

关于RabbitMq你必须深入理解的内容
前言
这里主要想整理关于消息队列rabbitmq可能遇到问题,躺一躺其中的坑,然后在团队沉淀下来,最终变为整个团队的技术能力,然后写着写着发现,官方文档写的都比较详细也比较好,所以抽取一些比较有价值的链接和和整理一些实际上遇到的问题和处理心得,所以这里分享出来,设计到的链接可能会相对较多。
这里假设用户已经对rabbitmq有所了解,如果不了解,可以先按照这个方式来测试消息队列,如何使用该消息队列(官方也有完整的示例)。
rabbitmq是一种广泛应用于互联网的消息队列,是一种异步的消息队列,支持多种消息协议,支持多种开发语言,支持多种队列集群化方式cluster和federation,还有完善的授权机制,集群管理和支持各种插件。
一些资料
- 书籍
rabbitmq实战这本书可以作为一种学习消息队列,学习rabbitmq的一种入门书籍,书中介绍了大多数rabbitmq消息队列的相关内容,不过感觉没有官方文档的资料好,和详细(官方文档是真的写的很详细) - 代码解析(淘宝团队在使用的时候做了一些测试和研究)
淘宝代码中文译版 详细的中文翻译文档,对于不熟悉erlang语言会有所帮助
淘宝关于rabbitmq的相关实验 里边有很多经验和分析
认为比较值得看的内容:
- rabbitmq关键参数对性能的影响 可以看到几个核心的参数对吞吐量的影响
- RabbitMQ_Mirror机制分析 可以特别关注, mq GM组播通讯协议,组播模式是rabbitmq镜像队列的实现核心
- Rabbitmq堆积消息后生产速率降低的问题分析及应对措施 这里着重看rabbitmq消息的处理逻辑,从逻辑中可以看出集群维护需要优化点和方向
- rabbitmq流控机制 这里是分析流控流程,能够感知mq的流控具体行为,感觉也算一种网关限流
- 通过流控机制看rabbimq的性能(持久化)瓶颈 这里其实主要是分析rabbitmq的流控造成的队列性能瓶颈
- 官网资料
document-list 这里的文档很很全的,包括
服务端文档
客户端文档
我认为比较重要的几个内容
- 集群配置 里边详细了配置相关的细节
- 客户端工具 各种管理工具
- 访问控制 涉及了各个模块认证和授权管理等
- 网络 介绍了端口,加密,调整tcp参数,内核参数,proxy化等
- 集群管理监控 rabbitmq提供了非常完善的client和web工具,能很容易的接入集群管理,查看集群信息,甚至进行集群状态维护
- 集群 详细介绍了集群搭建,故障,恢复,所有可能遇到的问题
- 镜像队列 同步镜像,分布式系统副本的实现,很有必要了解具体的实现细节,比如对比和mysql master-slave的差别?
