

使用FastText API分析亚马逊产品评论情绪的分步教程
本博客提供了详细的分步教程,以便使用FastText进行文本分类。为此,我们选择在Amazon.com上对客户评论进行情绪分析,并详细说明如何抓取特定产品的评论以便对他们进行情绪分析。
什么是FastText?
文本分类已成为商业世界的重要组成部分; 是否用于垃圾邮件过滤或分析电子商务网站的推特客户评论的情绪,这可能是最普遍的例子。

FastText是由Facebook AI Research(FAIR)开发的开源库,专门用于简化文本分类。FastText能够在几十分钟内通过多核CPU在数百万个示例文本数据上进行训练,并使用训练模型在不到五分钟的时间内对超过300,000个类别中的未出现的文本进行预测。
预先标注的训练数据集:
收集了从Kaggle.com获得的包含数百万条亚马逊评论的手动注释数据集,并在转换为FastText格式后用于训练模型。
FastText的数据格式如下:
__label__<X> __label__<Y> ... <Text>其中X和Y代表类标签。
在我们使用的数据集中,我们将评论标题添加到评论之前,用“:”和空格分隔。
下面给出了训练数据文件中的示例,可以在Kaggle.com网站上找到用于训练和测试模型的数据集。
__label__2 Great CD: My lovely Pat has one of the GREAT voices of her generation. I have listened to this CD for YEARS and I still LOVE IT. When I'm in a good mood it makes me feel better. A bad mood just evaporates like sugar in the rain. This CD just oozes LIFE. Vocals are jusat STUUNNING and lyrics just kill. One of life's hidden gems. This is a desert isle CD in my book. Why she never made it big is just beyond me. Everytime I play this, no matter black, white, young, old, male, female EVERYBODY says one thing "Who was that singing ?"在这里,我们只有两个类1和2,其中__label__1表示评论者为产品打1或2星,而__label__2表示4或5星评级。
训练FastText进行文本分类:
预处理和清洗数据:
在规范化文本案例并删除不需要的字符后,执行以下命令以生成预处理和清洗的训练数据文件。
cat <path to training file> | sed -e “s/\([.\!?,’/()]\)/ \1 /g” | tr “[:upper:]” “[:lower:]” > <path to pre-processed output file>设置FastText:
让我们从下载最新版本开始:
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ make不带任何参数运行二进制文件将打印高级文档,显示fastText支持的不同用例:
>> ./fasttext
usage: fasttext <command> <args>
The commands supported by fasttext are:
supervised train a supervised classifier
quantize quantize a model to reduce the memory usage
test evaluate a supervised classifier
predict predict most likely labels
predict-prob predict most likely labels with probabilities
skipgram train a skipgram model
cbow train a cbow model
print-word-vectors print word vectors given a trained model
print-sentence-vectors print sentence vectors given a trained model
nn query for nearest neighbors
analogies query for analogies在本教程中,我们主要使用了supervised,test和predict子命令,对应于学习(和使用)的文本分类。
训练模型:
以下命令用于训练文本分类模型:
./fasttext supervised -input <path to pre-processed training file> -output <path to save model> -label __label__ 该-input命令行选项指的是训练文件,而-output选项指的是该模型要保存的位置。训练完成后,将在给定位置创建包含训练分类器的文件model.bin。
用于改进模型的可选参数:
增加训练迭代次数:
默认情况下,模型在每个示例上迭代5次,为了更好的训练增加此参数,我们可以指定-epoch参数。
示例:
./fasttext supervised -input <path to pre-processed training file> -output <path to save model> -label __label__ -epoch 50指定学习率:
改变学习率意味着改变我们模型的学习速度,是增加(或降低)算法的学习率。这对应于处理每个示例后模型更改的程度。学习率为0意味着模型根本不会改变,因此不会学到任何东西。良好的学习率值在该范围内0.1 - 1.0。
lr的默认值为0.1。这里是如何指定此参数。
./fasttext supervised -input <path to pre-processed training file> -output <path to save model> -label __label__ -lr 0.5使用n-gram作为特征:
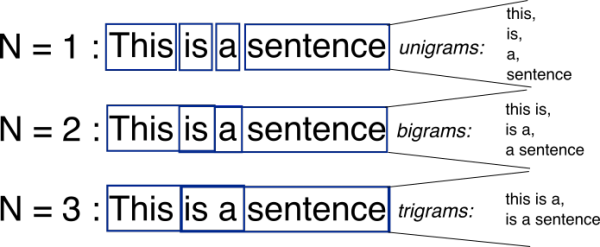
对于依赖于词序,特别是情感分析的问题,这是一个有用的步骤。它是指定连续token在n的窗口内的词都作为特征来训练。
我们指定-wordNgrams参数(理想情况下,值介于2到5之间):
./fasttext supervised -input <path to pre-processed training file> -output <path to save model> -label __label__ -wordNgrams 3测试和评估模型:
以下命令用于在预先注释的测试数据集上测试模型,并将原始标签与每个评论的预测标签进行比较,并以准确率和召回率的形式生成评估分数。
精度是fastText预测的标签中正确标签的数量。召回是成功预测的标签数量。
./fasttext test <path to model> <path to test file> k其中参数k表示模型用于预测每个评论的前k个标签。
在400000评论的测试数据上评估我们训练的模型所获得的结果如下。如所观察到的,精确度,召回率为91%,并且模型在很短的时间内得到训练。
N 400000
P@1 0.913
R@1 0.913
Number of examples: 400000分析在Amazon.com上产品的实时客户评价的情绪:

