
$ pip install pyspark
$ pyspark
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Python version 3.5.2 (default, Nov 30 2016 12:41:46)
SparkSession available as 'spark'.
如果有出现找不到 SPARK_HOME 的错误讯息,在另外要配置一下的环境变数
# Could not find valid SPARK_HOME while searching
# ['/home/user', '/home/user/.local/bin']
export PYSPARK_PYTHON=python3
export SPARK_HOME=/Users/wei/Envs/py3dev/lib/python3.5/site-packages/pyspark
- JAVA8
$ brew cask install java8
$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
另外要配置一下 JAVA_HOME 的环境变数
export JAVA_HOME=$(/usr/libexec/java_home -v 1.8)
Workflow
⓪ 先切换到 kafka 安装的目录下
cd /usr/local/Cellar/kafka/_________(版本号)
① 启动 zookeeper 服务(需要长驻执行在背景)
./bin/zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties
② 启动 kafka 服务(需要长驻执行在背景)
./bin/kafka-server-start /usr/local/etc/kafka/server.properties
③ 创建/查看 Topic
# 建一个名为 test-kafka 的 Topic
./bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test-kafka
# 查看目前已经建立过的 Topic
./bin/kafka-topics --list --zookeeper localhost:2181\n\n
Streaming Data
产生与接收串流资料的方法有三种,可以使用 kafka-console 指令、kafka-python 套件,也可以使用 PySpark 来处,以下示范简单的程式码:
kafka-console
① Producer
使用指令(kafka-console-producer)产生串流资料到特定的 Topic
$ ./bin/kafka-console-producer --broker-list localhost:9092 --topic test-kafka
② Costomer
使用指令(kafka-console-consumer)从特定的 Topic 接收串流资料
$ ./bin/kafka-console-consumer --bootstrap-server localhost:9092 --topic test-kafka --from-beginning
kafka-python
① Producer
from kafka import KafkaProducer
import time
brokers, topic = 'localhost:9092', 'test-kafka'
def start():
while True:
print(" --- produce ---")
time.sleep(10)
producer.send('topic', key=b'foo', value=b'bar')
producer.flush()
if __name__ == '__main__':
producer = KafkaProducer(bootstrap_servers=brokers)
start()
producer.close()
执行:
$ python kafka-producer.py
② Costomer
from kafka import KafkaConsumer
brokers, topic = 'localhost:9092', 'test-kafka'
if __name__ == '__main__':
consumer = KafkaConsumer(topic, group_id='test-consumer-group', bootstrap_servers=[brokers])
for msg in consumer:
print("key=%s, value=%s" % (msg.key, msg.value))
执行:
$ python kafka-costomer.py
PySpark
① Costomer
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
brokers, topic = 'localhost:9092', 'test-kafka'
if __name__ == "__main__":
sc = SparkContext(appName="PythonStreamingDirectKafkaWordCount")
ssc = StreamingContext(sc, 10)
kvs = KafkaUtils.createDirectStream(ssc, [topic], {"metadata.broker.list": brokers})
lines = kvs.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(" "))
ssc.start()
ssc.awaitTermination()
执行 pyspark 的执行要用 spark-submit 指令,而且要加上 kafka 的配置档 (所以要在同目录下下载 spark-streaming-kafka-0-8-assembly_2.11-2.1.0.jar 配置档)
$ spark-submit --jars spark-streaming-kafka-0-8-assembly_2.11-2.1.0.jar pyspark-consumer.py
Connect Producer & Costomer
可以利用以上不同的 Producer 方法对同一个 topic 发送讯息,然后用 Costomer 的方法来接收!
小结
本系列预计会有三篇文章,把一个串流资料从来源到资料库的过程走过一次:
- 在 mac 上建立 Python 的 Kafka 与 Spark 环境 <- 本篇
- Kafka 串接 Twitter Streaming API
- Spark 接收 Kafka 资料后储存
Reference
- mac下kafka环境搭建测试
- 用pip 在macOS 上安装单机使用的pyspark
- What should I set JAVA_HOME to on OSX
- Running pyspark after pip install pyspark
- Getting Streaming data from Kafka with Spark Streaming using Python.
License

本著作由Chang Wei-Yaun (v123582)制作, 以创用CC 姓名标示-相同方式分享 3.0 Unported授权条款释出。