- 可靠性 这里介绍了rabbitmq如何解决各种故障问题的场景,包括生产者,消费者,集群模式等
- 生产环境chekclist 下边会有介绍
- 内存使用 消息队列内存使用和内部信息
- 集群镜像同步 这一节内容很重要,设计到分布式系统的集群同步与可用,也有failover
整理
列举几个对集群管理相对重要的:
- rabbitmq-production-check list
链接: checklist
常规来讲有几个重要chekc-list - virtual Host / user Name / password 需要单独给不同服务给不同的vhost, 账户密码,有一种按照服务进行一种资源隔离的思想,然后独立授权,这其实对mq来讲是一种优势,会增加集群吞吐量,具体详情可以看上边关于生产速率的问题。
- 设置能让mq良好运行的限制参数 vm_memory_high_watermark / disk_free_limit
- 设置种种参数, 处理大量连接 large-number-of-connetions,包括了socket文件描述符限制,tcp内核参数调优(这里非常有价值),集群资源控制,cpu, mem, channel等(这对于设计服务端程序也很有帮助)
- 防火墙策略,设置访问策略,开启对集群内部,集群外部需要设置开放的端口访问,关闭非开放端口和ip的访问权限
- 集群分区策略 partitions,这里离非常重要,下边会有一段介绍。
- 集群核心配置文件
链接: configure
整体常规来讲相对重要的参数: - listeners.tcp.default defualt=5672 监听地址
- num_acceptors.tcp default=10 接受tcp监听erlang进程数量(这块就和linux io相关的感觉会比较多)
- vm_memory_high_watermark.relative default=0.4 内存到达一定容量触发流控程序 mem-flow-control
- disk_free_limit default=50M 磁盘free到达一定数量触发流控dis-flow-control|
- channel_max default=2047 连接客户端数量
- cluster_partition_handling default=ignore 分区配置策略,集群化非常重要的参数!! partitions|
一些环境变量配置:
- RABBITMQ_IO_THREAD_POOL_SIZE default=128(linux) mq io线程数量pool-thread|
- RABBITMQ_MNESIA_BASE RABBITMQ_MNESIA_BASE/{NODE} 数据持久化目录
rabbitmq集群可能遇到的问题
场景1 : 在分布式队列中的非镜像队列
- 更新cluster方式集群结构可能导致部分非镜像队列内容丢失(非使用这种Federated这种蓝绿发布方式),集群更新方式是按照clustering集群的进行的。
注意: 这里提到的负载均衡器是4层的负载均衡,使用轮训的方式将请求转发给后端,可以假设为haproxy, lvs
环境:
node: rabbitmq-01, rabbitmq-02, rabbitmq-03
queue: 存在节点为非镜像队列
前端负载均衡器: TCP --> rabbitmq-01/rabbitmq-02/rabbitmq-03
需求:
2个节点需要下架,更换新的节点
rabbitmq-02 ---> rabbitmq-02-new
rabbitmq-03 ---> rabbitmq-03-new
操作:
业务低峰期将rabbitmq-02-new,rabbitmq-03-new join到集群节点,然后删除rabbitmq-01, rabbitmq-02
- 存在问题:
由于更新节点结构,会导致非镜像队列内容丢失,可能部分服务异常。原因是rabbitmq集群模式会在集群的元数据会保存到所有节点上(meta数据),但是非镜像队列的消息内容(持久化或则内存)只会保存到单个节点,客户端连接负载均衡器,然后路由随机转发到后端节点,后端节点再转发到数据节点,然后由于 rabbitmq-02, rabbitmq-03 节点已经下架,所以数据就会丢失的情况。 - 注意点: 对于核心队列需要配置镜像模式(需要考虑节点位置和路由信息,涉及到数据同步的问题,同步会带来性能消耗和资源消耗),当业务部门需要使用消息队列,需要明确消息队列的可靠性,具体使用服务资源,和数据量等相关资源。
- 创建镜像队列多种方式方式
- management UI (UI-->Admin-->Policies)
- rabbitmqctl