抓取亚马逊客户评论:
我们使用现有的python库来从页面中抓取评论。
要安装,请在命令提示符/终端中键入:
pip install amazon-review-scraper以下是给定网址网页的示例代码,用于抓取特定产品的评论:
from amazon_review_scraper import amazon_review_scraper
url = input("Enter URL: ")
start_page = input("Enter Start Page: ")
end_page = input("Enter End Page: ")
time_upper_limit = input("Enter upper limit of time range (Example: Entering the value 5 would mean the program will wait anywhere from 0 to 5 seconds before scraping a page. If you don't want the program to wait, enter 0): ")
file_name = "amazon_product_review"
scraper = amazon_review_scraper.amazon_review_scraper(url, start_page, end_page, time_upper_limit)
scraper.scrape()
scraper.write_csv(file_name)注意:在输入特定产品的客户审核页面的URL时,请确保附加&pageNumber = 1(如果它不存在),以使scraper正常运行。
上面的代码从给定的URL中抓取了评论,并按以下格式创建了输出csv文件:
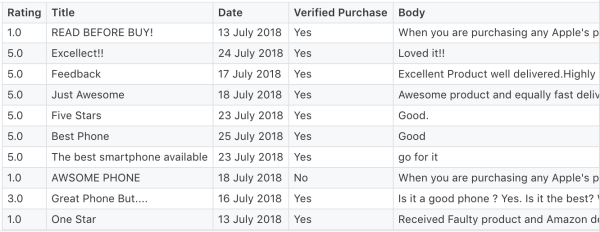
从上面的csv文件中,我们提取标题和正文并将它们一起追加到一起,用训练文件中的':和空格分隔,并将它们存储在一个单独的txt文件中以预测情绪。
数据的情绪预测:
./fasttext predict <path to model> <path to test file> k > <path to prediction file>其中k表示模型将预测每个评论的前k个标签。
上述评论预测的标签如下:
__label__2
__label__1
__label__2
__label__2
__label__2
__label__2
__label__2
__label__2
__label__1
__label__2
__label__2这是相当准确的,可手动验证。预测文件随后可用于进一步的详细分析和可视化目的。
因此,在本博客中,我们学习了使用FastText API进行文本分类,抓取给定产品的亚马逊客户评论,并使用经过培训的分析模型预测他们的情绪。
更多文章欢迎访问: http://www.apexyun.com
公众号:银河系1号
联系邮箱:public@space-explore.com
(未经同意,请勿转载)