- 代码中指定argument创建(rabbitmq3.0后不支持了)
开发人员推荐使用代码中创建(rabbitmq3.0后不支持...3.0后都是create ha) | 这里略坑-- --
queue_args={"x-ha-policy" : "all"}
channel.queue_declare{queue="hello-queue", arguments=queue_args}
场景2 : 在分布式队列中的脑裂处理
脑裂: 脑裂问题是分布式系统中最常见的问题,指在一个高可用(HA)系统中,当联系着的两个节点断开联系时,本来为一个整体的系统,分裂为两个独立节点,这时两个节点开始争抢共享资源,结果会导致系统混乱,数据损坏。对于无状态服务的HA,无所谓脑裂不脑裂;但对有状态服务,数据相关服务(比如MySQL,消息队列)的HA,必须要严格防止脑裂。(但有些生产环境下的系统按照无状态服务HA的那一套去配置有状态服务,结果可想而知...),有一些存储系统像数据库,kv存储都已经有很好的一致性协议解决了raft paxos协议解决了,这里我们需要格外注意这里的脑裂处理流程。
脑裂带来的最大问题就是分区问题,分区在rabbitmq中有三种配置模式ignore(默认方式), pause_minority, autoheal
- ignore: 假设你的集群运行在网络非常可靠的情况,所有的节点都是在相同交换机下,然后交换机在将流量路由到外部。如果任何其他群集发生故障(或者有一个双节点群集,不希望运行任何群集关闭的任何风险。
- pause_minority: 假设你的网络不太可靠,你的节点跨域了通地域多个数据中心,然后数据中心可能会异常,你希望到集群某个中心异常的时候,其他两个数据中心服务继续工作,当数据中心恢复后,节点能自动增加到集群中。就像阿里云的可用区一样。
- autoheal: 假设你的网络可能不可靠,你更关注服务的连续性而不是数据完整性,这个时候可能有一个双节点群集。
这里只测试ignore, pause_minority
- 环境
rabbitmq集群默认是3节点: rabbitmq-01(A), rabbitmq-02(B), rabbitmq-03(C)
环境:
node: rabbitmq-01, rabbitmq-02, rabbitmq-03
queue: 镜像队列
前端负载均衡器: TCP --> rabbitmq-01/rabbitmq-02/rabbitmq-03
2.1 网络分区策略为: 默认模式 ignore
设置C-->B不能互通
- 操作单个节点,设置该节点到其他节点网络异常
iptables -I INPUT -s {NODEX} -j REJECT 这里是代表涉及节点关闭某个ip数据包的流入
然后查看一下集群运行状态,显示已经存在分区partitions
[{nodes,
[{disc,
['rabbit@rabbitmq-test001','rabbit@rabbitmq-test002',
'rabbit@rabbitmq-test003']}]},
{running_nodes,['rabbit@rabbitmq-test003']},
{cluster_name,<<"rabbit@rabbitmq-test001">>},
{partitions,
[{'rabbit@rabbitmq-test003',
['rabbit@rabbitmq-test001','rabbit@rabbitmq-test002']}]},
{alarms,[{'rabbit@rabbitmq-test003',[]}]}]
对应与web上看,相互检测失败,相互显示为not running

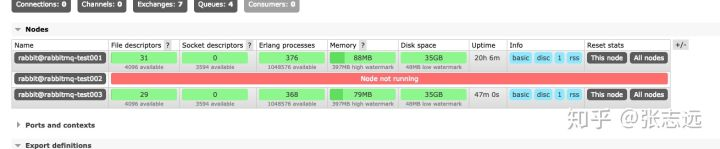
虽然ABC C-->A -->B可以通,都能逻辑互通,局部不互通还是会出现 分区
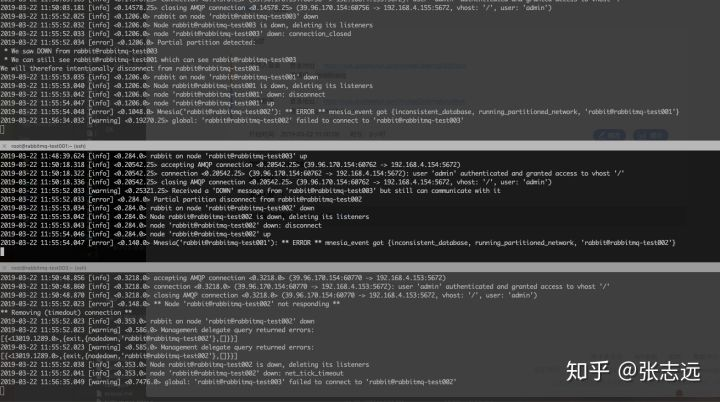
注意点: 这时候非常重要的一点是负载均衡器存在一个较大的隐患,就是ABC互通存在问题,不过负载均衡器能够正常连接到ABC,那么请求还是会按照正常的逻辑走,这里就容易产生数据不一致。(由于rabbitmq没有实现类似raft的分布式协议,所以这一点很重要),这就是rabbitmq集群默认分区方式ignore最大的问题,它不会自动处理,也不会有集群选举的功能,需要我们自身手动去处理集群,去选择信任的分区模式,这里一定要格外注意,稍有差池就会导致集群状态数据异常。
- 节点恢复
后边尽管节点恢复通信,但是由于已经出现了分区,所以还是需要手工处理。 - 重启处理方式:
选择一个你信任的分区,然后重启所有其他分区的节点,然后重新加入节点,注意其他分区节点的数据会被丢掉.
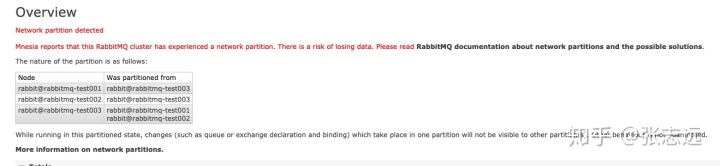
然后重启所有节点恢复警告
- 问题:
默认模式下,会导致脑裂,丢数据,还需要手工处理,对系统可靠性要求较高的场景一定不能使用,同时运维起来会比较麻烦,成本较高,这是系统默认的配置方式,请一定根据自身场景进行配置。
2.2 网络分区策略为: 模式 pause_minority (这也是我们推荐使用的方式)
设置C-->B不能互通
这里不会出现分区,pause_minority
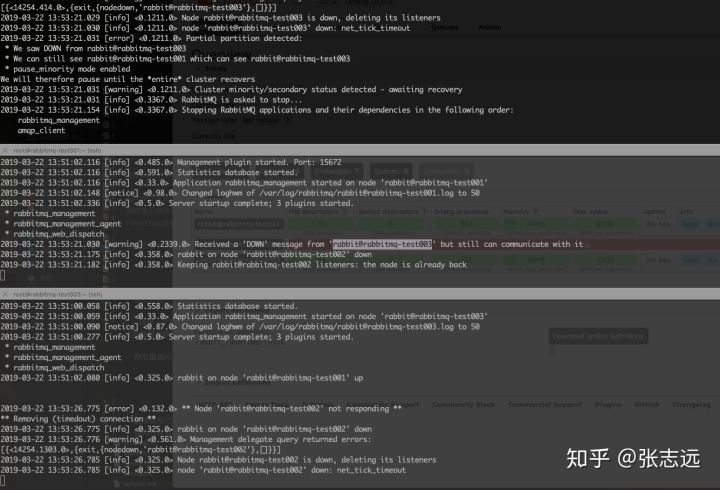
分析:
- 按照这种模式下,集群会选择大多数>1/2节点的区域为分区优胜区域。失败区域会被自动关闭异常端口,异常端口包括15672(web端口), 5672(amqp协议端口), 25672(通信端口)
- erlang发现端口 4369 接口继续工作,不会被down掉,然后当检测到集群网络恢复集群会将异常节点自动加入集群,然后异常节点会自动启动web, amqp, cluster相关端口
- 这个时候需要注意一点,如果对master的数据可靠性较高,需要手工同步,rabbitmq的同步模式sync决定的,模式的模式为ha-sync-mode: manual(详情还是参看sync),,默认不会同步历史中的推挤消息,只会同步新的消息,注意这一点也导致,可能当master异常会导致丢失部分数据
赞: 这时候会有网络分区模式会自动关闭异常节点,负载均衡器也会报警,这样安全级别会较高,当节点<1/2 节点也会正常服务,当重新加入集群然后数据也能正常恢复。
总结:
rabbitmq已经一个使用广泛的消息队列,设计模式相对完善,也在移动互联网中已经被大量应用,可能正式由于这样原因,rabbitmq有太多可配置的功能选项和隐藏配置了,所以考虑了各种各样的适用应用场景,所以如果我们在生产环境使用,需要对它进行一个全方面的学习和掌握,针对自身的环境进行集群配置和集群调优。
其他
列举几条自己用的相对自动的搭建流程吧,搭建3集群rabbitm-server
centos7-64关于一键安装server:
## 安装docker 相关的,主要是为了增加监控使用
sudo yum update -y
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce -y
systemctl start docker
## 安装erlang环境与rabbitmq-server部署
sudo yum install deltarpm -y
wget --content-disposition https://packagecloud.io/rabbitmq/erlang/packages/el/7/erlang-20.0.5-1.el7.centos.x86_64.rpm/download.rpm
sudo yum install -y erlang-20.0.5-1.el7.centos.x86_64.rpm
sudo yum install -y socat
#wget https://dl.bintray.com/rabbitmq/all/rabbitmq-server/3.7.5/rabbitmq-server-3.7.5-1.el7.noarch.rpm
wget download.hyahm.com/rabbitmq-server-3.7.5-1.el7.noarch.rpm
yum install rabbitmq-server-3.7.5-1.el7.noarch.rpm -y
chkconfig rabbitmq-server on
mkdir -p /var/data/rabbitmq && chown rabbitmq:rabbitmq /var/data/rabbitmq && chmod 755 /var/data/rabbitmq
echo 'RABBITMQ_MNESIA_BASE=/var/data/rabbitmq' >> /etc/rabbitmq/rabbitmq-env.conf
echo 'ulimit -S -n 4096' >> /etc/rabbitmq/rabbitmq-env.conf
echo 'cluster_partition_handling=pause_minority' >> /etc/rabbitmq/rabbitmq.conf
## 打开防火墙
iptables -I INPUT -p tcp -s xxxx --dport 25672 -j ACCEPT
iptables -I INPUT -p tcp -s xxx--dport 4369 -j ACCEPT
iptables -I INPUT -p tcp --dport 5672 -j ACCEPT
### 选择需要访问的内网地址
iptables -I INPUT -s 192.168.0.0/16 -j ACCEPT
iptables -I INPUT -s 172.17.0.0/16 -j ACCEPT
集群化:
- 使用同步工具或手工不同文件 /var/lib/rabbitmq/.erlang.cookie
# on rabbit1
rabbitmq-server -detached
# on rabbit2
rabbitmq-server -detached
# on rabbit3
rabbitmq-server -detached
- cluster
# on rabbit1
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit1 ...
# => [{nodes,[{disc,[rabbit@rabbit1]}]},{running_nodes,[rabbit@rabbit1]}]
# => ...done.
# on rabbit2
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit2 ...
# => [{nodes,[{disc,[rabbit@rabbit2]}]},{running_nodes,[rabbit@rabbit2]}]
# => ...done.
# on rabbit3
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit3 ...
# => [{nodes,[{disc,[rabbit@rabbit3]}]},{running_nodes,[rabbit@rabbit3]}]
# => ...done.
- 加入集群
# on rabbit2
rabbitmqctl stop_app
# => Stopping node rabbit@rabbit2 ...done.
rabbitmqctl reset
# => Resetting node rabbit@rabbit2 ...
rabbitmqctl join_cluster rabbit@rabbit1
# => Clustering node rabbit@rabbit2 with [rabbit@rabbit1] ...done.
rabbitmqctl start_app
# => Starting node rabbit@rabbit2 ...done.
- 查看状态
# on rabbit1
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit1 ...
# => [{nodes,[{disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]}]},
# => {running_nodes,[rabbit@rabbit3,rabbit@rabbit2,rabbit@rabbit1]}]
# => ...done.
- user
systemctl start rabbitmq-server
rabbitmq-plugins enable rabbitmq_management
rabbitmqctl add_user admin xxxxxx
rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*"
rabbitmqctl set_user_tags admin administrator
- 监控
docker run -d -e RABBIT_URL=http://{{内网Ip}}:15672 -e RABBIT_CAPABILITIES=bert,no_sort -e RABBIT_USER=admin -e RABBIT_PASSWORD=xxx -e PUBLISH_PORT=9419 -p 9419:9419 kbudde/rabbitmq-exporter
